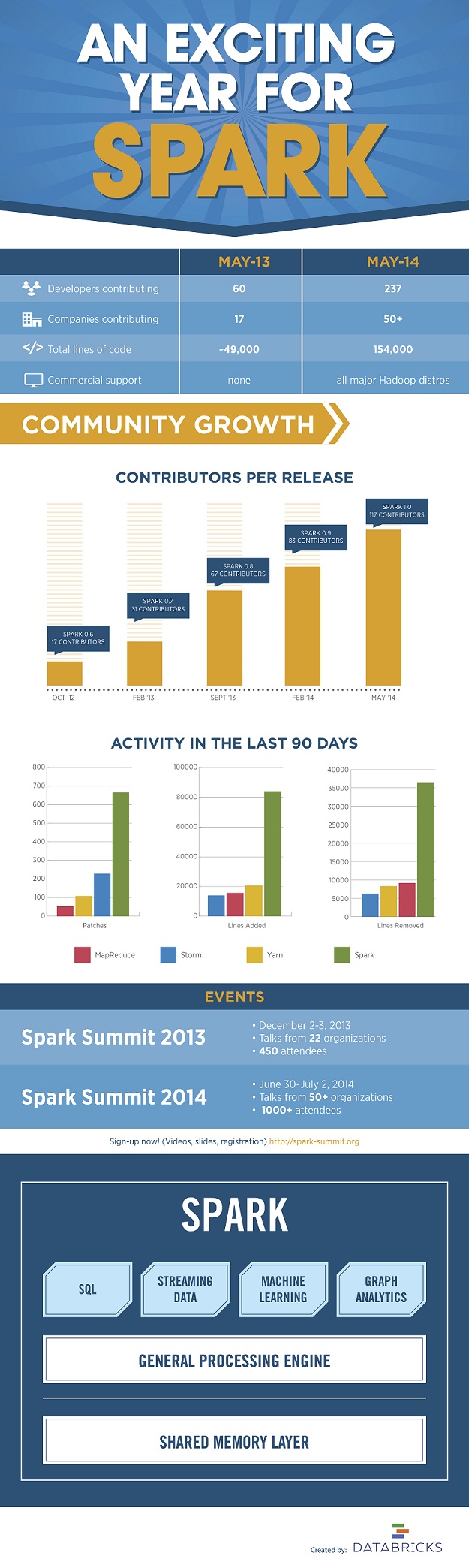
![]() Apache Spark has had an amazing year, and the people behind the open source large-scale data processing engine have pulled some data to show just how fast it has grown in the last 12 months. Databricks, who spun out of AMPlab at UC Berkeley after creating Spark produced the infographic below that highlights some of the data, especially as it catches fire across the industry.
Apache Spark has had an amazing year, and the people behind the open source large-scale data processing engine have pulled some data to show just how fast it has grown in the last 12 months. Databricks, who spun out of AMPlab at UC Berkeley after creating Spark produced the infographic below that highlights some of the data, especially as it catches fire across the industry.
For those new to Spark, it is an open-source data analytics cluster computing framework. Spark fits into the Hadoop open-source community, building on top of the Hadoop Distributed File System (HDFS). However, Spark is not tied to the two-stage MapReduce paradigm, and promises performance up to 100 times faster than Hadoop MapReduce for certain applications. Spark provides primitives for in-memory cluster computing that allows user programs to load data into a cluster’s memory and query it repeatedly, making it well suited to machine learning algorithms.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind