
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
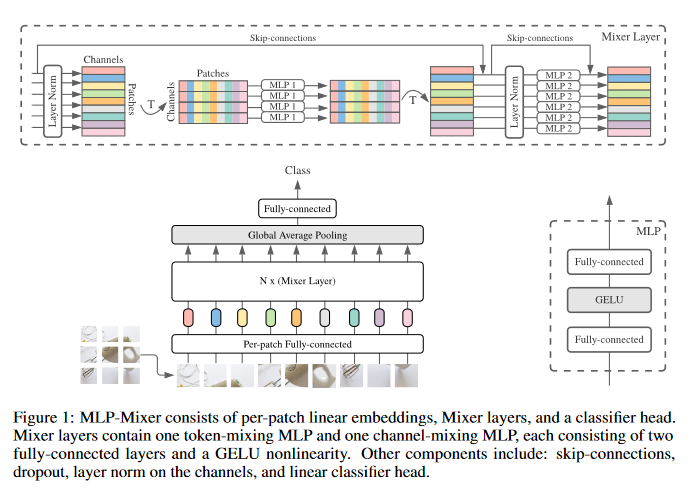
MLP-Mixer: An all-MLP Architecture for Vision
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. This paper shows that while convolutions and attention are both sufficient for good performance, neither of them are necessary. Presented is MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. “mixing” the per-location features), and one with MLPs applied across patches (i.e. “mixing” spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models.
Diffusion Models Beat GANs on Image Synthesis
This paper shows that diffusion models can achieve image sample quality superior to the current state-of-the-art generative models. This is achieved with unconditional image synthesis by finding a better architecture through a series of ablations. For conditional image synthesis, we further improve sample quality with classifier guidance: a simple, compute-efficient method for trading off diversity for fidelity using gradients from a classifier. Achieved is an FID of 2.97 on ImageNet 128128, 4.59 on ImageNet 256256, and 7.72 on ImageNet 512512, and BigGAN-deep is matched even with as few as 25 forward passes per sample, all while maintaining better coverage of the distribution. Finally, it is found that classifier guidance combines well with upsampling diffusion models, further improving FID to 3.94 on ImageNet 256256 and 3.85 on ImageNet 512512. The code associated with this paper can be found HERE.

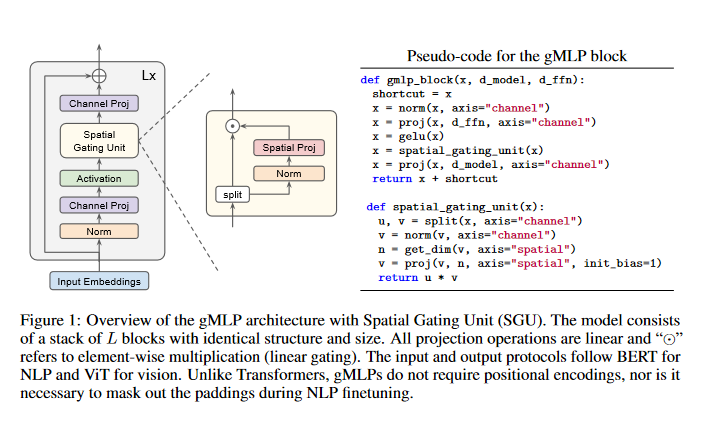
Transformers have become one of the most important architectural innovations in deep learning and have enabled many breakthroughs over the past few years. This paper proposes a simple network architecture, gMLP, based on MLPs with gating, and show that it can perform as well as Transformers in key language and vision applications. The comparisons show that self-attention is not critical for Vision Transformers, as gMLP can achieve the same accuracy. For BERT, the proposed model achieves parity with Transformers on pretraining perplexity and is better on some downstream NLP tasks. On finetuning tasks where gMLP performs worse, making the gMLP model substantially larger can close the gap with Transformers. In general, the experiments show that gMLP can scale as well as Transformers over increased data and compute.
Measuring Coding Challenge Competence With APPS

While programming is one of the most broadly applicable skills in modern society, modern machine learning models still cannot code solutions to basic problems. Despite its importance, there has been surprisingly little work on evaluating code generation, and it can be difficult to accurately assess code generation performance rigorously. To meet this challenge, this paper introduces APPS, a benchmark for code generation. Unlike prior work in more restricted settings, this benchmark measures the ability of models to take an arbitrary natural language specification and generate satisfactory Python code. Similar to how companies assess candidate software developers, the proposed solution then evaluates models by checking their generated code on test cases. The benchmark includes 10,000 problems, which range from having simple one-line solutions to being substantial algorithmic challenges. Large language models are fined-tuned on both GitHub and a special training set, and it’s found that the prevalence of syntax errors is decreasing exponentially as models improve. Recent models such as GPT-Neo can pass approximately 20% of the test cases of introductory problems, so it’s found that machine learning models are now beginning to learn how to code. The code associated with this paper can be found HERE.

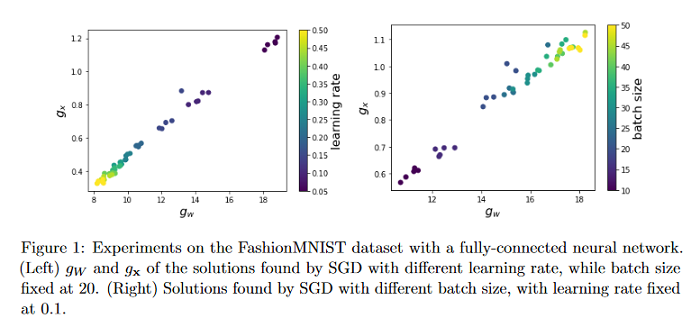
The Sobolev Regularization Effect of Stochastic Gradient Descent
The multiplicative structure of parameters and input data in the first layer of neural networks is explored in this paper to build connection between the landscape of the loss function with respect to parameters and the landscape of the model function with respect to input data. By this connection, it is shown that flat minima regularize the gradient of the model function, which explains the good generalization performance of flat minima. Then, the paper goes beyond the flatness and consider high-order moments of the gradient noise, and show that Stochastic Gradient Dascent (SGD) tends to impose constraints on these moments by a linear stability analysis of SGD around global minima. Together with the multiplicative structure, it’s recognized that the Sobolev regularization effect of SGD, i.e. SGD regularizes the Sobolev seminorms of the model function with respect to the input data. Finally, bounds for generalization error and adversarial robustness are provided for solutions found by SGD under assumptions of the data distribution.
Scaling Hierarchical Agglomerative Clustering to Billion-sized Datasets
Hierarchical Agglomerative Clustering (HAC) is one of the oldest but still most widely used clustering methods. However, HAC is notoriously hard to scale to large data sets as the underlying complexity is at least quadratic in the number of data points and many algorithms to solve HAC are inherently sequential. This paper proposes Reciprocal Agglomerative Clustering (RAC), a distributed algorithm for HAC, that uses a novel strategy to efficiently merge clusters in parallel. The paper proves theoretically that RAC recovers the exact solution of HAC. Furthermore, under clusterability and balancedness assumption it’s shown provable speedups in total runtime due to the parallelism. It’s also shown that these speedups are achievable for certain probabilistic data models. In extensive experiments, it’s shown that this parallelism is achieved on real world data sets and that the proposed RAC algorithm can recover the HAC hierarchy on billions of data points connected by trillions of edges in less than an hour.

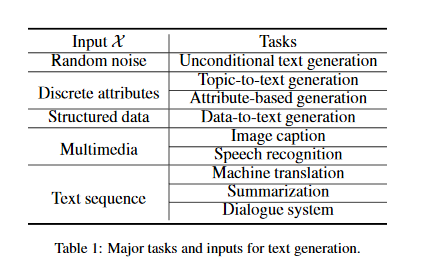
Pretrained Language Models for Text Generation: A Survey
Text generation has become one of the most important yet challenging tasks in natural language processing (NLP). The resurgence of deep learning has greatly advanced this field by neural generation models, especially the paradigm of pretrained language models (PLMs). This paper presents an overview of the major advances achieved in the topic of PLMs for text generation. As the preliminaries, the paper presents the general task definition and briefly describe the mainstream architectures of PLMs for text generation. As the core content, the paper discusses how to adapt existing PLMs to model different input data and satisfy special properties in the generated text.
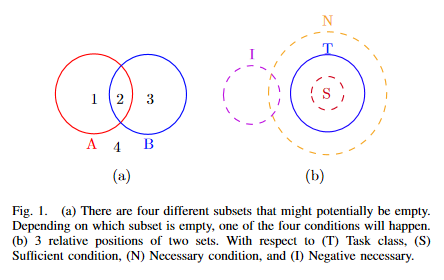
Cause and Effect: Concept-based Explanation of Neural Networks
In many scenarios, human decisions are explained based on some high-level concepts. This paper takes a step in the interpretability of neural networks by examining their internal representation or neuron’s activations against concepts. A concept is characterized by a set of samples that have specific features in common. A framework is proposed to check the existence of a causal relationship between a concept (or its negation) and task classes. While the previous methods focus on the importance of a concept to a task class, the paper goes further and introduces four measures to quantitatively determine the order of causality. Through experiments, the effectiveness of the proposed method is demonstrated in explaining the relationship between a concept and the predictive behaviour of a neural network.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind