 Unsupervised machine learning techniques have proven useful in identifying fake research papers submitted to the arXiv preprint server. Approximately 500 preprints are receiving daily by the automated repository arXiv, but are not pre-screened by humans. As a result, many nonsense papers generated by software such as SCIgen and Mathgen have been found in the most popular repository used by scientists to share research results. SCIgen was developed in 2005 by researchers at the Massachusetts Institute of Technology (MIT) to prove that conferences would accept meaningless papers. You should give Mathgen a try. It is as easy-as-pi. Just type in your name as author, click a button, and in an instant you have an 8 page, highly complex, research paper in advanced mathematics, including supposed citations to your prior research! Of course the paper is non-sense, but only real mathematics researchers would realize it. Click HERE for my super-duper math paper!
Unsupervised machine learning techniques have proven useful in identifying fake research papers submitted to the arXiv preprint server. Approximately 500 preprints are receiving daily by the automated repository arXiv, but are not pre-screened by humans. As a result, many nonsense papers generated by software such as SCIgen and Mathgen have been found in the most popular repository used by scientists to share research results. SCIgen was developed in 2005 by researchers at the Massachusetts Institute of Technology (MIT) to prove that conferences would accept meaningless papers. You should give Mathgen a try. It is as easy-as-pi. Just type in your name as author, click a button, and in an instant you have an 8 page, highly complex, research paper in advanced mathematics, including supposed citations to your prior research! Of course the paper is non-sense, but only real mathematics researchers would realize it. Click HERE for my super-duper math paper!
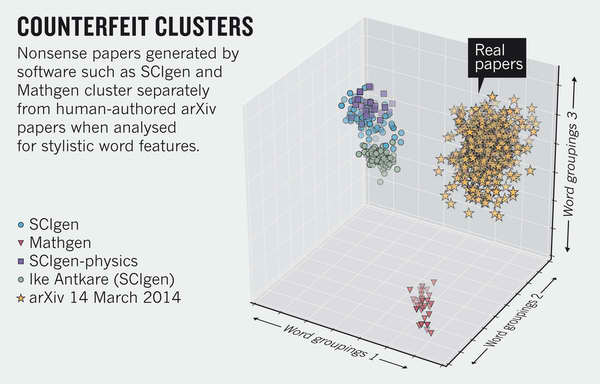
To combat this problem, arXiv uses an automated assessment mechanism that can perform better than human diligence at enforcing standards. The process screens for outliers in arXiv including analysis of the probability distributions of words and their combinations, ensuring that they fall into patterns that are consistent with existing subject classes. This serves as a check of the subject categorization provided by submitters, and helps to detect non-research content.
It was found that fake papers have a native dialect that can be identified by simple stylometric analysis. The most frequent words used in English text, stop words like “and,”, “the, and “of,” encode stylistic features that are independent of content. On average, these words follow a power-law distribution that is evident in even relatively small amounts of text; significant deviations signal outliers.
In the plot above, the effect can be seen in the principal component analysis (PCA) performed. The nonsense papers form tight clusters that are well separated from human-authored articles.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind