
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
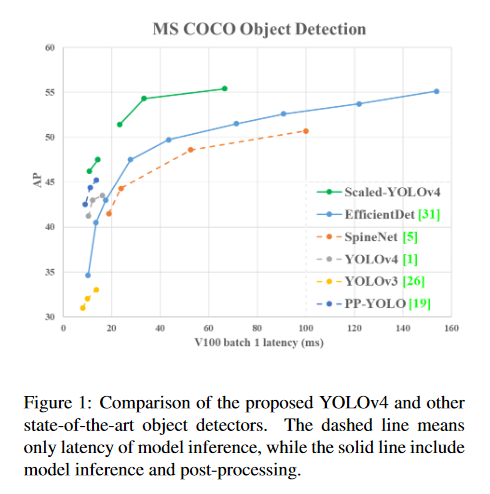
Scaled-YOLOv4: Scaling Cross Stage Partial Network
This paper shows that the YOLOv4 object detection neural network based on the CSP approach, scales both up and down and is applicable to small and large networks while maintaining optimal speed and accuracy. It is proposed a network scaling approach that modifies not only the depth, width, resolution, but also structure of the network. YOLOv4-large model achieves state-of-the-art results: 55.4% AP (73.3% AP50) for the MS COCO data set at a speed of 15 FPS on Tesla V100, while with the test time augmentation, YOLOv4-large achieves 55.8% AP (73.2 AP50). To the best of our knowledge, this is currently the highest accuracy on the COCO data set among any published work. The YOLOv4-tiny model achieves 22.0% AP (42.0% AP50) at a speed of 443 FPS on RTX 2080Ti, while by using TensorRT, batch size = 4 and FP16-precision the YOLOv4-tiny achieves 1774 FPS. The cod associated with this paper can be found HERE.
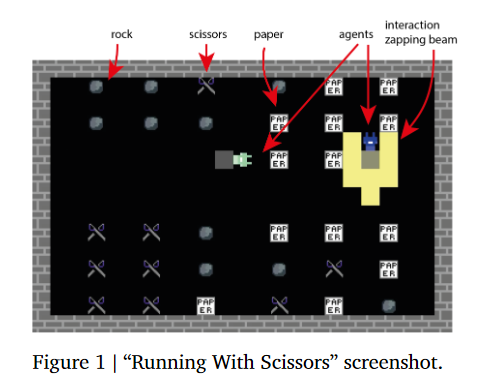
This paper presents DeepMind Lab2D, a scalable environment simulator for artificial intelligence research that facilitates researcher-led experimentation with environment design. DeepMind Lab2D was built with the specific needs of multi-agent deep reinforcement learning researchers in mind, but it may also be useful beyond that particular subfield. The code associated with this paper can be found HERE.
CompressAI: a PyTorch library and evaluation platform for end-to-end compression research
This paper presents CompressAI, a platform that provides custom operations, layers, models and tools to research, develop and evaluate end-to-end image and video compression codecs. In particular, CompressAI includes pre-trained models and evaluation tools to compare learned methods with traditional codecs. Multiple models from the state-of-the-art on learned end-to-end compression have thus been reimplemented in PyTorch and trained from scratch. The paper also reports objective comparison results using PSNR and MS-SSIM metrics vs. bit-rate, using the Kodak image data set as test set. Although this framework currently implements models for still-picture compression, it is intended to be soon extended to the video compression domain.

Two Stage Transformer Model for COVID-19 Fake News Detection andFact Checking
The rapid advancement of technology in online communication via social media platforms has led to a prolific rise in the spread of misinformation and fake news. Fake news is especially rampant in the current COVID-19 pandemic, leading to people believing in false and potentially harmful claims and stories. Detecting fake news quickly can alleviate the spread of panic, chaos and potential health hazards. This paper describes the development of a two stage automated pipeline for COVID-19 fake news detection using state of the art machine learning models for natural language processing. The first model leverages a novel fact checking algorithm that retrieves the most relevant facts concerning user claims about particular COVID-19 claims. The second model verifies the level of truth in the claim by computing the textual entailment between the claim and the true facts retrieved from a manually curated COVID-19 data set. The data set is based on a publicly available knowledge source consisting of more than 5000 COVID-19 false claims and verified explanations, a subset of which was internally annotated and cross-validated to train and evaluate our models. A series of models are developed based on classical text-based features to more contextual Transformer based models and observe that a model pipeline based on BERT and ALBERT for the two stages respectively yields the best results.

Analyzing the Machine Learning Conference Review Process
Mainstream machine learning conferences have seen a dramatic increase in the number of participants, along with a growing range of perspectives, in recent years. Members of the machine learning community are likely to overhear allegations ranging from randomness of acceptance decisions to institutional bias. This paper critically analyzes the review process through a comprehensive study of papers submitted to ICLR between 2017 and 2020. The paper quantifies reproducibility/randomness in review scores and acceptance decisions, and examine whether scores correlate with paper impact. The findings suggest strong institutional bias in accept/reject decisions, even after controlling for paper quality. Furthermore, evidence is found for a gender gap, with female authors receiving lower scores, lower acceptance rates, and fewer citations per paper than their male counterparts. The paper concludes with recommendations for future conference organizers.
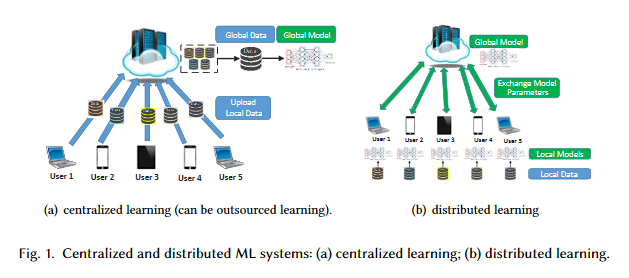
When Machine Learning Meets Privacy: A Survey and Outlook

The newly emerged machine learning (e.g. deep learning) methods have become a strong driving force to revolutionize a wide range of industries, such as smart healthcare, financial technology, and surveillance systems. Meanwhile, privacy has emerged as a big concern in this machine learning-based artificial intelligence era. It is important to note that the problem of privacy preservation in the context of machine learning is quite different from that in traditional data privacy protection, as machine learning can act as both friend and foe. Currently, the work on the preservation of privacy and machine learning (ML) is still in an infancy stage, as most existing solutions only focus on privacy problems during the machine learning process. Therefore, a comprehensive study on the privacy preservation problems and machine learning is required. This paper surveys the state of the art in privacy issues and solutions for machine learning. The survey covers three categories of interactions between privacy and machine learning: (i) private machine learning, (ii) machine learning aided privacy protection, and (iii) machine learning-based privacy attack and corresponding protection schemes. The current research progress in each category is reviewed and the key challenges are identified. Finally, based on in-depth analysis of the area of privacy and machine learning, the paper points out future research directions in this field.
On the Convergence of Reinforcement Learning
This paper considers the problem of Reinforcement Learning for nonlinear stochastic dynamical systems. It’s shown that in the RL setting, there is an inherent “Curse of Variance” in addition to Bellman’s infamous “Curse of Dimensionality”, in particular, it’s shown that the variance in the solution grows factorial-exponentially in the order of the approximation. A fundamental consequence is that this precludes the search for anything other than “local” feedback solutions in RL, in order to control the explosive variance growth, and thus, ensure accuracy. It’s further shown that the deterministic optimal control has a perturbation structure, in that the higher order terms do not affect the calculation of lower order terms, which can be utilized in RL to get accurate local solutions.

Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind