
 The Facebook Presto interactive SQL-on-Hadoop engine is now open source. Presto is Facebook’s take on Cloudera’s Impala or Google’s Dremel, and it already has some big-name fans in Airnb and Dropbox.
The Facebook Presto interactive SQL-on-Hadoop engine is now open source. Presto is Facebook’s take on Cloudera’s Impala or Google’s Dremel, and it already has some big-name fans in Airnb and Dropbox.
Presto and the other similar query engines can be viewed as faster versions of Hive, the data warehouse framework for Hadoop that Facebook developed a number of years ago. Facebook and many other Hadoop users still rely heavily on Hive for batch-processing jobs such as management reporting, but recently there has been a demand for a mechanism letting users perform ad hoc, exploratory queries on Hadoop data similar to how they might do them using a massively parallel relational database.
One very attractive characteristic of Presto is that it is 10 times faster than Hive for most queries, according to Facebook software engineer Martin Traverso in a blog post detailing the news.
Under the hood, Presto and Hive are quite different because the former relies on MapReduce to carry out its processing and the latter does not. This is by and large the difference that makes Presto suitable for low-latency queries while the MapReduce-based Hive can take significant time, especially with Facebook’s many petabytes of data, because it must scan everything in the cluster and requires lots of disk writes. Presto also works with a variety of non-HDFS data sources and uses ANSI SQL compared with Hive’s “SQL-like” language. Here is a high-level view of the Presto architecture:
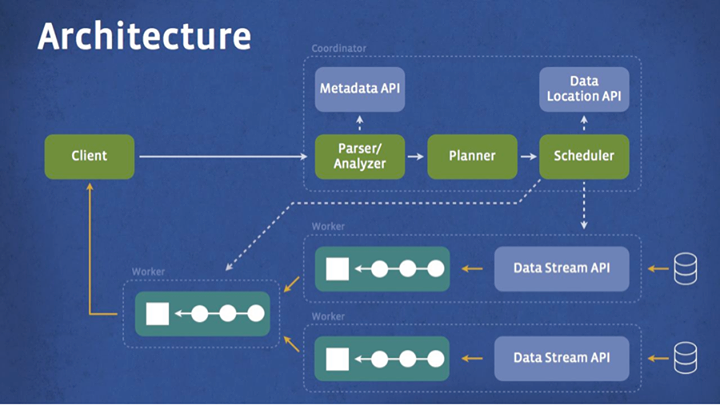
Presto is currently running in numerous Facebook data centers and it is reported the company has scaled a single cluster up to 1,000 nodes. More than 1,000 employees run queries on Presto, and they do more than 30,000 of them per day over a petabyte of data.
Facebook isn’t necessarily looking to compete with other open source SQL projects and it will likely go along using and improving Presto at its own pace regardless what happens in the industry. But increased interest in Presto could inspire the various Hadoop vendors to change their strategies when it comes to the SQL engines they support.



Speak Your Mind