

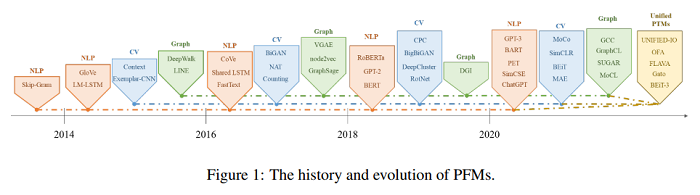
The Pretrained Foundation Models (PFMs) are regarded as the foundation for various downstream tasks with different data modalities. A pretrained foundation model, such as BERT, GPT-3, MAE, DALLE-E, and ChatGPT, is trained on large-scale data which provides a reasonable parameter initialization for a wide range of downstream applications. The idea of pretraining behind PFMs plays an important role in the application of large models. Different from previous methods that apply convolution and recurrent modules for feature extractions, the generative pre-training (GPT) method applies Transformer as the feature extractor and is trained on large datasets with an autoregressive paradigm. Similarly, the BERT apples transformers to train on large datasets as a contextual language model. Recently, the ChatGPT shows promising success on large language models, which applies an autoregressive language model with zero shot or few show prompting. With the extraordinary success of PFMs, AI has made waves in a variety of fields over the past few years. Considerable methods, datasets, and evaluation metrics have been proposed in the literature, the need is raising for an updated survey. This study provides a comprehensive review of recent research advancements, current and future challenges, and opportunities for PFMs in text, image, graph, as well as other data modalities.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: https://twitter.com/InsideBigData1
Join us on LinkedIn: https://www.linkedin.com/company/insidebigdata/
Join us on Facebook: https://www.facebook.com/insideBIGDATANOW



Speak Your Mind