
In this special guest feature, Dotan Horovits, Technology Evangelist at Logz.io, delves into the three pillars of Observability (logs, metrics and traces), the ways in which Observability is defined and how the tech industry should be using it moving forward. Dotan lives at the intersection of technology, product and innovation. With over 20 years in the hi-tech industry as a software developer, a solutions architect and a product manager, he brings a wealth of knowledge in cloud computing, big data solutions, DevOps practices and more. Dotan is an avid advocate of open source software, open standards and communities. He also is an advocate of the Cloud Native Computing Foundation (CNCF), organizes the local CNCF chapter in Tel-Aviv and runs the OpenObservability Talks podcast, among others.
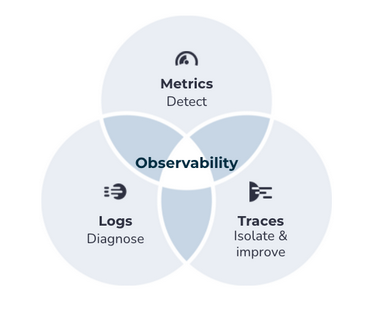
Observability is a hot topic in the IT world these days. It is oftentimes discussed through the lens of the “three pillars of observability”: Logs, Metrics and Traces. These pillars help us understand what happened, where it happened and why it happened in our system:
Metrics help detect the issues and tell what happened: Is the service down? Was the endpoint slow to respond? Metrics are aggregated numerical data that lends itself to spotting abnormal behavior.
Next, Logs help diagnose the issues and tell why they happened. Logs are perfect for that job, as the developer who writes application code outputs all the relevant context for that code into logs.
Finally, traces help isolate issues and tell where they happened. As a request comes into the system, it flows through a chain of interacting microservices, which we can trace using distributed tracing, to pinpoint the issues.
Indeed these telemetry signals are very important for gaining observability. However they are, by themselves, not Observability. In fact, many organizations collect all these signals, and still end up with poor observability. Why’s that?
Perhaps the problem starts with the way we define Observability.
So what is Observability about?
The formal definition of Observability, taken from Control Theory, is:
“a measure of how well internal states of a system can be inferred from knowledge of its external outputs.”
This definition may have driven people to put great emphasis on the external outputs, the signals that our systems emit, the raw data. The other important element in that definition was too often overlooked: the inference process.
A more useful definition of observability for a software systems is:
“The capability to allow a human to ask and answer questions about the system”.
I like this definition for two important reasons:
First, it makes it clear that Observability is a property of the system. It might sound trivial, but it’s important as it drives a different mindset from traditional monitoring solutions that we used to bolt on in the aftermath. Being a system property means you should incorporate observability as part of the system design, as a first-level citizen, from Day-1. This draws practical implications that I’ll touch upon later.
It’s about answering ad-hoc questions
The second reason I like the above definition for Observability better is that it makes it clear that observability is essentially a data analysis problem: the more questions we can ask and answer about the system, the more observable it is. This, as well, calls for a different mindset: rather than the sysadmin’s relatively reactive monitoring and maintenance mindset, observability calls for a data analyst mindset, proactively querying to get the right insights from their systems.
And this can’t be limited to a set of predefined questions either. Common monitoring practices, for example, use pre-defined aggregations, which bear hidden assumptions of the questions we’d want to ask. In today’s high cardinality and dynamically changing systems, however, it is unreasonable to assume we can anticipate all the questions, all the permutations of dimensions, and the required aggregations. We don’t encounter the same problems over and over again (we’ve set alerts or auto-remediation for these “known unknowns” anyway). Observability must enable us to ask ad-hoc questions, ones that arise when handling incidents we haven’t anticipated or seen before, the “unknown unknowns”.
So how are we achieving this promise?
It’s about collecting data of different sources, formats and types
To gain observability, we need to collect the different signal types. Logs, metrics and traces are the classical “three pillars”, but we need to make it flexible to incorporate additional signal types as need arises, such as events and continuous profiling.
Also, observability involves the ingestion of signals from many different data sources, across different tiers, frameworks and programming languages in today’s cloud-native and polyglot organizations. You may need to monitor a NodeJS front-end app, a Java back-end, your SQL and NoSQL databases, a Kafka cluster and a few cloud services (perhaps even in a multi-cloud setup) – and that’s not even considered exaggerated. To top it up, these may also come in different formats, as we’ll see below.
Consistently collecting heterogeneous data across so many different signal types, sources and formats requires careful planning and automation in order to support data analytics flows.
The industry is heading in this direction: Fluentd unified logs collection tool is expanding into collecting metrics, Telegraf is expanding from metrics to logs and events, Elastic is unifying Filebeat, Metricbeat, Packetbeat and the other Beats collectors of the ELK Stack into one unified Elastic Agent. These and other tools are also constantly expanding their integration with different data sources. OpenTelemetry under the Cloud Native Computing Foundation (CNCF) aims to provide a standard unified framework for collecting data, to converge the industry.
It’s about enriching and correlating data
Remember we said that observability is a property of the system? It begins with the way we emit our telemetry. For example, forget about unstructured plain text logs. No human is going to read through your mounts of log lines to extract insights, and full-text indexing and search is prohibitively expensive. We’re running data analytics here. Data needs to be structured and in a machine-readable format such as JSON or Protobuf.
In order to support effective data analytics, it is also important to build a concise data model, and adhere to it across the different telemetry sources and formats. If every data source calls the service name label in a different way (“service”, “service_name”, “ServiceID”, “container”), it would be very difficult to correlate across the sources. Open source projects such as OpenMetrics and OpenTelemetry take a central role in standardizing data models and semantic conventions. It’s important to note that integrating with legacy systems may require transformations to align these conventions, in an ETL fashion.
Data enrichment is also an important step in data analytics. Adding metadata such as the user ID or the build version to your logs, for instance, can greatly help map the log to the root cause (e.g. per specific customer or specific build version). Effective data enrichment can turn your logs into more meaningful events.
Data enrichment can also support correlation between signals. For example, systematically adding the request trace ID as metadata to all the logs will enable log-trace correlation later. Another example would be to add Exemplars to metrics: Exemplars are metadata that can be attached to the metric, to provide additional context and external references. A common use case of exemplars is to attach the trace ID for easy jump from a metric to a sample trace. The Prometheus community is actively working to formalize exemplars in the context of Prometheus, and a similar effort is taking place in OpenTelemetry.
It’s about unified querying, visualization and alerting
Having the data ingested and stored in a conventional form is a good start. Next, we need a way to easily ask and answer ad-hoc questions about our system – that is, as discussed above, the essence of observability. That requires the ability to query the data from the different sources to draw the relationships.
Today’s landscape, however, is quite fragmented, which makes unified querying, visualization and other investigation aspects challenging. In today’s world you often encounter specialized query languages for the different signal types and sources. You may use Lucene to query your logs, and PromQL to query your metrics. This, however, makes it difficult to phrase queries across the different signals.
The other common online investigative way, alongside querying, is visualization through dashboarding. There, too, it’s common to see different specialized tools for visualizing the different data types. You may find yourself using Kibana to visualize your logs and Grafana to visualize your metrics. If you want to correlate across the different signals, however, the multi-tool approach requires you to manually copy your search context over between the tools (things such as the time window under investigation and the filters in use), which can be very inefficient and error prone.
Taking the data analyst’s approach, we strive for unified querying as well as a unified dashboard to show different signals and slice and dice the telemetry data. Another related aspect for investigation is alerting, which potentially incorporates conditions over multiple different signals. There are multiple attempts in this direction to offer a unified user experience, whether through a single platform or a tightly integrated suite of tools.
Another important building block, which is gaining a lot of momentum recently, is the ability to run anomaly detection and other AIOps algorithms to automatically detect patterns for issues. Some of these patterns can only be detected when you correlate the different signals. AIOps use case requires an established data model, query and API across the signals.
Summary: It’s about fusing telemetry data to answer questions
The three pillars of observability – metrics, traces and logs – provide the essential signals for understanding what happened, where it happened and why it happened. But it’s important to remember that these signals are, after all, the raw data.
The goal is to bring together telemetry signals of different types and from different sources into one conceptual data lake or a data mesh, and then ask and answer questions to understand your system.
We as an industry should join forces in achieving the unified vision.
While we’re still early on in our journey, looking into the new year and beyond I’m optimistic that we’re moving in the right direction. I’m also confident that our efforts around open standards shall help converge the efforts across the industry towards a unified natural way of asking questions about our system. Who knows, perhaps we’ll wake up one day and be able to simply ask: “Siri what’s up with my system?”
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



observability is indeed a significant challenge within the realm of data analytics. The ability to effectively monitor, measure, and understand the behavior of complex systems and processes is crucial for extracting valuable insights from data. Thanks, team for such amazing information. No one is talking about this problem on internet!