
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
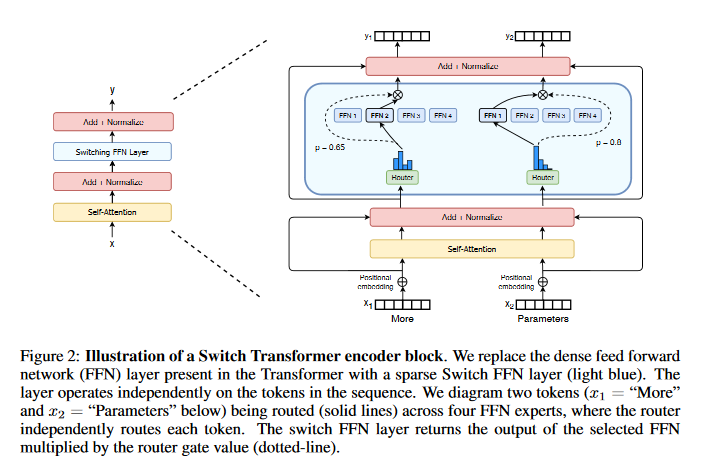
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model — with outrageous numbers of parameters — but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability — this paper addresses these with the Switch Transformer. The Google Brain researchers simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. The proposed training techniques help wrangle the instabilities and it is shown that large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. They design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings to measure gains over the mT5-Base version across all 101 languages. Finally, the paper advances the current scale of language models by pre-training up to trillion parameter models on the “Colossal Clean Crawled Corpus” and achieve a 4x speedup over the T5-XXL model. The PyTorch code associated with this paper can be found HERE.
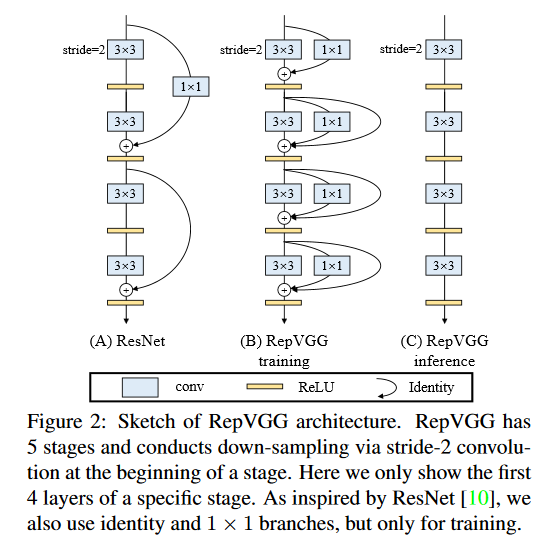
RepVGG: Making VGG-style ConvNets Great Again
VGG-style ConvNets, although now considered a classic architecture, were attractive due to their simplicity. In contrast, ResNets have become popular due to their high accuracy but are more difficult to customize and display undesired inference drawbacks. To address these issues, Ding et al. propose RepVGG – the return of the VGG!
RepVGG is an efficient and simple architecture using plain VGG-style ConvNets. It decouples the inference-time and training-time architecture through a structural re-parameterization technique. The researchers report favorable speed-accuracy tradeoff compared to state-of-the-art models, such as EfficientNet and RegNet. RepVGG achieves 80% top-1 accuracy on ImageNet and is benchmarked as being 83% faster than ResNet-50. This research is part of a broader effort to build more efficient models using simpler architectures and operations. The PyTorch code associated with this paper can be found HERE.
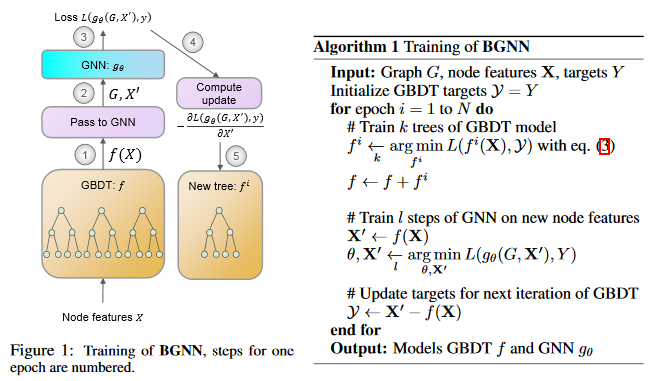
Boost then Convolve: Gradient Boosting Meets Graph Neural Networks

Graph neural networks (GNNs) are powerful models that have been successful in various graph representation learning tasks. Whereas gradient boosted decision trees (GBDT) often outperform other machine learning methods when faced with heterogeneous tabular data. But what approach should be used for graphs with tabular node features? Previous GNN models have mostly focused on networks with homogeneous sparse features and are suboptimal in the heterogeneous setting. This paper proposes a novel architecture that trains GBDT and GNN jointly to get the best of both worlds: the GBDT model deals with heterogeneous features, while GNN accounts for the graph structure. The model benefits from end-to-end optimization by allowing new trees to fit the gradient updates of GNN. With an extensive experimental comparison to the leading GBDT and GNN models, the researchers demonstrate a significant increase in performance on a variety of graphs with tabular features. The code associated with this paper can be found HERE.
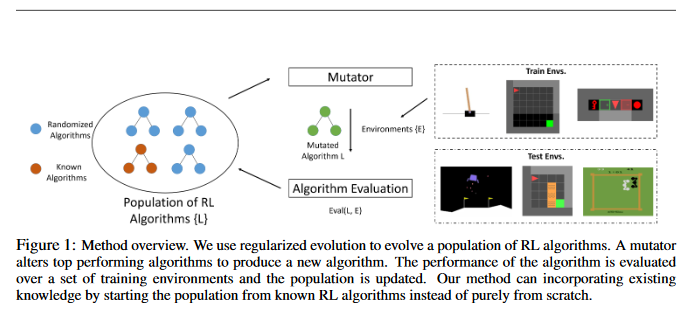
Evolving Reinforcement Learning Algorithms
This paper proposes a method for meta-learning reinforcement learning algorithms by searching over the space of computational graphs which compute the loss function for a value-based model-free RL agent to optimize. The learned algorithms are domain-agnostic and can generalize to new environments not seen during training. The method can both learn from scratch and bootstrap off known existing algorithms, like DQN, enabling interpretable modifications which improve performance. Learning from scratch on simple classical control and gridworld tasks, the method rediscovers the temporal-difference (TD) algorithm. Bootstrapped from DQN, two learned algorithms are highlighted which obtain good generalization performance over other classical control tasks, gridworld type tasks, and Atari games. The analysis of the learned algorithm behavior shows resemblance to recently proposed RL algorithms that address overestimation in value-based methods.
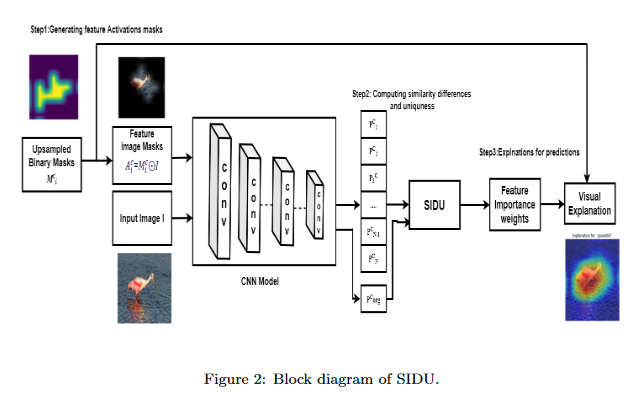
Introducing and assessing the explainable AI (XAI)method: SIDU
Explainable Artificial Intelligence (XAI) has in recent years become a well-suited framework to generate human understandable explanations of black box models. This paper presents a novel XAI visual explanation algorithm denoted SIDU that can effectively localize entire object regions responsible for prediction in a full extend. The paper analyzes its robustness and effectiveness through various computational and human subject experiments. In particular, the SIDU algorithm is assessed using three different types of evaluations (Application, Human and Functionally-Grounded) to demonstrate its superior performance. The robustness of SIDU is further studied in presence of adversarial attack on black box models to better understand its performance.
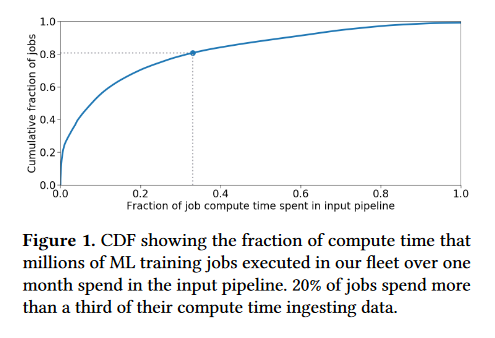
tf.data: A Machine Learning Data Processing Framework
Training machine learning models requires feeding input data for models to ingest. Input pipelines for machine learning jobs are often challenging to implement efficiently as they require reading large volumes of data, applying complex transformations, and transferring data to hardware accelerators while overlapping computation and communication to achieve optimal performance. This paper presents tf.data, a framework for building and executing efficient input pipelines for machine learning jobs. The tf.data API provides operators which can be parameterized with user-defined computation, composed, and reused across different machine learning domains. These abstractions allow users to focus on the application logic of data processing, while tf.data’s runtime ensures that pipelines run efficiently. The paper demonstrates that input pipeline performance is critical to the end-to-end training time of state-of-the-art machine learning models. tf.data delivers the high performance required, while avoiding the need for manual tuning of performance knobs.
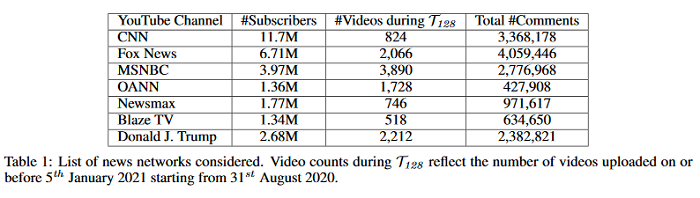
Fringe News Networks: Dynamics of US News Viewership following the 2020 Presidential Election
The growing political polarization of the American electorate over the last several decades has been widely studied and documented. During the administration of President Donald Trump, charges of “fake news” made social and news media not only the means but, to an unprecedented extent, the topic of political communication. Using data from before the November 3rd, 2020 US Presidential election, recent work has demonstrated the viability of using YouTube’s social media ecosystem to obtain insights into the extent of US political polarization as well as the relationship between this polarization and the nature of the content and commentary provided by different US news networks. With that work as background, this paper looks at the sharp transformation of the relationship between news consumers and here-to-fore “fringe” news media channels in the 64 days between the US presidential election and the violence that took place at US Capitol on January 6th. This paper makes two distinct types of contributions. The first is to introduce a novel methodology to analyze large social media data to study the dynamics of social political news networks and their viewers. The second is to provide insights into what actually happened regarding US political social media channels and their viewerships during this volatile 64 day period.
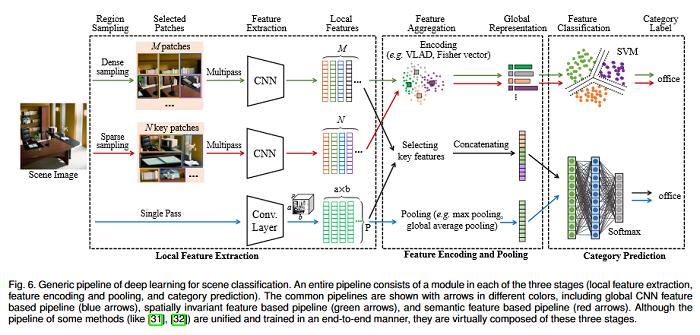
Deep Learning for Scene Classification: A Survey
Scene classification, aiming at classifying a scene image to one of the predefined scene categories by comprehending the entire image, is a longstanding, fundamental and challenging problem in computer vision. The rise of large-scale datasets, which constitute a dense sampling of diverse real-world scenes, and the renaissance of deep learning techniques, which learn powerful feature representations directly from big raw data, have been bringing remarkable progress in the field of scene representation and classification. To help researchers master needed advances in this field, the goal of this paper is to provide a comprehensive survey of recent achievements in scene classification using deep learning. More than 260 major publications are included in this survey covering different aspects of scene classification, including challenges, benchmark datasets, taxonomy, and quantitative performance comparisons of the reviewed methods. In retrospect of what has been achieved so far, this paper is concluded with a list of promising research opportunities.
Explainable Artificial Intelligence Approaches: A Survey
The lack of explainability of a decision from an Artificial Intelligence (AI) based “black box” system/model, despite its superiority in many real-world applications, is a key stumbling block for adopting AI in many high stakes applications of different domain or industry. While many popular Explainable Artificial Intelligence (XAI) methods or approaches are available to facilitate a human-friendly explanation of the decision, each has its own merits and demerits, with a plethora of open challenges. This paper demonstrates popular XAI methods with a mutual case study/task (i.e., credit default prediction), analyze for competitive advantages from multiple perspectives (e.g., local, global), provide meaningful insight on quantifying explainability, and recommend paths towards responsible or human-centered AI using XAI as a medium. Practitioners can use this work as a catalog to understand, compare, and correlate competitive advantages of popular XAI methods. In addition, this survey elicits future research directions towards responsible or human-centric AI systems, which is crucial to adopt AI in high stakes applications.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind