

insideBIGDATA Guide to Machine Learning
To help our audience leverage the power of machine learning, the editors of insideBIGDATA have created this weekly article series called “The insideBIGDATA Guide to Machine Learning.” This is our third installment, “R – The Data Scientist’s Choice and Data Access.”
R – The Data Scientist’s Choice
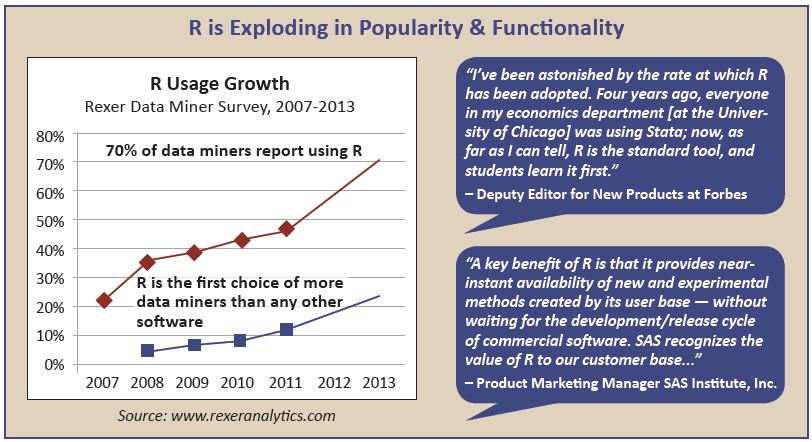
Although there are many choices for performing tasks related to data analysis, data modeling, and machine learning, R has become the overwhelming favorite among data scientists today. In large part this is due to the extensive use of R in academia over commercial products like SAS and SPSS. There are currently spirited debates between the R user community and both the SAS and Python communities as to what is the best tool for data scientists. R has compelling justifications including the availability of free open source R, a widely used extensible language, over 5,000 packages available on CRAN to extend the functionality of R, top-rated visualization capabilities using ggplot2, and a thriving user community with the likes of blog consolidator: r-bloggers.com. The growth of R can be seen in the graphic below:
Here is a short list of facts about R that demonstrate its popularity and growth:
- R is the highest paid IT skill (Dice.com survey, January 2014)
- R is the most-used data science language after SQL (O’Reilly survey, January 2014)
- R is used by 70% of data miners (Rexer survey, October 2013)
- R is #15 of all programming languages (RedMonk language rankings, January 2014)
- R is growing faster than any other data science language (KDNuggets survey, August 2013)
- R is the #1 Google Search for Advanced Analytics software (Google Trends, March 2014)
- R has more than 2 million users worldwide (Oracle estimate, February 2012)
The only issue with R is its inherent limitation as a scalable production environment. R is notoriously memory-based, meaning it can only run on the confines of a single compute environment. It cannot be easily deployed in a distributed computing architecture so big data deployments are not possible. In this guide, we’ll use RRE as an example of a commercial version of R that was specifically designed for big data applications. RRE is composed of a set of big data functions based on Parallel External Memory Algorithms (PEMAs) that run on the following platforms: multicore workstations and servers (including those in the cloud), Windows HPC server clusters, IBM platform LSF clusters, Hadoop clusters and Teradata. The RRE RevoScaleR package contains these high-performance analysis functions.
Data Access
The first step in a machine learning project is to access disparate data sets and bring them into the R environment, typically a data frame object. Thedata frame often serves as the primary argument passed to a machine learning algorithm as its data source. R has a wide range of data access methods such as read.table(), read.csv(), read.xlsx(), readLines(), as well as packages that extend R’s ability to access external data sources, such as RODBC to read SQL databases, and RJSONIO to read JSON files. For unstructured social media data sources, R has packages such as twitteR to read Twitter streams. R offers a high level of flexibility in terms of the types of data sources that can be accessed.
For big data projects, however, open source R bogs down in terms of speed and capacity. There’s only so much data that open source R can accommodate since it keeps all objects in memory. Exactly how many observations can be stored depends on the number of feature variables per observation and the amount of data stored in each variable, e.g. character-based categorical data take up more memory than quantitative variables. Plus, the open source R input routines have not been optimized for best performance so reading in a large data set requires patience.
RRE in contrast, has the RxTextData() big data function to read delimited and fixed format data sets. Other big data access functions are: SPSS with RxSpssData(), SAS with RxSasData(), ODBC databases with RxOdbcData(), and Teradata with RxTeradata(). RRE also offers a highly optimized binary file format called XDF that includes data compression capabilities. Importing data from XDF is the quickest and most efficient method of accessing big data files and getting the data into the R environment.
“The next article in this series will focus on Data Munging. If you prefer you can download the entire insideBIGDATA Guide to Machine Learning, courtesy of Revolution Analytics, by visiting the insideBIGDATA White Paper Library.”



Speak Your Mind