Artificial neural networks are big business these days. If you’ve been on Twitter recently, or voted in the last election, chances are your data was processed by one. They are now being used in sectors ranging from marketing and medicine to autonomous vehicles and energy harvesting.
Yet despite their ubiquity, many regard neural networks as controversial. Inspired by the structure of neurons in the brain, they are “black boxes” in the sense that, because their training processes and their capabilities are poorly understood, it can be difficult to keep track of what they’re doing under the hood. And if we don’t know how they achieve their results, how can we be sure that we can trust them? A second issue arises because, as neural networks become more commonplace, they are run on smaller devices. As a result, power consumption can be a limiting factor in their performance.
However, help is at hand. Physicists working at Aston University in Birmingham and the London Institute for Mathematical Sciences have published a study that addresses both of these problems.
Neural networks are built to carry out a variety of tasks including automated decision-making. When designing one, you first feed it manageable amounts of information, so that you can train the network by gradually improving the results obtained. For example, an autonomous vehicle needs to differentiate correctly between different types of traffic signs. If it makes the right decision a hundred times, you might then trust the design of the network to go it alone and do its work on another thousand signs, or a million more.
The controversy stems from the lack of control you have over the training process and the resulting network once it’s up and running. It’s a bit like the predicament described in E.M. Forster’s sci-fi short story The Machine Stops . There, the human race has created “the Machine” to govern their affairs, only to find it has developed a will of its own. While the concerns over neural networks aren’t quite so dystopian, they do possess a worrying autonomy and variability in performance. If you train them on too few test cases relative to the number of free parameters inside, neural networks can give the illusion of making good decisions, a problem known as overfitting.
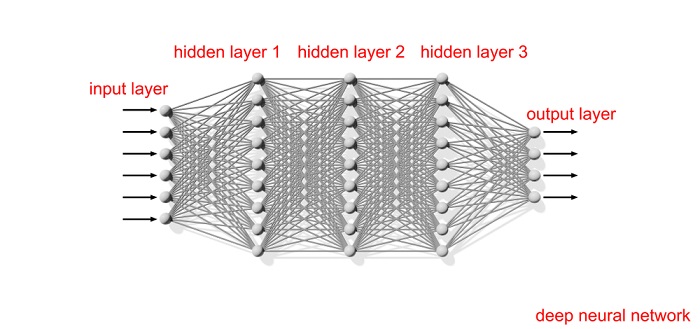
Neural networks are so-called because they are inspired by computation in the brain. The brain processes information by passing electric signals through a series of neuron cells linked together by synapses. In a similar way, neural networks are a collection of nodes arranged in a series of layers through which a signal navigates. These layers are connected by edges, which are assigned weights. An input signal is then iteratively transformed by these weights as it works its way through successive layers of the network. The way that the weights are distributed in each layer determines the overall task which is computed, and hence the output that emerges in the final layer.
The study, to be published in the journal Physical Review Letters, looked at two main types of neural networks: recurrent and layer-dependent. Recurrent neural networks can be viewed as a multilayered system where the weighted edges in each layer are identical. In layer-dependent neural networks, each layer has a different distribution of weights. The former set- up is by far the simpler of the two, because there are fewer weights to specify, meaning the network is cheaper to train.
One might expect that inherently different structures would produce radically different outputs. Instead, the team found that the opposite was true. The set of functions that the networks computed were identical. According to Bo Li, one of the co-authors, the result astonished him. “At the beginning, I didn’t believe that this could be true. There had to be a difference.”
The authors were able to draw this unexpected conclusion because they took a pencil-and-paper approach to what is usually thought of as a computational problem. Testing how each network deals with an individual input, for all possible inputs, would have been impossible. There are far too many different combinations to consider. Instead, the authors devised a mathematical expression that considers the path that the signal takes through the network for all possible inputs simultaneously, along with their corresponding outputs.
Crucially, the study suggests that there is no benefit to the extra complexity in terms of the variety of the functions that the network can compute. This has both theoretical and practical implications.
With fewer free parameters recurrent neural networks are less prone to overfitting. They require less information to specify the smaller number of weights, meaning that it’s easier to keep track of what they’re computing. As co-author David Saad says, “mistakes can be painful” in the industries that these networks are being used for, so this paves the way for a better understanding of ANN capabilities.
The simpler networks also require less power. “In simpler networks there are fewer parameters and fewer parameters, which means less resources,” explains Alexander Mozeika, one of the co-authors. “So if I were an engineer, I would try to use our insights to build networks that run on smaller chips or use less energy.”
While the results of the study are encouraging, they also give cause for concern. Even the simple presumption that networks constructed in different ways should do different things seems to have been misguided. Why does this matter? Because neural networks are now being used to diagnose diseases, detect threats and inform political decisions. Given the stakes of these applications, it’s vital that the capabilities of neural networks, and more importantly their limitations, are properly appreciated.
About the Author

Pippa Cole is the science writer at the London Institute for Mathematical Sciences, where study co-author Mozeika is based. As a result, she has been able to interview all three authors of the paper mentioned above. She has a PhD in Cosmology from the University of Sussex and has written previously for the blog Astrobites.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind