Can Big Data be used to foster serendipity? That’s the premise of an award-winning paper in the 2013 Semantic Web Challenge.
Entitled “Fostering Serendipity through Big Linked Data” the paper was written by Muhammad Saleem, Maulik R. Kamdar, Aftab Iqbal, Shanmukha Sampath, Helena F. Deus and Axel-Cyrille Ngonga Ngomo.

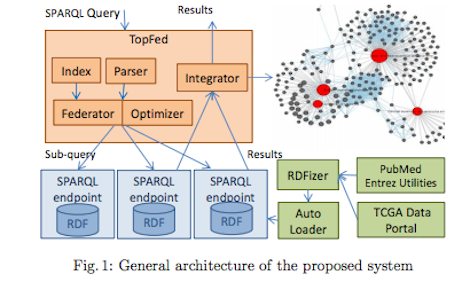
The amount of bio-medical data available over the Web grows exponentially with time. The large volume of the currently available data makes it difficult to explore, while the velocity at which this data changes and the variety of formats in which bio-medical is published makes it difficult to access them in an integrated form. Moreover, the lack of an integrated vocabulary makes querying this data difficult. In this paper,we advocate the use of Linked Data to integrate, query and visualize big bio-medical data. As a proof of concept, we show how the constant flow bio-medical publications can be integrated with the 7.36 billion largeLinked Cancer Genome Atlas dataset (TCGA). Then, we show how we can harness the value hidden in that data by making it easy to explore within a browsing interface. We evaluate the scalability of our approach by comparing the query execution time of our system with that of FedXon Linked TCGA.
The SWC Challenge has progressed over the years from an academic exercise to an event where top industry research and development labs compete with world-leading academic research groups to showcase state of the art in this field. Sponsored by Elsevier, the SWC was first organized in 2003 to showcase the very latest in semantic web technology, and is open to everyone from industry and academia.
Read the Full Story or View the Slides.



Speak Your Mind