
A new proposal from tech giant Yandex overcomes a major hurdle in the advancement of machine learning by bringing the process to the masses, so that anyone with a home computer can help train a large neural network.
Modern deep learning applications require many GPUs, which can be costly, and so are usually only accessible to well-funded companies and institutions. To ensure ML model training doesn’t become exclusively the domain of big organizations that can afford the tech required, developers have experimented with pooling the computing resources of a group of volunteers. Grid- or volunteer-computing is a good idea, but there are issues around high latency, asymmetrical bandwidth, and challenges specific to volunteer computing.
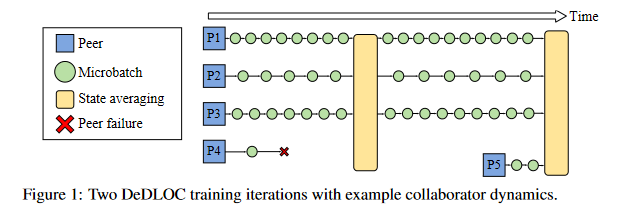
Yandex is proposing a solution called Distributed Deep Learning in Open Collaborations (DeDLOC) that addresses those challenges by taking the best attributes of data parallelism in GPUs and improving popular distributed training techniques. DeDLOC makes it possible for anyone in the ML community to run large-scale distributed pre-training with their friends.
- The new algorithmic framework adapts itself to the different network and hardware set-ups of the participants for efficient data transfer.
- DeDLOC has been successfully tested – Yandex’s team of researchers, together with Hugging Face, a professor from the University of Toronto and others, used the method to pretrain sahajBERT, a model for the Bengali language, with 40 volunteers. On downstream tasks, the model achieves quality comparable to much larger models using hundreds of high-tier accelerators.
- DeDLOC may also be important for multilingual NLP. Now, the community for any language can train their own models without needing huge computational resources concentrated in one place.
The GitHub repo associated with DeDLOC can be found HERE.
The DeDLOC research paper can be found here: https://arxiv.org/abs/2106.10207
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind