
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
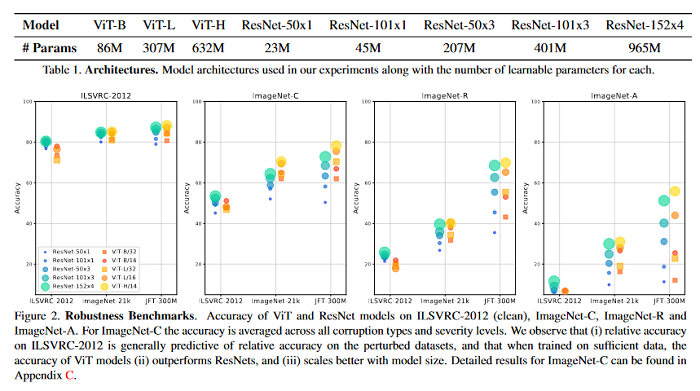
Understanding Robustness of Transformers for Image Classification

Deep Convolutional Neural Networks (CNNs) have long been the architecture of choice for computer vision tasks. Recently, Transformer-based architectures like Vision Transformer (ViT) have matched or even surpassed ResNets for image classification. However, details of the Transformer architecture — such as the use of non-overlapping patches — lead one to wonder whether these networks are as robust. This paper performs an extensive study of a variety of different measures of robustness of ViT models and compare the findings to ResNet baselines. Investigated is robustness to input perturbations as well as robustness to model perturbations. The paper finds that when pre-trained with a sufficient amount of data, ViT models are at least as robust as the ResNet counterparts on a broad range of perturbations. Also found is that Transformers are robust to the removal of almost any single layer, and that while activations from later layers are highly correlated with each other, they nevertheless play an important role in classification.
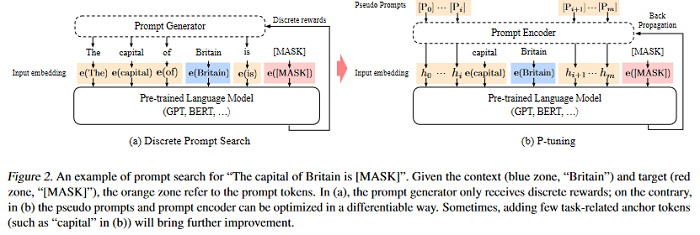
While GPTs with traditional fine-tuning fail to achieve strong results on natural language understanding (NLU), this paper shows that GPTs can be better than or comparable to similar-sized BERTs on NLU tasks with a novel method P-tuning — which employs trainable continuous prompt embeddings. On the knowledge probing (LAMA) benchmark, the best GPT recovers 64% (P@1) of world knowledge without any additional text provided during test time, which substantially improves the previous best by 20+ percentage points. On the SuperGlue benchmark, GPTs achieve comparable and sometimes better performance to similar-sized BERTs in supervised learning. Importantly, it is found that P-tuning also improves BERTs’ performance in both few-shot and supervised settings while largely reducing the need for prompt engineering. Consequently, P-tuning outperforms the state-of-the-art approaches on the few-shot SuperGlue benchmark.
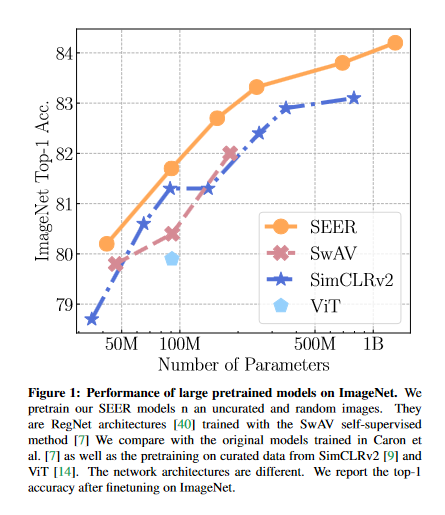
Self-supervised Pretraining of Visual Features in the Wild
Recently, self-supervised learning methods like MoCo, SimCLR, BYOL and SwAV have reduced the gap with supervised methods. These results have been achieved in a control environment, that is the highly curated ImageNet dataset. However, the premise of self-supervised learning is that it can learn from any random image and from any unbounded dataset. This work explores if self-supervision lives to its expectation by training large models on random, uncurated images with no supervision. The final SElf-supERvised (SEER) model, a RegNetY with 1.3B parameters trained on 1B random images with 512 GPUs achieves 84.2% top-1 accuracy, surpassing the best self-supervised pretrained model by 1% and confirming that self-supervised learning works in a real world setting. Interestingly, it is also observed that self-supervised models are good few-shot learners achieving 77.9% top-1 with access to only 10% of ImageNet. Code associated with this paper can be found HERE.
How to decay your learning rate
Complex learning rate schedules have become an integral part of deep learning. This research finds empirically that common fine-tuned schedules decay the learning rate after the weight norm bounces. This leads to the proposal of ABEL: an automatic scheduler which decays the learning rate by keeping track of the weight norm. ABEL’s performance matches that of tuned schedules and is more robust with respect to its parameters. Through extensive experiments in vision, NLP, and RL, it is shown that if the weight norm does not bounce, it is possible to simplify schedules even further with no loss in performance. In such cases, a complex schedule has similar performance to a constant learning rate with a decay at the end of training.

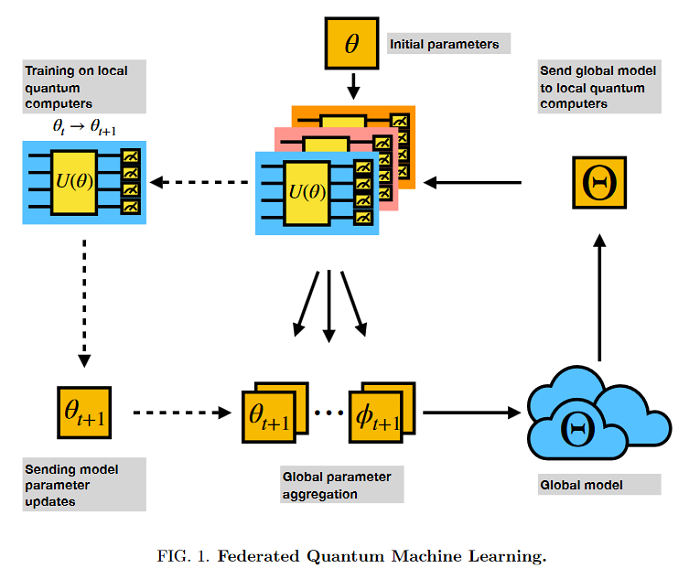
Federated Quantum Machine Learning
Distributed training across several quantum computers could significantly improve the training time and if we could share the learned model, not the data, it could potentially improve the data privacy as the training would happen where the data is located. It is believed that no work has been done in quantum machine learning (QML) in federation setting yet. This paper presents the federated training on hybrid quantum-classical machine learning models although the framework could be generalized to pure quantum machine learning model. Specifically, it was considered the quantum neural network (QNN) coupled with classical pre-trained convolutional model. The distributed federated learning scheme demonstrated almost the same level of trained model accuracies and yet significantly faster distributed training. It demonstrates a promising future research direction for scaling and privacy aspects.
A Survey of Quantization Methods for Efficient Neural Network Inference
As soon as abstract mathematical computations were adapted to computation on digital computers, the problem of efficient representation, manipulation, and communication of the numerical values in those computations arose. Strongly related to the problem of numerical representation is the problem of quantization: in what manner should a set of continuous real-valued numbers be distributed over a fixed discrete set of numbers to minimize the number of bits required and also to maximize the accuracy of the attendant computations? This perennial problem of quantization is particularly relevant whenever memory and/or computational resources are severely restricted, and it has come to the forefront in recent years due to the remarkable performance of Neural Network models in computer vision, natural language processing, and related areas. Moving from floating-point representations to low-precision fixed integer values represented in four bits or less holds the potential to reduce the memory footprint and latency by a factor of 16x; and, in fact, reductions of 4x to 8x are often realized in practice in these applications. Thus, it is not surprising that quantization has emerged recently as an important and very active sub-area of research in the efficient implementation of computations associated with Neural Networks. This paper surveys approaches to the problem of quantizing the numerical values in deep Neural Network computations, covering the advantages/disadvantages of current methods.

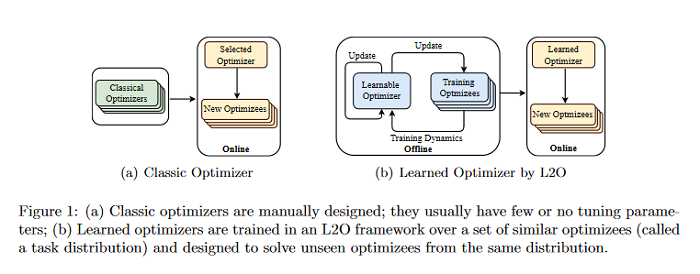
Learning to Optimize: A Primer and A Benchmark
Learning to optimize (L2O) is an emerging approach that leverages machine learning to develop optimization methods, aiming at reducing the laborious iterations of hand engineering. It automates the design of an optimization method based on its performance on a set of training problems. This data-driven procedure generates methods that can efficiently solve problems similar to those in the training. In sharp contrast, the typical and traditional designs of optimization methods are theory-driven, so they obtain performance guarantees over the classes of problems specified by the theory. The difference makes L2O suitable for repeatedly solving a certain type of optimization problems over a specific distribution of data, while it typically fails on out-of-distribution problems. The practicality of L2O depends on the type of target optimization, the chosen architecture of the method to learn, and the training procedure. This new paradigm has motivated a community of researchers to explore L2O and report their findings. This paper is poised to be the first comprehensive survey and benchmark of L2O for continuous optimization. The code associated with this paper can be found HERE.
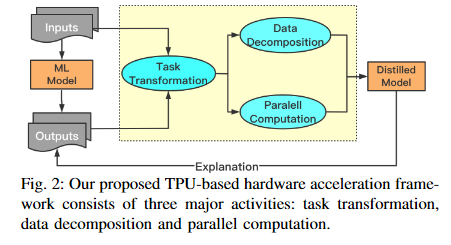
Hardware Acceleration of Explainable Machine Learning using Tensor Processing Units
Machine learning (ML) is successful in achieving human-level performance in various fields. However, it lacks the ability to explain an outcome due to its black-box nature. While existing explainable ML is promising, almost all of these methods focus on formatting interpretability as an optimization problem. Such a mapping leads to numerous iterations of time-consuming complex computations, which limits their applicability in real-time applications. In this paper, we propose a novel framework for accelerating explainable ML using Tensor Processing Units (TPUs). The proposed framework exploits the synergy between matrix convolution and Fourier transform, and takes full advantage of TPU’s natural ability in accelerating matrix computations. Specifically, this paper makes three important contributions. (1) To the best of the author’s knowledge, the proposed work is the first attempt in enabling hardware acceleration of explainable ML using TPUs. (2) The proposed approach is applicable across a wide variety of ML algorithms, and effective utilization of TPU-based acceleration can lead to real-time outcome interpretation. (3) Extensive experimental results demonstrate that the proposed approach can provide an order-of-magnitude speedup in both classification time (25x on average) and interpretation time (13x on average) compared to state-of-the-art techniques.
A Survey on Predicting the Factuality and the Bias of News Media
The present level of proliferation of fake, biased, and propagandistic content online has made it impossible to fact-check every single suspicious claim or article, either manually or automatically. Thus, many researchers are shifting their attention to higher granularity, aiming to profile entire news outlets, which makes it possible to detect likely “fake news” the moment it is published, by simply checking the reliability of its source. Source factuality is also an important element of systems for automatic fact-checking and “fake news” detection, as they need to assess the reliability of the evidence they retrieve online. Political bias detection, which in the Western political landscape is about predicting left-center-right bias, is an equally important topic, which has experienced a similar shift towards profiling entire news outlets. Moreover, there is a clear connection between the two, as highly biased media are less likely to be factual; yet, the two problems have been addressed separately. This survey reviews the state of the art on media profiling for factuality and bias, arguing for the need to model them jointly.
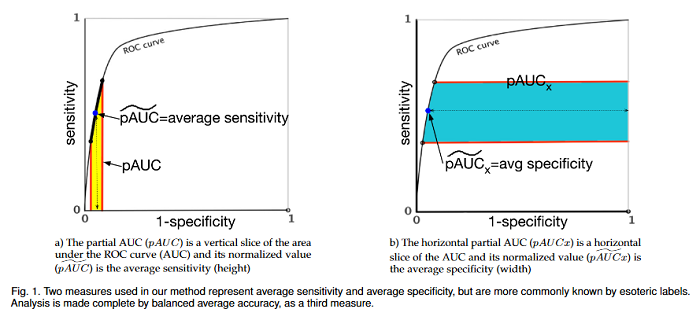
Optimal performance is critical for decision-making tasks from medicine to autonomous driving, however common performance measures may be too general or too specific. For binary classifiers, diagnostic tests or prognosis at a timepoint, measures such as the area under the receiver operating characteristic curve, or the area under the precision recall curve, are too general because they include unrealistic decision thresholds. On the other hand, measures such as accuracy, sensitivity or the F1 score are measures at a single threshold that reflect an individual single probability or predicted risk, rather than a range of individuals or risk. This paper proposes a method in between, deep ROC analysis, that examines groups of probabilities or predicted risks for more insightful analysis. The research translates esoteric measures into familiar terms: AUC and the normalized concordant partial AUC are balanced average accuracy (a new finding); the normalized partial AUC is average sensitivity; and the normalized horizontal partial AUC is average specificity.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind