
Insights-rich but regulated or sensitive data is sitting in private data stores unleveraged and unmonetized by enterprises. In 2018, Gartner reported that nearly 97 percent of data sits unused by organizations. There are solutions available today that enable enterprises to share data and collaborate, but they are either cumbersome, slow, ineffective or dangerous – which is why the rate of data sharing remains so low. There are new solutions available that do allow enterprises to gain insights from enterprise data and address the weaknesses of current solutions, while concurrently enforcing regulatory standards such as HIPAA and GDPR, as well as data residency requirements in some regions, such as Southeast Asia, China and the Middle East.
Here are a few scenarios in which effective data collaboration would be beneficial.
Financial Fraud
On average, people own 5.3 accounts across different financial institutions. A person might have a checking and savings account with Wells Fargo, a credit card with Citibank and a mortgage with Chase. If Citibank detects potential fraud on the person’s credit card, there is currently little or no ability for Citibank’s fraud department to collaborate with Wells Fargo and Chase to get a comprehensive picture of the fraud – which would enable Citibank’s security team to identify and thwart the activity.
Healthcare
Approximately 1.2 billion clinical documents, such as patient records, are produced in the United States each year, comprising approximately 60% of all clinical data with each paper providing medical experts with a wealth of potentially life-saving insights and data. However, within any one healthcare system, these records are skewed by the demographics of the patients – in some parts of the country the skew might be toward older, whiter patients, in other part, younger, Hispanic patients. When these institutions develop algorithms to create diagnoses, they are impaired by this skewed data. Today, the solution is to physically ship anonymized data from other healthcare systems to create accurate algorithms, a long, slow and expensive process.
Airline Predictive Maintenance
Aircrafts supply chains are a trade secret for parts suppliers making current predictive models less accurate than they could be. Partnerships of various manufacturers are notoriously complex and often serve as a barrier in sharing data. But suppose they can privately run predictive models on the aircraft data and determine the remaining useful life of their aircrafts and parts without ever having access to the raw data sets. In that case, this can set a new precedent for the industry. The manufacturer networks will be able to share information from airlines they don’t have direct relationships with, all in compliance with local laws and protecting their intellectual property.
How One New, Breakthrough Solution Works
One new, breakthrough solution enables enterprises to gain insights from data without ever decrypting it. The process starts by privately aggregating data from multiple sources, such as different financial institutions or healthcare systems. It privately explores, selects and pre-processes relevant features for training, and then privately processes the encrypted data.
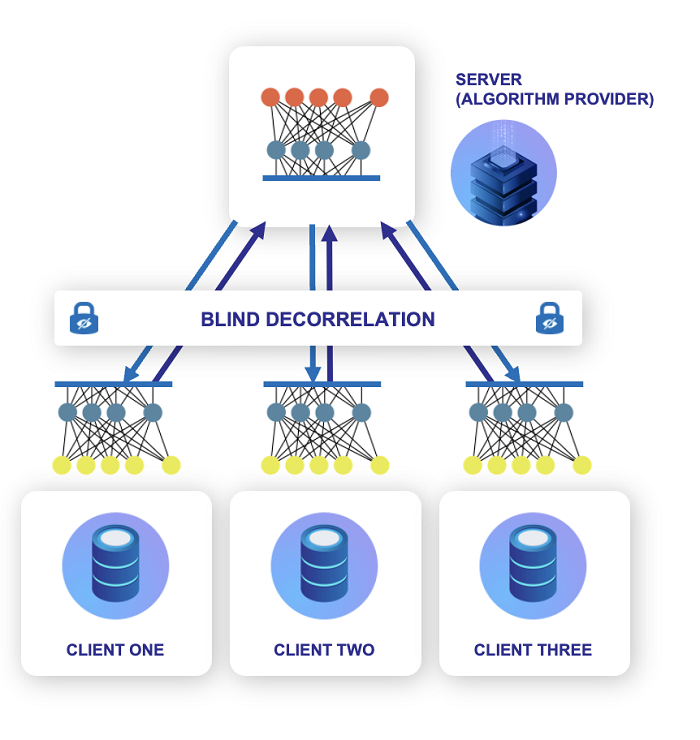
It then trains new, deep statistical models and then predicts on any private and sensitive data.
The training process features low compute requirements and low communication overhead.
Along with encrypted data, this new approach encrypts the algorithm. The algorithm is blind to the data fed through it and the data is blind to the algorithm executed upon it. And neither the data nor the algorithm is exposed to the solution itself – it is a triple blind answer to gain insights from sensitive data.
By incorporating algorithmic encryption, neither party can reverse engineer the algorithms and the algorithms cannot abuse the data. And, neither party can re-generate any of the original training dataset for neural networks
Compared to other approaches like homomorphic encryption or secure enclaves, this enterprise data privacy approach enables “digital rights” to the data – the ability to overlay rules on how the data may be used. This ensures that any regulation or other terms that govern the use of the data, can be baked into the digital rights management contract. This blind pipeline offers the highest privacy and security, lowest computational load, and the lowest communication overhead, with no one ever seeing the entire model. With a suite of tools that allows for even the most sensitive information to be shared among competitors, the use cases with this technology are endless. Being blind to all data and algorithms brings in the most visible results – ensuring that the data becomes “liquid” and can be used broadly.

About the Author

Riddhiman Das is the co-founder and CEO of TripleBlind, arming organizations with the ability to share, leverage and monetize regulated data, helping decision makers generate new revenue for their organizations by collaborating more effectively with customers, partners and even competitors, without compromising safety.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind