
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Machine Knowledge: Creation and Curation of Comprehensive Knowledge Bases

Equipping machines with comprehensive knowledge of the world’s entities and their relationships has been a long-standing goal of AI. Over the last decade, large-scale knowledge bases, also known as knowledge graphs, have been automatically constructed from web contents and text sources, and have become a key asset for search engines. This machine knowledge can be harnessed to semantically interpret textual phrases in news, social media and web tables, and contributes to question answering, natural language processing and data analytics. This 261 page paper surveys fundamental concepts and practical methods for creating and curating large knowledge bases. It covers models and methods for discovering and canonicalizing entities and their semantic types and organizing them into clean taxonomies. On top of this, the article discusses the automatic extraction of entity-centric properties. To support the long-term life-cycle and the quality assurance of machine knowledge, the article presents methods for constructing open schemas and for knowledge curation. Case studies on academic projects and industrial knowledge graphs complement the survey of concepts and methods.
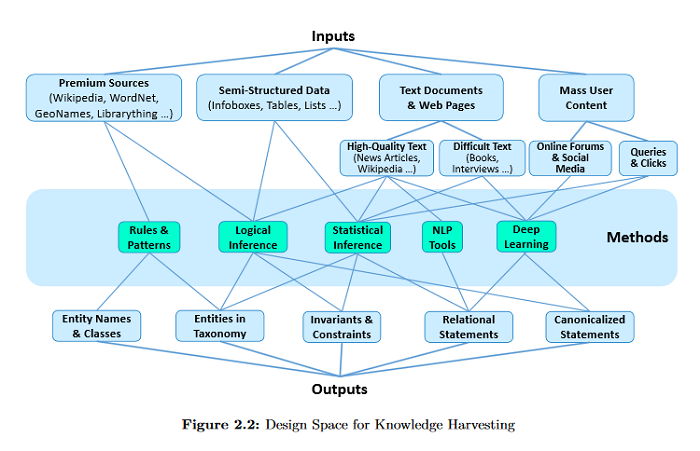
Breaking the Memory Wall for AI Chip with a NewDimension
Recent advancements in deep learning have led to the widespread adoption of artificial intelligence (AI) in applications such as computer vision and natural language processing. As neural networks become deeper and larger, AI modeling demands outstrip the capabilities of conventional chip architectures. Memory bandwidth falls behind processing power. Energy consumption comes to dominate the total cost of ownership. Currently, memory capacity is insufficient to support the most advanced NLP models. This paper presents a 3D AI chip, called Sunrise, with near-memory computing architecture to address these three challenges. This distributed, near-memory computing architecture allows us to tear down the performance-limiting memory wall with an abundance of data bandwidth. The same level of energy efficiency is achieved on 40nm technology as competing chips on 7nm technology. By moving to similar technologies as other AI chips, we project to achieve more than ten times the energy efficiency, seven times the performance of the current state-of-the-art chips, and twenty times of memory capacity as compared with the best chip in each benchmark.
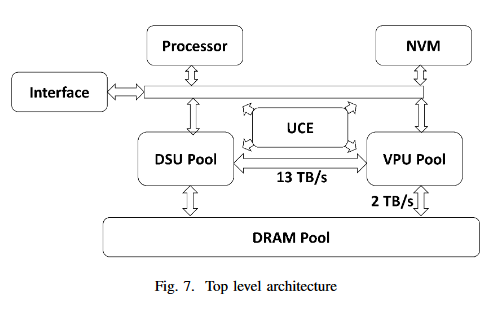
Causal Intervention for Weakly-Supervised Semantic Segmentation
This paperpresents a causal inference framework to improve Weakly-Supervised Semantic Segmentation (WSSS). Specifically, the aim is to generate better pixel-level pseudo-masks by using only image-level labels – the most crucial step in WSSS. The researchers attribute the cause of the ambiguous boundaries of pseudo-masks to the confounding context, e.g., the correct image-level classification of “horse” and “person” may be not only due to the recognition of each instance, but also their co-occurrence context, making the model inspection (e.g., CAM) hard to distinguish between the boundaries. Inspired by this, it is proposed a structural causal model to analyze the causalities among images, contexts, and class labels. Based on it, a new method was developed: Context Adjustment (CONTA), to remove the confounding bias in image-level classification and thus provide better pseudo-masks as ground-truth for the subsequent segmentation model. On PASCAL VOC 2012 and MS-COCO, it is shown that CONTA boosts various popular WSSS methods to new state-of-the-arts.
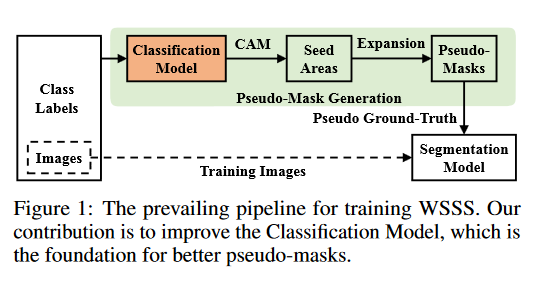
This paper proposes Parametric UMAP, a parametric variation of the UMAP (Uniform Manifold Approximation and Projection) algorithm. UMAP is a non-parametric graph-based dimensionality reduction algorithm using applied Riemannian geometry and algebraic topology to find low-dimensional embeddings of structured data. The UMAP algorithm consists of two steps: (1) Compute a graphical representation of a data set (fuzzy simplicial complex), and (2) Through stochastic gradient descent, optimize a low-dimensional embedding of the graph. Here, the second step of UMAP is replaced with a deep neural network that learns a parametric relationship between data and embedding. It is demonstrated that the method performs similarly to its non-parametric counterpart while conferring the benefit of a learned parametric mapping (e.g. fast online embeddings for new data). It is then shown that UMAP loss can be extended to arbitrary deep learning applications, for example constraining the latent distribution of autoencoders, and improving classifier accuracy for semi-supervised learning by capturing structure in unlabeled data. The code associated with the paper is available HERE.
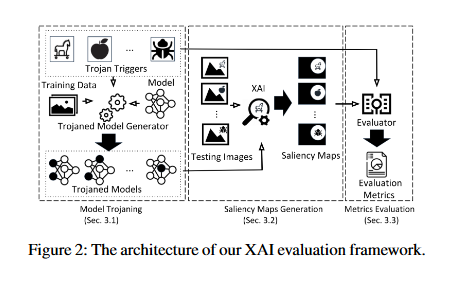
EXplainable AI (XAI) methods have been proposed to interpret how a deep neural network predicts inputs through model saliency explanations that highlight the parts of the inputs deemed important to arrive a decision at a specific target. However, it remains challenging to quantify correctness of their interpretability as current evaluation approaches either require subjective input from humans or incur high computation cost with automated evaluation. This paper proposes backdoor trigger patterns–hidden malicious functionalities that cause misclassification–to automate the evaluation of saliency explanations. The key observation is that triggers provide ground truth for inputs to evaluate whether the regions identified by an XAI method are truly relevant to its output. Since backdoor triggers are the most important features that cause deliberate misclassification, a robust XAI method should reveal their presence at inference time. Three complementary metrics are introduced for systematic evaluation of explanations that an XAI method generates and evaluate seven state-of-the-art model-free and model-specific posthoc methods through 36 models trojaned with specifically crafted triggers using color, shape, texture, location, and size.
Lifelong Learning Dialogue Systems: Chatbots that Self-Learn On the Job
Dialogue systems, also called chatbots, are now used in a wide range of applications. However, they still have some major weaknesses. One key weakness is that they are typically trained from manually-labeled data and/or written with handcrafted rules, and their knowledge bases (KBs) are also compiled by human experts. Due to the huge amount of manual effort involved, they are difficult to scale and also tend to produce many errors ought to their limited ability to understand natural language and the limited knowledge in their KBs. Thus, the level of user satisfactory is often low. This paper proposes to dramatically improve this situation by endowing the system the ability to continually learn (1) new world knowledge, (2) new language expressions to ground them to actions, and (3) new conversational skills, during conversation or “on the job” by themselves so that as the systems chat more and more with users, they become more and more knowledgeable and are better and better able to understand diverse natural language expressions and improve their conversational skills. A key approach to achieving these is to exploit the multi-user environment of such systems to self-learn through interactions with users via verb and non-verb means. The paper discusses not only key challenges and promising directions to learn from users during conversation but also how to ensure the correctness of the learned knowledge.
Phishing Detection Using Machine LearningTechniques
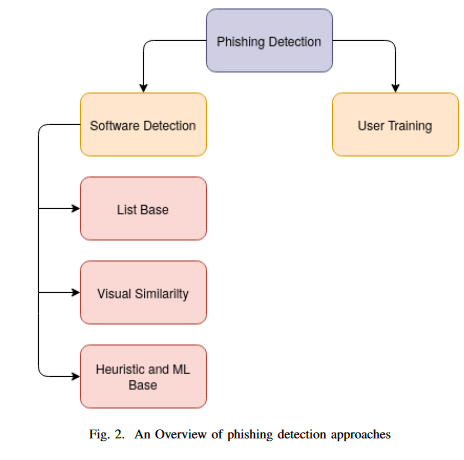
The Internet has become an indispensable part of our life, However, It also has provided opportunities to anonymously perform malicious activities like Phishing. Phishers try to deceive their victims by social engineering or creating mock-up websites to steal information such as account ID, username, password from individuals and organizations. Although many methods have been proposed to detect phishing websites, Phishers have evolved their methods to escape from these detection methods. One of the most successful methods for detecting these malicious activities is Machine Learning. This is because most Phishing attacks have some common characteristics which can be identified by machine learning methods. This paper compares the results of multiple machine learning methods for predicting phishing websites.
PennSyn2Real: Training Object Recognition Models without Human Labeling
Scalability is a critical problem in generating training images for deep learning models. This paper proposes PennSyn2Real – a photo-realistic synthetic data set with more than 100, 000 4K images of more than 20 types of micro aerial vehicles (MAV) that can be used to generate an arbitrary number of training images for MAV detection and classification. The data generation framework bootstraps chroma-keying, a matured cinematography technique with a motion tracking system, providing artifact-free and curated annotated images where object orientations and lighting are controlled. This framework is easy to set up and can be applied to a broad range of objects, reducing the gap between synthetic and real-world data. The paper demonstrates that CNNs trained on the synthetic data have on par performance with those trained on real-world data in both semantic segmentation and object detection setups.

Sign up for the free insideBIGDATA newsletter.



Speak Your Mind