
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
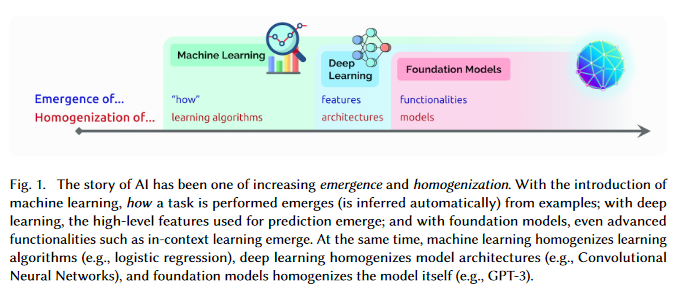
On the Opportunities and Risks of Foundation Models

AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. These models can be thought of as foundation models to underscore their critically central yet incomplete character. This paper provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Do Vision Transformers See Like Convolutional Neural Networks?
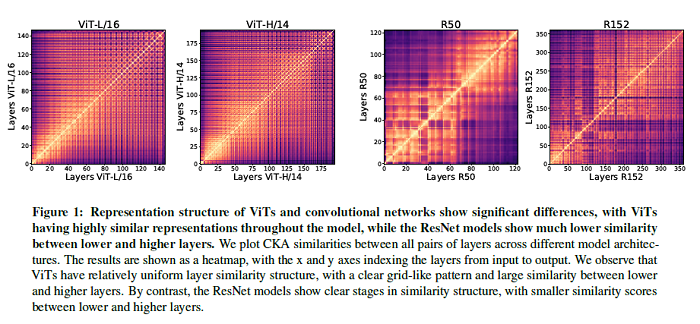
Convolutional neural networks (CNNs) have so far been the de-facto model for visual data. Recent work has shown that (Vision) Transformer models (ViT) can achieve comparable or even superior performance on image classification tasks. This raises a central question: how are Vision Transformers solving these tasks? Are they acting like convolutional networks, or learning entirely different visual representations? Analyzing the internal representation structure of ViTs and CNNs on image classification benchmarks, striking differences between the two architectures have been found, such as ViT having more uniform representations across all layers. This paper explores how these differences arise, finding crucial roles played by self-attention, which enables early aggregation of global information, and ViT residual connections, which strongly propagate features from lower to higher layers. The paper studies the ramifications for spatial localization, demonstrating ViTs successfully preserve input spatial information, with noticeable effects from different classification methods. Finally, the paper studies the effect of (pretraining) dataset scale on intermediate features and transfer learning, and conclude with a discussion on connections to new architectures such as the MLP-Mixer.
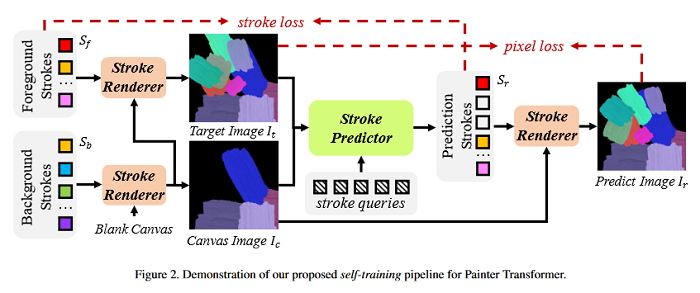
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Neural painting refers to the procedure of producing a series of strokes for a given image and non-photo-realistically recreating it using neural networks. While reinforcement learning (RL) based agents can generate a stroke sequence step by step for this task, it is not easy to train a stable RL agent. On the other hand, stroke optimization methods search for a set of stroke parameters iteratively in a large search space; such low efficiency significantly limits their prevalence and practicality. Different from previous methods, this paper formulates the task as a set prediction problem and propose a novel Transformer-based framework, dubbed Paint Transformer, to predict the parameters of a stroke set with a feed forward network. This way, the model can generate a set of strokes in parallel and obtain the final painting of size 512 * 512 in near real time. More importantly, since there is no data set available for training the Paint Transformer, the research devises a self-training pipeline such that it can be trained without any off-the-shelf dataset while still achieving excellent generalization capability. Experiments demonstrate that our method achieves better painting performance than previous ones with cheaper training and inference costs. The GitHub repo associated with this paper can be found HERE.
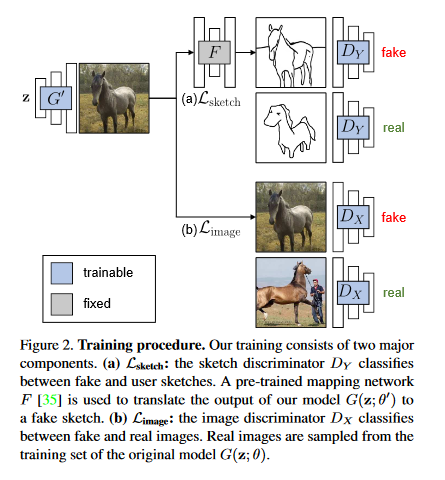
Can a user create a deep generative model by sketching a single example? Traditionally, creating a GAN model has required the collection of a large-scale data set of exemplars and specialized knowledge in deep learning. In contrast, sketching is possibly the most universally accessible way to convey a visual concept. This paper presents a method, GAN Sketching, for rewriting GANs with one or more sketches, to make GANs training easier for novice users. In particular, the weights of an original GAN model are changed according to user sketches. The model’s output is encouraged to match the user sketches through a cross-domain adversarial loss. Furthermore, different regularization methods are explored to preserve the original model’s diversity and image quality. Experiments have shown that this method can mold GANs to match shapes and poses specified by sketches while maintaining realism and diversity. The GitHub repo associated with this paper can be found HERE.
Lights, Camera, Action! A Framework to Improve NLP Accuracy over OCR documents
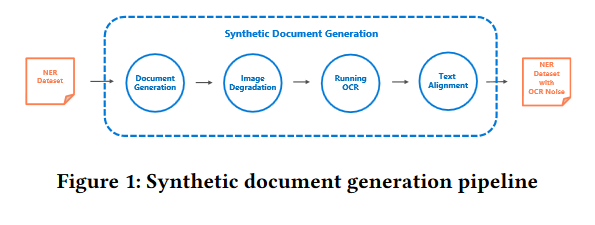
Document digitization is essential for the digital transformation of our societies, yet a crucial step in the process, Optical Character Recognition (OCR), is still not perfect. Even commercial OCR systems can produce questionable output depending on the fidelity of the scanned documents. This paper demonstrates an effective framework for mitigating OCR errors for any downstream NLP task, using Named Entity Recognition (NER) as an example. First addressed is the data scarcity problem for model training by constructing a document synthesis pipeline, generating realistic but degraded data with NER labels. The NER accuracy drop is estimated at various degradation levels and show that a text restoration model, trained on the degraded data, significantly closes the NER accuracy gaps caused by OCR errors, including on an out-of-domain dataset. For the benefit of the community, the document synthesis pipeline is made available as an open-source project. The GitHub repo associated with this paper can be found HERE.
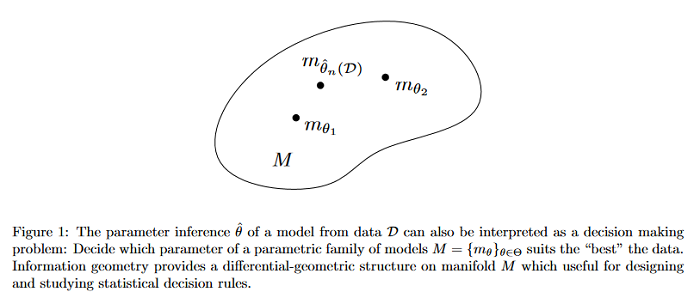
An elementary introduction to information geometry
This survey describes the fundamental differential-geometric structures of information manifolds, state the fundamental theorem of information geometry, and illustrates some use cases of these information manifolds in information sciences. The exposition is self-contained by concisely introducing the necessary concepts of differential geometry, but proofs are omitted for brevity.
Interpretable Propaganda Detection in News Articles
Online users today are exposed to misleading and propagandistic news articles and media posts on a daily basis. To counter thus, a number of approaches have been designed aiming to achieve a healthier and safer online news and media consumption. Automatic systems are able to support humans in detecting such content; yet, a major impediment to their broad adoption is that besides being accurate, the decisions of such systems need also to be interpretable in order to be trusted and widely adopted by users. Since misleading and propagandistic content influences readers through the use of a number of deception techniques, this paper proposes to detect and to show the use of such techniques as a way to offer interpretability.

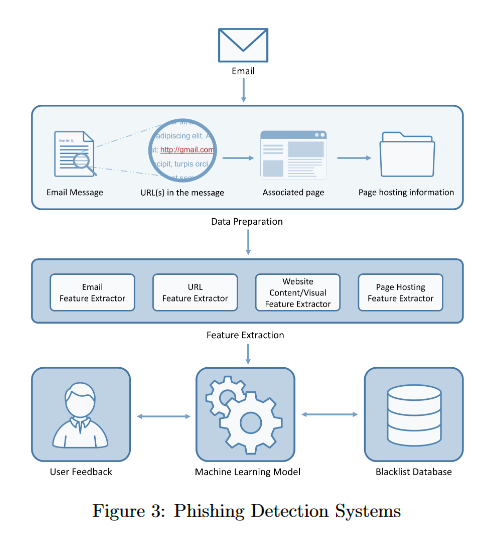
Man versus Machine: AutoML and Human Experts’ Role in Phishing Detection
Machine learning (ML) has developed rapidly in the past few years and has successfully been utilized for a broad range of tasks, including phishing detection. However, building an effective ML-based detection system is not a trivial task, and requires data scientists with knowledge of the relevant domain. Automated Machine Learning (AutoML) frameworks have received a lot of attention in recent years, enabling non-ML experts in building a machine learning model. This brings to an intriguing question of whether AutoML can outperform the results achieved by human data scientists. This paper compares the performances of six well-known, state-of-the-art AutoML frameworks on ten different phishing datasets to see whether AutoML-based models can outperform manually crafted machine learning models. The results indicate that AutoML-based models are able to outperform manually developed machine learning models in complex classification tasks, specifically in datasets where the features are not quite discriminative, and datasets with overlapping classes or relatively high degrees of non-linearity.
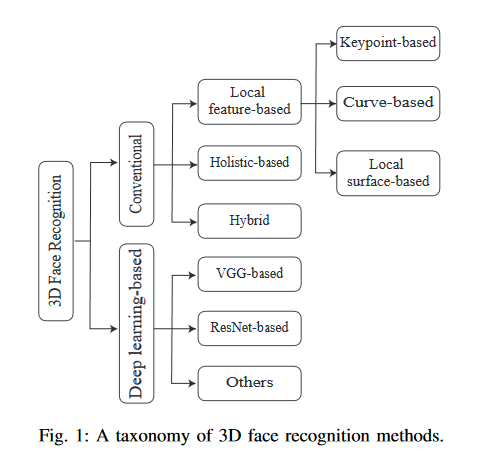
Face recognition is one of the most studied research topics in the community. In recent years, the research on face recognition has shifted to using 3D facial surfaces, as more discriminating features can be represented by the 3D geometric information. This survey focuses on reviewing the 3D face recognition techniques developed in the past ten years which are generally categorized into conventional methods and deep learning methods. The categorized techniques are evaluated using detailed descriptions of the representative works. The advantages and disadvantages of the techniques are summarized in terms of accuracy, complexity and robustness to face variation (expression, pose and occlusions, etc). The main contribution of this survey is that it comprehensively covers both conventional methods and deep learning methods on 3D face recognition. In addition, a review of available 3D face databases is provided, along with the discussion of future research challenges and directions.
Understanding the Generalization of Adam in Learning Neural Networks with Proper Regularization
Adaptive gradient methods such as Adam have gained increasing popularity in deep learning optimization. However, it has been observed that compared with (stochastic) gradient descent, Adam can converge to a different solution with a significantly worse test error in many deep learning applications such as image classification, even with a fine-tuned regularization. This paper provides a theoretical explanation for this phenomenon: it is shown that in the nonconvex setting of learning over-parameterized two-layer convolutional neural networks starting from the same random initialization, for a class of data distributions (inspired from image data), Adam and gradient descent (GD) can converge to different global solutions of the training objective with provably different generalization errors, even with weight decay regularization. In contrast, it is shown that if the training objective is convex, and the weight decay regularization is employed, any optimization algorithms including Adam and GD will converge to the same solution if the training is successful. This suggests that the inferior generalization performance of Adam is fundamentally tied to the nonconvex landscape of deep learning optimization.

Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind