Volante Technologies, a global leader in the provision of innovative financial data integration, today announced that it has enhanced Volante Designer version 5.0 to support the Hadoop® framework.
A Solution for Real-Time Retail Analytics
April 7, 2014 by Leave a Comment
Large Austrian retailer MPREIS has long been using QlikView for business analytics. When the data got too large, the company turned to ParStream to provide immediate query response on billions of records for QlikView’s Direct Discovery. Now the retailer is able to view aggregated and highly detailed information in the same dashboard in real-time. In this use case examination, we’ll take a look at the problem the company faced and the steps taken toward a solution.
A Brief History of Big Data
April 3, 2014 by Leave a Comment

Big data is a relatively new phenomenon comprised of a number of disciplines that contribute to making the technology possible. But have you ever wondered how we got here, how big data evolved over time?
A Mathematical Model for Murder
January 16, 2014 by 1 Comment

A recent paper published in PLos ONE, two UC Irvine mathematicians, Dominik Wodarz and Natalia Komarova, describe an elegant mathematical model to answer just these questions.
2014 Resolutions and Goals for a Storage Technologist
January 7, 2014 by Leave a Comment

“Most technology does some things well, and some things poorly. There is no ‘one thing’ that is the perfect solution for all use cases. As you make your next move, pick gear, software and partners that will first and foremost help solve the problem, don’t worry about what someone else will think of your choice. On more occasions than you think, an “old” technology, such as tape or virtualization, can create a competitive advantage.”
$16.1 Billion Big Data Market: 2014 Predictions From IDC And IIA
December 26, 2013 by Leave a Comment
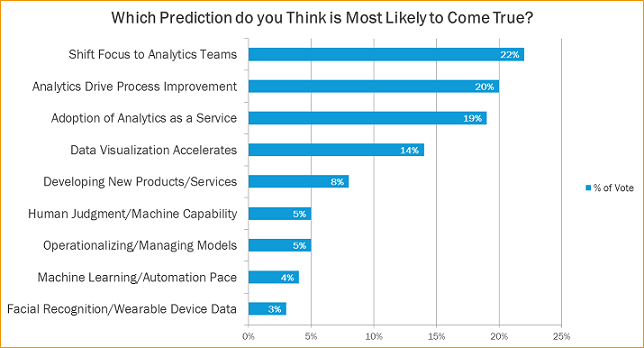
As 2013 draws to a close, it is time for industry analysts and pundits to present their assessments of the year in order to predict where Big Data is headed in 2014. Forbes recently came out with a useful summary of predictions from IDC and IIA which could serve as a balanced road map for […]
A Machine Learning Classifier for Evergreen Content
October 8, 2013 by Leave a Comment
As a technology journalist and data scientist, I frequently find myself in the intersection of two parallel universes. So imagine my delight when I heard about this new Kaggle machine learning competition sponsored by StumbleUpon – build a classifier to categorize webpages as evergreen or non-evergreen. Evergreen content is the jewel of journalism, content that is […]
A Survey of Big Data Definitions
October 4, 2013 by Leave a Comment

As the big data industry continues to steamroll ahead, one conundrum persists – exactly how do you define it? A new report from the MIT Technology Review addresses this issue by examining definitions from IT’s largest players: Gartner, Oracle, Intel and Microsoft. The report offers this observation: And yet ask a chief technology officer to […]
A Lunch with Strangers
September 26, 2013 by Leave a Comment
FIELD REPORT As a member of the Los Angeles Machine Learning Meetup group, I had the distinct pleasure today of having lunch with a bunch of data scientist strangers. This was the 3rd installment of this type of meetup organized by the group and I think it is a very good concept to gather in […]
A Look at Distributed Filesystems: Fraunhofer vs Gluster
June 20, 2013 by 1 Comment
Harry Mangalam from the University of California at Irvine has posted a detailed comparison of the Fraunhofer and Gluster distributed filesystems. Distributed filesystems are those where the files are distributed in whole or in part on different block devices, with direct interaction with client computers to allow IO scaling proportional to the number of servers. […]


