
In this blog post, we want to provide a peek behind the curtains on how we extract information with Natural Language Processing (NLP). You’ll learn how to appy state-of-the-art Transformer models for this problem and how to go from an ML model idea to integration in the Digits app.
Information can be extracted from unstructured text through a process called Named Entity Recognition (NER). This NLP concept has been around for many years, and its goal is to classify tokens into predefined categories, such as dates, persons, locations, and entities.
For example, the transaction below could be transformed into the following structured format:
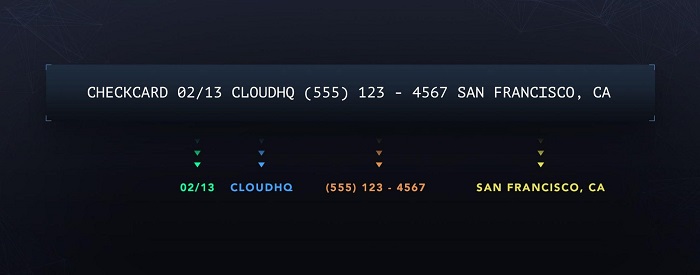
We had seen outstanding results from NER implementations applied to other industries and we were eager to implement our own banking-related NER model. Rather than adopting a pre-trained NER model, we envisioned a model built with a minimal number of dependencies. That avenue would allow us to continuously update the model while remaining in control of “all moving parts.” With this in mind, we discarded available tools like the SpaCy NER implementation or HuggingFace models for NER. We ended up building our internal NER model based only on TensorFlow 2.x and the ecosystem library TensorFlow Text.
Every Machine Learning project starts with the data, and so did this one. We decided which relevant information we wanted to extract (e.g., location, website URLs, party names, etc.) and, in the absence of an existing public data set, we decided to annotate the data ourselves.
There are a number of commercial and open-source tools available for data annotation, including:
- Explosion’s Prodigy (works well in connection with Python’s SpaCy)
- Label Studio (free, open-source tool)
- AWS Mechanical Turk (commercial service which handles the recruiting of annotators and the handling of the tasks)
- Scale AI (fully managed annotation service)
The optimal tool varies with each project, and is a question of cost, speed, and useful UI. For this project, our key driver for our tool selection was the quality of the UI and the speed of the sample processing, and we chose doccano.
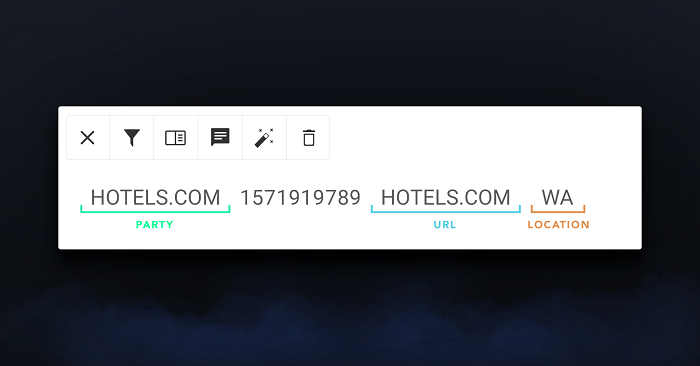
At least one human reviewer then evaluated each selected transaction, and that person would mark the relevant sub-strings as shown above. The end-product of this processing step was a data set of annotated transactions together with the start- and end-character of each entity within the string.
While NER models can also be based on statistical methods, we established our NER models on an ML architecture called Transformers. This decision was based on two major factors:
- Transformers provide a major improvement in NLP when it comes to language understanding. Instead of evaluating a sentence token-by-token, the way recurrent networks would perform this task, transformers use an attention mechanism to evaluate the connections between the tokens.
- Transformers allow the evaluation of up to 512 tokens simultaneously (with some evaluating even more tokens).
The initial attention-based model architecture was the Bidirectional Encoder Representation from Transformers (BERT, for short), published in 2019. In the original paper by Google AI, the author already highlighted potential applications to NER, which gave us confidence that our transformer approach might work.

Furthermore, we had previously implemented various other deep-learning applications based on BERT architectures and we were able to reuse our existing shared libraries. This allowed us to develop a prototype in a short amount of time.
BERT models can be used as pre-trained models, which are initially trained on multi-lingual corpi on two general tasks: predicting mask tokens and predicting if the next sentence has a connection to the previous one. Such general training creates a general language understanding within the model. The pre-trained models are provided by various companies, for example, by Google via TensorFlow Hub. The pre-trained model can then be fine-tuned during a task-specific training phase. This requires less computational resources than training a model from scratch.
The BERT architecture can compute up to 512 tokens simultaneously. BERT requires WordPiece tokenization which splits words and sentences into frequent word chunks. The following example sentence would be tokenized as follows:
Digits builds a real-time engine
[b’dig’, b’##its’, b’builds’, b’a’, b’real’, b’-‘, b’time’, b’engine’]
There are a variety of pre-trained BERT models available online, but each has a different focus. Some models are language-specific (e.g., CamemBERT for French or Beto for Spanish), and other models have been reduced in their size through model distillation or pruning (e.g., ALBERT or DistilBERT).
Our prototype model was designed to classify the sequence of tokens which represent the transaction in question. We converted the annotated data into a sequence of labels that matched the number of tokens generated from the transactions for the training. Then, we trained the model to classify each token label:

In the figure above, you notice the “O” tokens. Such tokens represent irrelevant tokens, and we trained the classifier to detect those as well.
The prototype model helped us demonstrate a business fit of the ML solution before engaging in the full model integration. At Digits, we develop our prototypes in GPU-backed Jupyter notebooks. Such a process helps us to iterate quickly. Then, once we confirm a business use-case for the model, we focus on the model integration and the automation of the model version updates via our MLOps pipelines.
In general, we use TensorFlow Extended (TFX) to update our model versions. In this step, we convert the notebook code into TensorFlow Ops, and here we converted our prototype data preprocessing steps into TensorFlow Transform Ops. This extra step allows us later to train our model versions effectively, avoid training-serving skew, and furthermore allows us to “bake” our internal business logic into our ML models. This last benefit helps us to reduce the dependencies between our ML models and our data pipeline or back-end integrations.
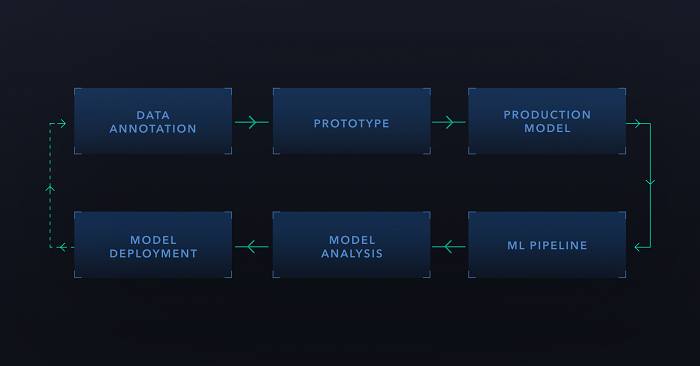
We are running our TFX pipelines on Google Cloud’s Vertex AI pipelines. This managed service frees us from maintaining a Kubernetes cluster for Kubeflow Pipelines (which we have done prior to using Vertex AI).
Our production models are stored in Google Cloud Storage buckets, and TFServing allows us to load model versions directly from cloud storage. Because of the dynamic loading of the model versions, we don’t need to build custom containers for our model serving setup; we can use the pre-built images from the TensorFlow team.
Here is a minimal setup for Kubernetes deployment:
apiVersion: apps/v1 kind: Deployment metadata: … name: tensorflow-serving-deployment spec: … template: … spec: containers: – name: tensorflow-serving-container image: tensorflow/serving:2.5.1 command: – /usr/local/bin/tensorflow_model_server args: – –port=8500 – –model_config_file=/serving/models/config/models.conf – –file_system_poll_wait_seconds=120 …
Note the additional argument –file_system_poll_wait_seconds in the list above. By default, TFServing will check the file system for new model versions every 2s. This can generate large Cloud Storage costs since every check triggers a list operation, and storage costs are billed based on the used network volume. For most applications, it is fine to reduce the file system check to every 2 minutes (set the value to 120 seconds) or disable it entirely (set the value to 0).
For maintainability, we keep all model-specific configurations in a specific ConfigMap. The generated file is then consumed by TFServing on boot-up.
apiVersion: v1 kind: ConfigMap metadata: namespace: ml-deployments name: <MODEL_NAME>-config data: models.conf: |+ model_config_list: { config: { name: “<MODEL_NAME>”, base_path: “gs://<BUCKET_NAME>/<MODEL_NAME>”, model_platform: “tensorflow”, model_version_policy: { specific: { versions: 1607628093, versions: 1610301633 } } version_labels { key: ‘canary’, value: 1610301633 } version_labels { key: ‘release’, value: 1607628093 } } }
After the initial deployment, we started iterating to optimize the model architecture for high throughput and low latency results. This meant optimizing our deployment setup for BERT-like architectures and optimizing the trained BERT models. For example, we optimized the integration between our data processing Dataflow jobs and our ML deployments, and shared our approach in our recent talk at the Apache Beam Summit 2021.
The deployed NER model allows us to extract a multitude of information from unstructured text and make it available through Digits Search.
Here are some examples of our NER model extractions:

The Final Product
At Digits, an ML model is never itself the final product. We strive to delight our customers with well-designed experiences that are tightly integrated with ML models, and only then do we witness the final product. Many additional factors come into play:
Latency vs. Accuracy
A more recent pre-trained model (e.g., BART or T5) could have provided higher model accuracy, but it would have also increased the model latency substantially. Since we are processing millions of transactions daily, it became clear that model latency is critical for us. Therefore, we spent a significant amount of time on the optimization of our trained models.
Design for false-positive scenarios
There will always be false positives, regardless of how stunning the model accuracy was pre-model deployment. Product design efforts that focus on communicating ML-predicted results to end-users are critical. At Digits, this is especially important because we cannot risk customers’ confidence in how Digits is handling their financial data.
Automation of model deployments
The investment in our automated model deployment setup helped us provide model rollback support. All changes to deployed models are version controlled, and deployments are automatically executed from our CI/CD system. This provides a consistent and transparent deployment workflow for our engineering team.
Devise a versioning strategy for release and rollback
To assist smooth model rollout and a holistic quantitative analysis prior to rollout, we deploy two versions of the same ML model and use TFServing’s version labels (e.g., “release” and “pre-release” tags) to differentiate between them. Additionally, we use an active version table that allows for version rollbacks, made as simple as updating a database record.
Assist customers, don’t alienate them
Last but not least, the goal for our ML models should always be to assist our customers in their tasks instead of alienating them. That means our goal is not to replace humans or their functions, but to help our customers with cumbersome tasks. Instead of asking people to extract information manually from every transaction, we’ll assist our customers by pre-filling extracted vendors, but they will always stay in control. If we make a mistake, Digits makes it easy to overwrite our suggestions. In fact, we will learn from our mistakes and update our ML models accordingly.
Check out these great resources for even more on NER and Transformer models:
- Initial BERT paper: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
- Effective TensorFlow 2.x
- Text Preprocessing in TensorFlow models
- TensorFlow in Production
About the Author

Hannes Hapke is a Machine Learning Engineer at Digits. As a Google Developer Expert, Hannes has co-authored two machine learning publications: “NLP in Action” by Manning Publishing, and “Building Machine Learning Pipelines” by O’Reilly Media. At Digits, he focuses on ML engineering and applies his experience in NLP to advance the understanding of financial transactions.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind