
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Revisiting Deep Learning Models for Tabular Data

The necessity of deep learning for tabular data is still an unanswered question addressed by a large number of research efforts. The recent literature on tabular DL proposes several deep architectures reported to be superior to traditional “shallow” models like Gradient Boosted Decision Trees. However, since existing works often use different benchmarks and tuning protocols, it is unclear if the proposed models universally outperform GBDT. Moreover, the models are often not compared to each other, therefore, it is challenging to identify the best deep model for practitioners. This paper starts with a thorough review of the main families of DL models recently developed for tabular data. The authors carefully tune and evaluate them on a wide range of datasets and reveal two significant findings. First, it is shown that the choice between GBDT and DL models highly depends on data and there is still no universally superior solution. Second, it’s demonstrated that a simple ResNet-like architecture is a surprisingly effective baseline, which outperforms most of the sophisticated models from the DL literature. Finally, the authors design a simple adaptation of the Transformer architecture for tabular data that becomes a new strong DL baseline and reduces the gap between GBDT and DL models on datasets where GBDT dominates. The GitHub repo associated with this paper can be found HERE.
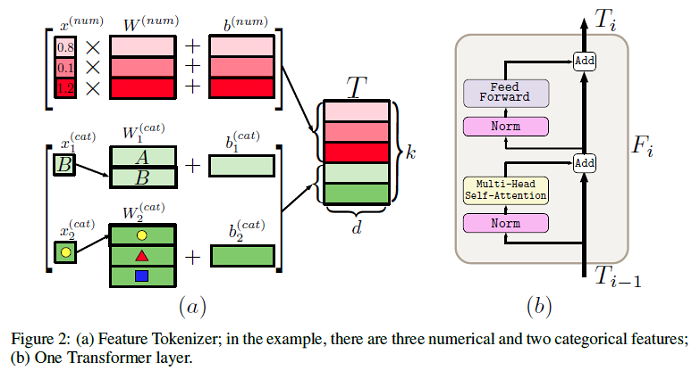
SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
Tabular data underpins numerous high-impact applications of machine learning from fraud detection to genomics and healthcare. Classical approaches to solving tabular problems, such as gradient boosting and random forests, are widely used by practitioners. However, recent deep learning methods have achieved a degree of performance competitive with popular techniques. This paper devises a hybrid deep learning approach to solving tabular data problems. The proposed method, SAINT, performs attention over both rows and columns, and it includes an enhanced embedding method. The paper also studies a new contrastive self-supervised pre-training method for use when labels are scarce. SAINT consistently improves performance over previous deep learning methods, and it even outperforms gradient boosting methods, including XGBoost, CatBoost, and LightGBM, on average over a variety of benchmark tasks. The GitHub repo associated with this paper can be found HERE.
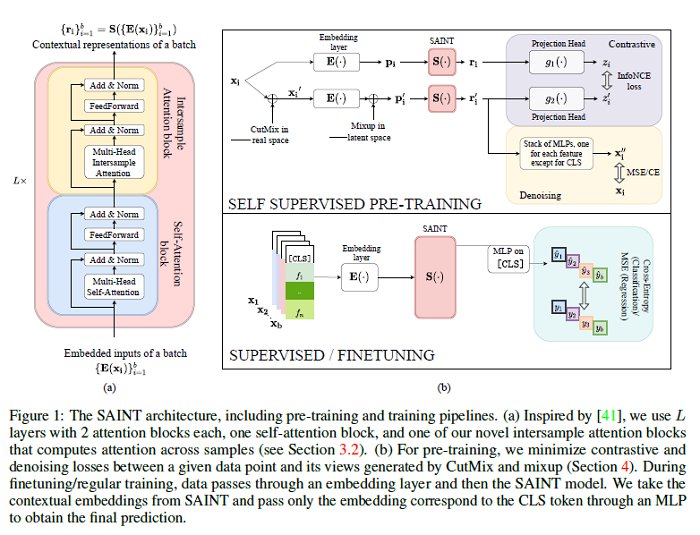
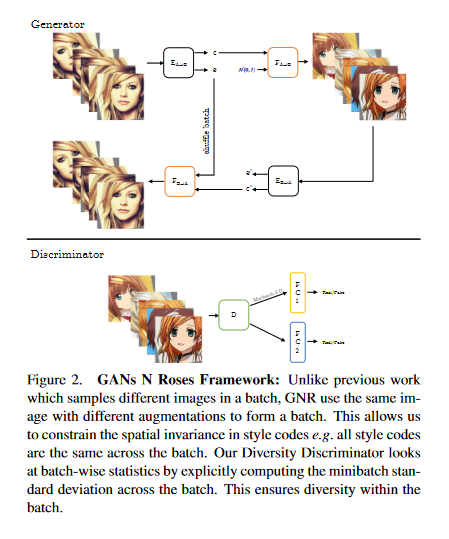
GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!)
The research detailed in this paper shows how to learn a map that takes a content code, derived from a face image, and a randomly chosen style code to an anime image. An adversarial loss from our simple and effective definitions of style and content is derived. This adversarial loss guarantees the map is diverse — a very wide range of anime can be produced from a single content code. Under plausible assumptions, the map is not just diverse, but also correctly represents the probability of an anime, conditioned on an input face. In contrast, current multimodal generation procedures cannot capture the complex styles that appear in anime. Extensive quantitative experiments support the idea the map is correct. Extensive qualitative results show that the method can generate a much more diverse range of styles than SOTA comparisons. Finally, the paper shows that the formalization of content and style makes it possible to perform video to video translation without ever training on videos. The GitHub repo associated with this paper can be found HERE.
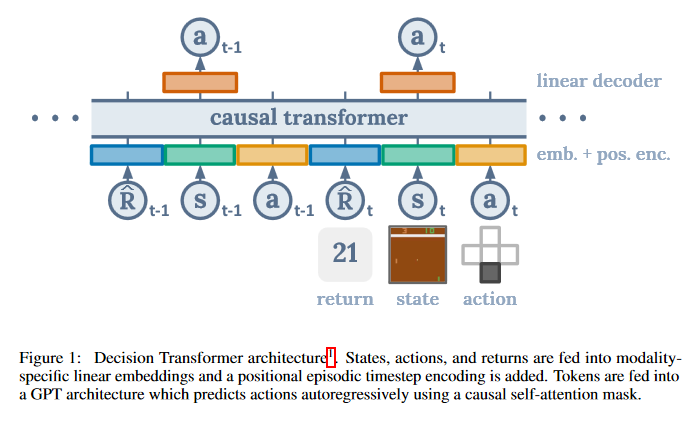
Decision Transformer: Reinforcement Learning via Sequence Modeling
This paper introduces a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem. This makes it possible to draw upon the simplicity and scalability of the Transformer architecture, and associated advances in language modeling such as GPT-x and BERT. In particular, the paper presents Decision Transformer, an architecture that casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, the Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity, Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on Atari, OpenAI Gym, and Key-to-Door tasks. The GitHub repo associated with this paper can be found HERE.
A Survey on Neural Speech Synthesis
Text to speech (TTS), or speech synthesis, which aims to synthesize intelligible and natural speech given text, is a hot research topic in speech, language, and machine learning communities and has broad applications in the industry. As the development of deep learning and artificial intelligence, neural network-based TTS has significantly improved the quality of synthesized speech in recent years. This paper conducts a comprehensive survey on neural TTS, aiming to provide a good understanding of current research and future trends. The focus is on the key components in neural TTS, including text analysis, acoustic models and vocoders, and several advanced topics, including fast TTS, low-resource TTS, robust TTS, expressive TTS, and adaptive TTS, etc. The paper further summarizes resources related to TTS (e.g., datasets, opensource implementations) and discuss future research directions.

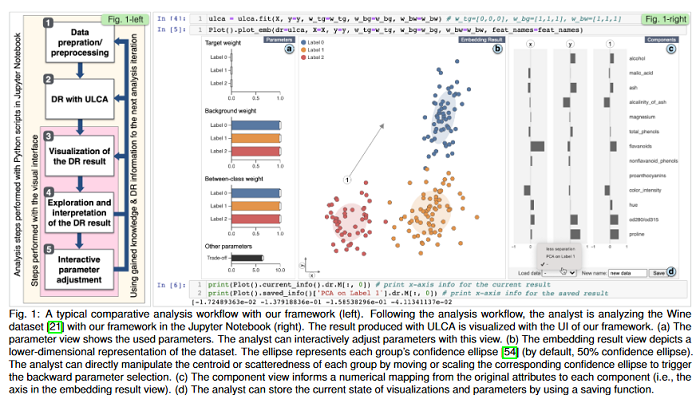
Interactive Dimensionality Reduction for Comparative Analysis
Finding the similarities and differences between two or more groups of datasets is a fundamental analysis task. For high-dimensional data, dimensionality reduction (DR) methods are often used to find the characteristics of each group. However, existing DR methods provide limited capability and flexibility for such comparative analysis as each method is designed only for a narrow analysis target, such as identifying factors that most differentiate groups. This paper introduces an interactive DR framework where a new DR method, called ULCA (unified linear comparative analysis), is integrated with an interactive visual interface. ULCA unifies two DR schemes, discriminant analysis and contrastive learning, to support various comparative analysis tasks. To provide flexibility for comparative analysis, an optimization algorithm was developed that enables analysts to interactively refine ULCA results. Additionally, an interactive visualization interface is provided to examine ULCA results with a rich set of analysis libraries.
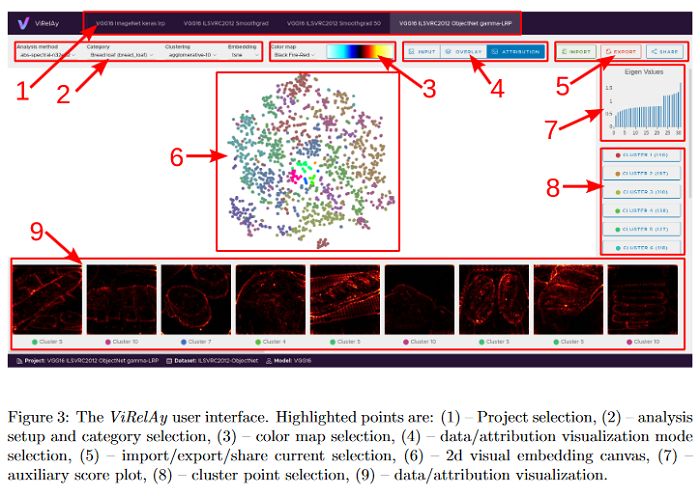
Deep Neural Networks (DNNs) are known to be strong predictors, but their prediction strategies can rarely be understood. With recent advances in Explainable AI, approaches are available to explore the reasoning behind those complex models’ predictions. One class of approaches are post-hoc attribution methods, among which Layer-wise Relevance Propagation (LRP) shows high performance. However, the attempt at understanding a DNN’s reasoning often stops at the attributions obtained for individual samples in input space, leaving the potential for deeper quantitative analyses untouched. As a manual analysis without the right tools is often unnecessarily labor intensive, this paper introduces three software packages targeted at scientists to explore model reasoning using attribution approaches and beyond: (1) Zennit – a highly customizable and intuitive attribution framework implementing LRP and related approaches in PyTorch, (2) CoRelAy – a framework to easily and quickly construct quantitative analysis pipelines for dataset-wide analyses of explanations, and (3) ViRelAy – a web-application to interactively explore data, attributions, and analysis results.
Towards Automatic Speech to Sign Language Generation
The research discussed in this paper aims to solve the highly challenging task of generating continuous sign language videos solely from speech segments for the first time. Recent efforts in this space have focused on generating such videos from human-annotated text transcripts without considering other modalities. However, replacing speech with sign language proves to be a practical solution while communicating with people suffering from hearing loss. Therefore, the research eliminates the need of using text as input and design techniques that work for more natural, continuous, freely uttered speech covering an extensive vocabulary. Since the current datasets are inadequate for generating sign language directly from speech, the paper discusses the collection and release of the first Indian sign language data set comprising speech-level annotations, text transcripts, and the corresponding sign-language videos. Also proposed is a multi-tasking transformer network trained to generate signer’s poses from speech segments. With speech-to-text as an auxiliary task and an additional cross-modal discriminator, the model learns to generate continuous sign pose sequences in an end-to-end manner. Extensive experiments and comparisons with other baselines demonstrate the effectiveness of the approach.

Deep Fake Detection: Survey of Facial Manipulation Detection Solutions
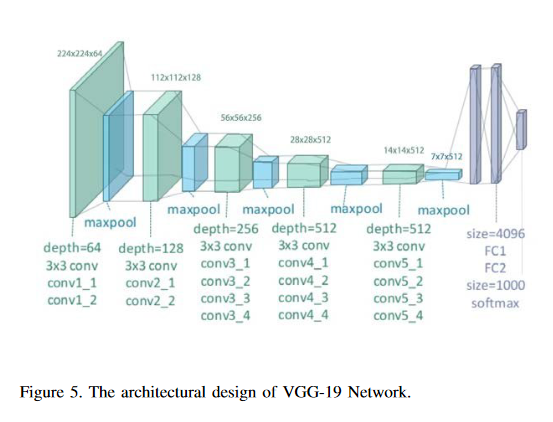
Deep Learning as a field has been successfully used to solve a plethora of complex problems, the likes of which we could not have imagined a few decades back. But as many benefits as it brings, there are still ways in which it can be used to bring harm to our society. Deep fakes have been proven to be one such problem, and now more than ever, when any individual can create a fake image or video simply using an application on the smartphone, there need to be some countermeasures, with which we can detect if the image or video is a fake or real and dispose of the problem threatening the trustworthiness of online information. Although the Deep fakes created by neural networks, may seem to be as real as a real image or video, it still leaves behind spatial and temporal traces or signatures after moderation, these signatures while being invisible to a human eye can be detected with the help of a neural network trained to specialize in Deep fake detection. This paper analyzes several such states of the art neural networks (MesoNet, ResNet-50, VGG-19, and Xception Net) and compare them against each other, to find an optimal solution for various scenarios like real-time deep fake detection to be deployed in online social media platforms where the classification should be made as fast as possible or for a small news agency where the classification need not be in real-time but requires utmost accuracy.
Understanding the Spread of COVID-19 Epidemic: A Spatio-Temporal Point Process View
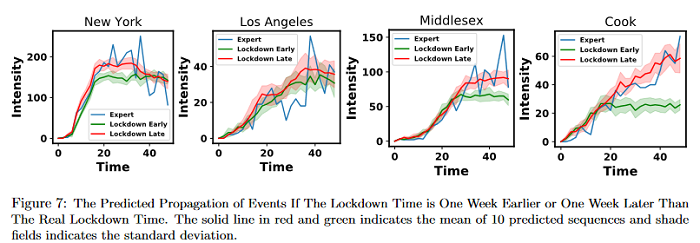
Since the first coronavirus case was identified in the U.S. on Jan. 21, more than 1 million people in the U.S. have confirmed cases of COVID-19. This infectious respiratory disease has spread rapidly across more than 3000 counties and 50 states in the U.S. and have exhibited evolutionary clustering and complex triggering patterns. It is essential to understand the complex spacetime intertwined propagation of this disease so that accurate prediction or smart external intervention can be carried out. This paper models the propagation of the COVID-19 as spatio-temporal point processes and propose a generative and intensity-free model to track the spread of the disease. Further adopted is a generative adversarial imitation learning framework to learn the model parameters. In comparison with the traditional likelihood-based learning methods, this imitation learning framework does not need to prespecify an intensity function, which alleviates the model-misspecification. Moreover, the adversarial learning procedure bypasses the difficult-to-evaluate integral involved in the likelihood evaluation, which makes the model inference more scalable with the data and variables. The paper showcases the dynamic learning performance on the COVID-19 confirmed cases in the U.S. and evaluate the social distancing policy based on the learned generative model.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind