
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
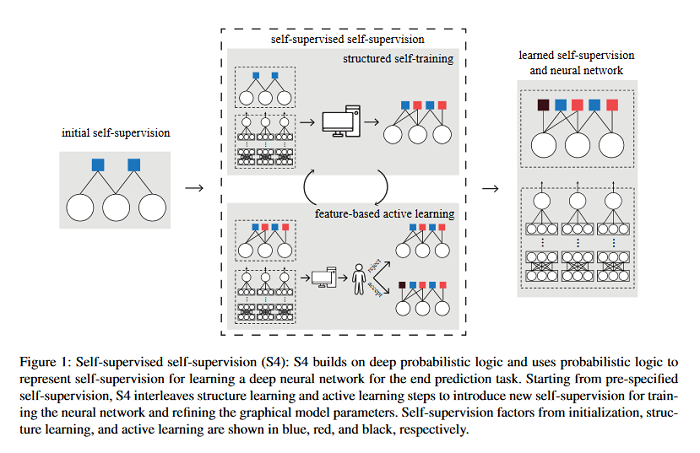
Self-supervised self-supervision by combining deep learning and probabilistic logic

Labeling training examples at scale is a perennial challenge in machine learning. Self-supervision methods compensate for the lack of direct supervision by leveraging prior knowledge to automatically generate noisy labeled examples. Deep probabilistic logic (DPL) is a unifying framework for self-supervised learning that represents unknown labels as latent variables and incorporates diverse self-supervision using probabilistic logic to train a deep neural network end-to-end using variational EM. While DPL is successful at combining pre-specified self-supervision, manually crafting self-supervision to attain high accuracy may still be tedious and challenging. This paper proposes Self-Supervised Self-Supervision (S4), which adds to DPL the capability to learn new self-supervision automatically. Starting from an initial “seed,” S4 iteratively uses the deep neural network to propose new self supervision. These are either added directly (a form of structured self-training) or verified by a human expert (as in feature-based active learning). Experiments show that S4 is able to automatically propose accurate self-supervision and can often nearly match the accuracy of supervised methods with a tiny fraction of the human effort.
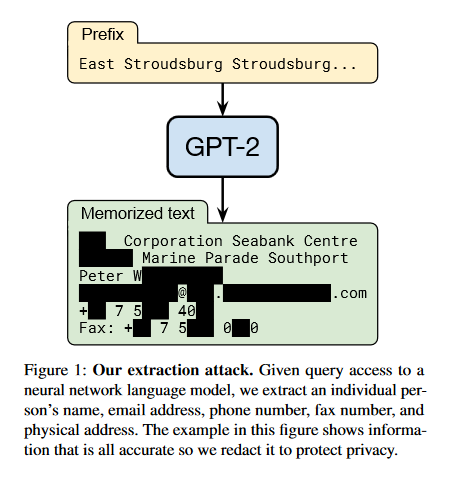
Extracting Training Data from Large Language Models
It has become common to publish large (billion parameter) language models that have been trained on private data sets. This paper demonstrates that in such settings, an adversary can perform a training data extraction attack to recover individual training examples by querying the language model. The team of researchers demonstrate an attack on GPT-2, a language model trained on scrapes of the public Internet, and are able to extract hundreds of verbatim text sequences from the model’s training data. These extracted examples include (public) personally identifiable information (names, phone numbers, and email addresses), IRC conversations, code, and 128-bit UUIDs. Our attack is possible even though each of the above sequences are included in just one document in the training data. The team comprehensively evaluates the extraction attack to understand the factors that contribute to its success. For example, it’s found that larger models are more vulnerable than smaller models. The paper concludes by drawing lessons and discussing possible safeguards for training large language models.
Analyzing Representations inside Convolutional Neural Networks
How can we discover and succinctly summarize the concepts that a neural network has learned? Such a task is of great importance in applications of networks in areas of inference that involve classification, like medical diagnosis based on fMRI/x-ray etc. This paper proposes a framework to categorize the concepts a network learns based on the way it clusters a set of input examples, clusters neurons based on the examples they activate for, and input features all in the same latent space. This framework is unsupervised and can work without any labels for input features, it only needs access to internal activations of the network for each input example, thereby making it widely applicable. The proposed method is evaluated extensively and demonstrates that it produces human-understandable and coherent concepts that a ResNet-18 has learned on the CIFAR-100 data set.
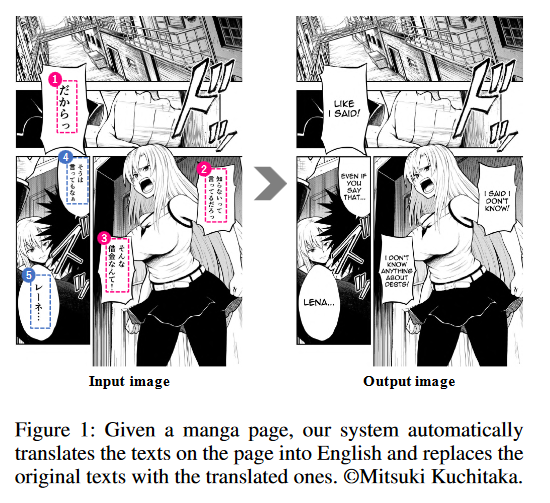
Towards Fully Automated Manga Translation
This paper tackles the problem of machine translation of manga, Japanese comics. Manga translation involves two important problems in machine translation: context-aware and multimodal translation. Since text and images are mixed up in an unstructured fashion in Manga, obtaining context from the image is essential for manga translation. However, it is still an open problem how to extract context from image and integrate into MT models. In addition, corpus and benchmarks to train and evaluate such model is currently unavailable. This paper makes four contributions that establishes the foundation of manga translation research.
