
In this special guest feature, Henrik Skogström, Head of Growth at Valohai, discusses how MLOps (machine learning operations) is becoming increasingly relevant as it is the next step in scaling and accelerating the development of machine learning capabilities. At Valohai, Henrik spearheads the Valohai MLOps platform’s adoption and writes extensively about the best practices around machine learning in production. Before Valohai, Henrik worked as a product manager at Quest Analytics to improve healthcare accessibility in the US. Launched in 2017, Valohai is a pioneer in MLOps and has helped companies such as Twitter, LEGO Group, and JFrog get their models to production quicker.
If you are actively participating in developing products with machine learning features, the chances are you’ve heard about MLOps in the past year. Machine learning is quickly maturing as a discipline in companies of all sizes, and machine learning models in production use are no longer exclusive to a select few technology leaders. In early 2020, we surveyed 330 data scientists, machine learning engineers, and managers about their goals for the next three months. Over 40% of the respondents were preparing to release production models within that period.
With this trend, MLOps (machine learning operations) is becoming increasingly relevant as it is the next step in scaling and accelerating the development of machine learning capabilities. The definition of MLOps is not yet crystal clear, but the practice aims to systematize and automate how machine learning models are trained, deployed, and monitored. There’s a strong agreement in the machine learning community that MLOps is a set of shared practices rather than a single technology or platform – but as with most practices, technology selections have a significant impact on the concrete implementation.
For a more concrete look at how MLOps looks like in practice, let’s drill into two crucial components: version control and the machine learning pipeline.
Version control has been a standard practice for software development for a long time, but the same cannot be said for ML practice. While in software development, the key artifact to store is the code; in machine learning, practitioners also need to version the data, parameters, metadata, and finally, the model. To retain the full reproducibility of any production model requires entirely new solutions for version control.
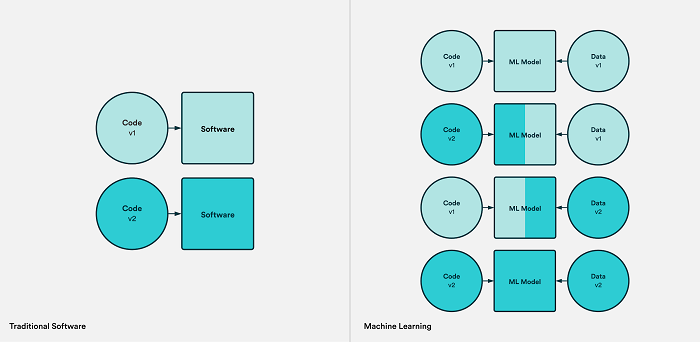
This complexity is illustrated by the fact that when you have several datasets and several versions of the code, the possible end-results multiply.
The second crucial component is the machine learning pipeline. Machine learning is often approached from a perspective where the ML model is the product. While the model is arguably the most important artifact, it shouldn’t be the product as it is only temporary. Machine learning models degrade over time as the underlying data changes, which requires models to be retrained again and again.
The machine learning pipeline should encapsulate everything that the organization has learned about building models, including how data should be transformed and tested and how predictions should look. MLOps encourages that tacit knowledge and manual processes get translated to code inside the pipeline to ensure that every production model is trained in the same way and adheres to a set of standards.
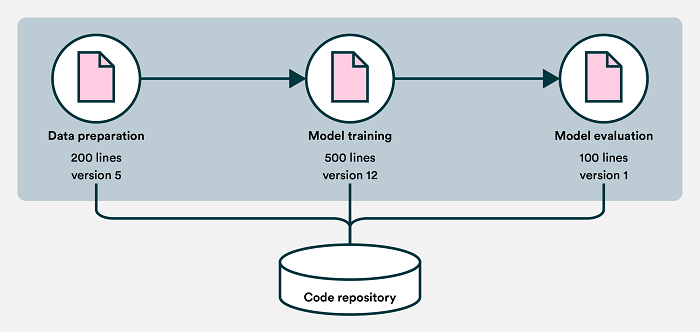
When considering the pipeline as the product, the work can be shared, reviewed, reused, and iterated within the whole extended organization and development can scale with people unlike before. Additionally, a pipeline may free up significant resources for future development as manual actions get mostly automated.
Version control and the machine learning pipeline are by no means the only core components in MLOps but the components that organizations most early on identify as missing in their workflow. Machine learning in production requires a shared understanding of how machine learning systems should be built, and with MLOps, the industry is taking leaps towards common best practices.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Machine learning will increase rapidly in the upcoming years. Many industries, like healthcare and e-commerce, will use it. You have stated the points precisely, especially when the machine learning model will need a constant upgrade as data sets will frequently be changing. Please keep providing such useful content.