My Teacher Thinks The World Is Flat! Interpreting Automatic Essay Scoring Mechanism
Significant progress has been made in deep-learning based Automatic Essay Scoring (AES) systems in the past two decades. However, little research has been put to understand and interpret the black-box nature of these deep-learning based scoring models. Recent work shows that automated scoring systems are prone to even common-sense adversarial samples. Their lack of natural language understanding capability raises questions on the models being actively used by millions of candidates for life-changing decisions. With scoring being a highly multi-modal task, it becomes imperative for scoring models to be validated and tested on all these modalities. This paper utilizes recent advances in interpretability to find the extent to which features such as coherence, content and relevance are important for automated scoring mechanisms and why they are susceptible to adversarial samples. It’s found that the systems tested consider essays not as a piece of prose having the characteristics of natural flow of speech and grammatical structure, but as `word-soups’ where a few words are much more important than the other words. Removing the context surrounding those few important words causes the prose to lose the flow of speech and grammar, however has little impact on the predicted score. It’s also found that since the models are not semantically grounded with world-knowledge and common sense, adding false facts such as “the world is flat” actually increases the score instead of decreasing it.

On Generating Extended Summaries of Long Documents
Prior work in document summarization has mainly focused on generating short summaries of a document. While this type of summary helps get a high-level view of a given document, it is desirable in some cases to know more detailed information about its salient points that can’t fit in a short summary. This is typically the case for longer documents such as a research paper, legal document, or a book. This paper presents a new method for generating extended summaries of long papers. The method exploits hierarchical structure of the documents and incorporates it into an extractive summarization model through a multi-task learning approach. The results are presented on three long summarization data sets, arXiv-Long, PubMed-Long, and Longsumm. The method outperforms or matches the performance of strong baselines. The data sets, and codes are publicly available HERE.
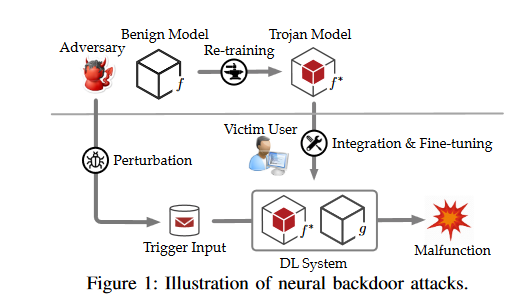
TROJANZOO: Everything you ever wanted to know about neural backdoors (but were afraid to ask)
Neural backdoors represent one primary threat to the security of deep learning systems. The intensive research on this subject has produced a plethora of attacks/defenses, resulting in a constant arms race. However, due to the lack of evaluation benchmarks, many critical questions remain largely unexplored: (i) How effective, evasive, or transferable are different attacks? (ii) How robust, utility-preserving, or generic are different defenses? (iii) How do various factors (e.g., model architectures) impact their performance? (iv) What are the best practices (e.g., optimization strategies) to operate such attacks/defenses? (v) How can the existing attacks/defenses be further improved? To bridge the gap, this paper describes the design and implementation of TROJANZOO, the first open-source platform for evaluating neural backdoor attacks/defenses in a unified, holistic, and practical manner.
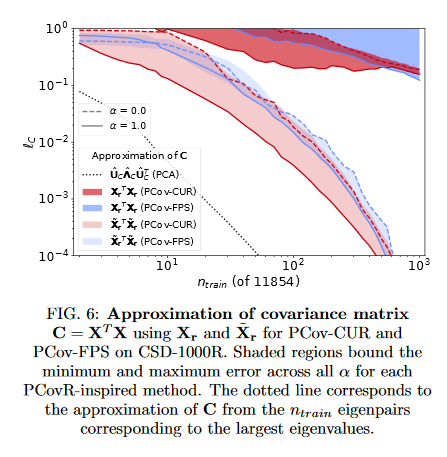
Improving Sample and Feature Selection with Principal Covariates Regression
Selecting the most relevant features and samples out of a large set of candidates is a task that occurs very often in the context of automated data analysis, where it can be used to improve the computational performance, and also often the transferability, of a model. This paper focuses on two popular sub-selection schemes which have been applied to this end: CUR decomposition, that is based on a low-rank approximation of the feature matrix and Farthest Point Sampling, that relies on the iterative identification of the most diverse samples and discriminating features. These unsupervised approaches are modified, incorporating a supervised component following the same spirit as the Principal Covariates Regression (PCovR) method. It’s shown that incorporating target information provides selections that perform better in supervised tasks, demonstrated with ridge regression, kernel ridge regression, and sparse kernel regression. It’s also shown that incorporating aspects of simple supervised learning models can improve the accuracy of more complex models, such as feed-forward neural networks.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind