
In this special guest feature, Rob Farber from TechEnablement writes that the Intel Scalable Systems Framework is pushing the boundaries of Machine Learning performance.

Rob Farber, Founder, TechEnablement.com
The challenge of training a machine learning algorithm to accurately solve complex problems requires large amounts of data that greatly increase a system’s computational, memory, and network requirements. Meeting this challenge with the right technology mix amplifies the ability of a system to train machine and deep learning neural networks to solve complex pattern recognition tasks.
To help customers create systems run deep learning—as well as other HPC, Big Data, and visualization workloads—Intel introduced Intel Scalable System Framework (Intel SSF). It provides a common framework that can support workloads running on everything from small workgroup clusters to the world’s largest supercomputers and on-demand cloud computing. The latest information from Intel can be found on the Intel machine learning portal.
Big data is key to accurately training neural networks to solve complex problems. Large amounts of data are required to fit complex surfaces. For example, How Neural Networks Work shows that the neural network is actually fitting a ‘bumpy’ multi-dimensional surface, which means the training data needs to specify the hills and valleys, or points of inflection, on the surface. Not surprisingly, the preprocessing of the training data, especially using unstructured data sets, can be as complex a computational problem as the training itself, which is why the performance, scalability, and adaptability of the data preprocessing workflow is an important part of machine learning.
Parallel distributed computing is a necessary challenge for machine learning as even the TF/s parallelism of a single Intel Xeon and Intel Xeon Phi processor-based workstation is simply not sufficient to accurately train in a reasonable time on many complex machine learning training sets. Instead, numerous computational nodes must be connected together via high-performance, low latency communications fabrics like Intel Omni-Path Architecture (Intel OPA) and Intel Message Passing Interface (Intel MPI).
Intel SSF, which includes Intel OPA, also incorporates a host of other software and hardware technologies to address a balanced approach to the computational, memory, and network challenges that machine or deep learning present: Intel Optane SSDs built on 3D XPoint technology, and new Intel Silicon Photonics, Intel Xeon processors, Intel Xeon Phi processors, and Intel Enterprise Edition for Lustre software.
Customer feedback and optimized software
The key Kyoto University observed, is to provide equivalently optimized software to GPUs. Benchmarks (two are shown below) demonstrate that a dual-socket Intel Xeon processor E5 (formerly known as Haswell) can outperform an NVIDIA K40 GPU on a large Deep Belief Network (DBN) benchmark and when using the popular Theano machine-learning package.
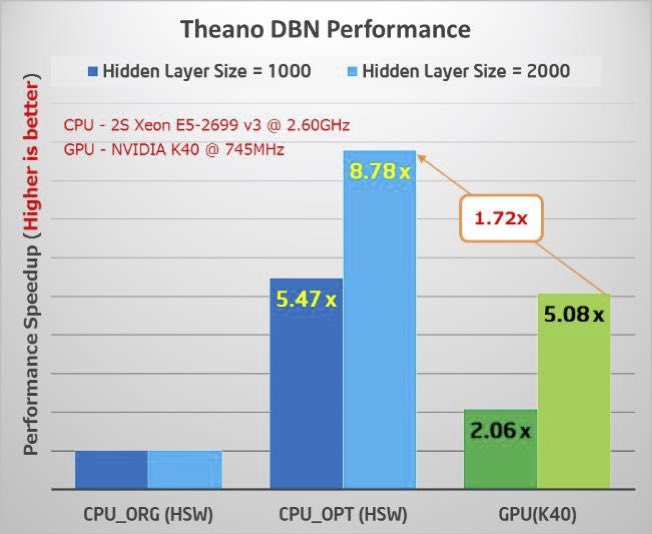
Figure 1: Original vs optimized performance relative to a GPU. The middle bar is the optimized performance (Higher is better) (Source: Intel Corporation)

Figure 2: Speedup of optimized Theano relative to GPU plus impact of the larger Intel Xeon processor memory capacity. (Source: Kyoto University)
Intel Xeon Phi Processor
Computational nodes based on the new Intel Xeon Phi processors further accelerate both memory bandwidth and computationally limited machine learning algorithms as these processors greatly increase floating-point performance while on package MCDRAM (available on some devices) greatly increases memory bandwidth [1].
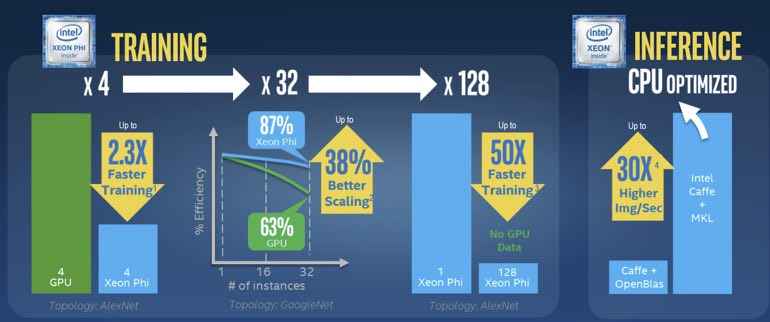
Figure 3: ISC’16 benchmarks showing superior performance of Intel Xeon Phi processor compared to GPUs for deep learning
Intel Omni-Path Architecture
For data transport, the Intel OPA specifications hold exciting implications for machine-learning applications as it promises to speed the training of distributed machine learning algorithms through: (a) a 4.6x improvement in small message throughput over the previous generation fabric technology, (b) a 65ns decrease in switch latency (think how all those latencies add up across all the switches in a big network), and (c) by providing a 100 Gb/s network bandwidth [2} to speed the broadcast of millions of deep-learning network parameters to all the nodes in the computational cluster (or cloud) plus minimize startup time when loading large training data sets.
![Figure 4: Intel(R) OPA is designed to reduce network costs (Source: Intel Corporation [3])](http://insidebigdata.com/wp-content/uploads/2016/08/4.jpg)
Figure 4: Intel(R) OPA is designed to reduce network costs (Source: Intel Corporation [3])
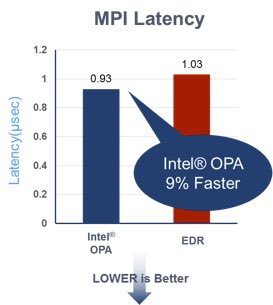
Figure 5: MPI Latency (Source: Intel Corporation)
The Intel OPA performance goals have been proven in practice according to recent benchmark results.
- Lower MPI Latency: Compared to EDR InfiniBand, Intel® OPA demonstrates lower MPI latency* according to the Ohio State Microbenchmarks.
- Higher MPI message rate: Intel OPA also demonstrates a better (e.g. higher) MPI message rate* on the Ohio State Microbenchmarks. The test measurements included one switch hop.
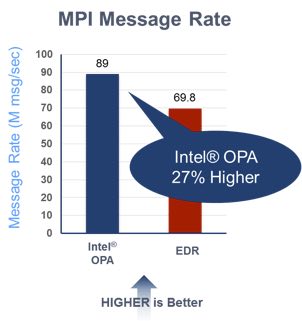
Figure 6: MPI Message Rate (Source: Intel Corporation)
- Lower latency at scale: Tests results show that Intel OPA demonstrates better latency than EDR at scale*.
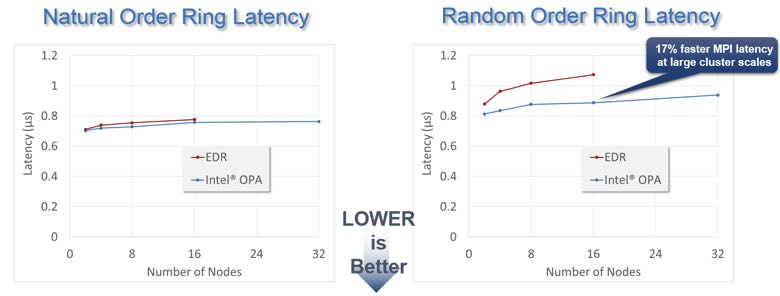
Figure 7: Latency as a function of number of nodes (Source: Intel Corporation)
- Lower CPU utilization: It’s also important that communication not consume CPU resources that can be used for training and other HPC applications. As shown in the Intel measurements*, Intel OPA is far less CPU intensive.
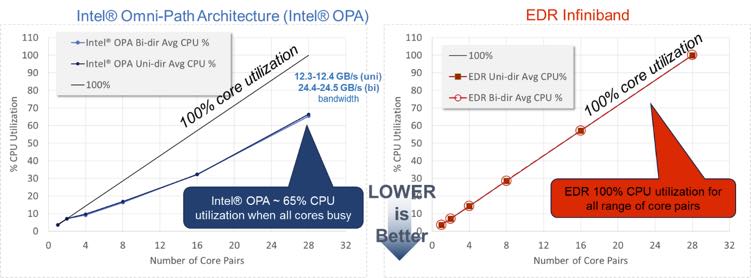
Figure 8: CPU utilization during the osu_mbw_mr message rate test (Source: Intel Corporation)
Intel Solutions for Lustre software
Intel Enterprise Edition for Lustre software is intended to help data scientists (and HPC scientists in general) manage their data in a global storage namespace plus utilize both storage and network hardware resources for high-performance and high-reliability so those same data scientists can always access their data quickly.
Succinctly, machine learning and other data-intensive HPC workloads cannot scale unless the storage filesystem can scale to meet the increased demands for data. This includes the heavy demands imposed by data preprocessing for machine learning (as well as other HPC problems) as well as the fast load of large data sets during restart operations. These requirements make Lustre – the de facto high-performance filesystem – a core component in any machine learning framework.

Figure 9: Lustre provides support for both data center and cloud based HPC applications (Source: Intel Corporation)
Intel MPI
Intel MPI provides programmers a “drop-in” MPICH replacement library that can deliver the performance benefits of the Intel Omni-Path Architecture communications fabric plus high core count Intel Xeon and Intel Xeon Phi processors. Tests have verified the scalability of the Intel MPI implementation to 340,000 MPI ranks [4] where a rank is a separate MPI process that can run on a single core or an individual system. Other communications fabrics such as InfiniBand are supported plus programmers can recompile their applications to use the Intel MPI library.
MPI is a key communications layer for many scientific and commercial applications including machine and deep learning applications. In general, all distributed communications pass through the MPI API (Application Programming Interface), which means compliance and performance at scale are both critical.
The Intel MPI team has spent a significant amount of time tuning the Intel MPI library to different processor families plus network types and topologies including Intel OPA, Intel Xeon processors, and Intel Xeon Phi processors. This includes optimizing the use of shared memory on high core count processors as data can be shared between cores without the need for a copy operation. DMA mapped memory and RDMA (Remote Direct Memory Access) operations are also utilized to prevent excess data movement.
The following graph shows how the Intel MPI team has achieved an 18.24x improvement over OpenMPI. This added performance can help to speed the training of deep and very-deep image recognition neural networks. In particular, the 524,288 message size can broadcast the parameters for big convolutional neural networks.
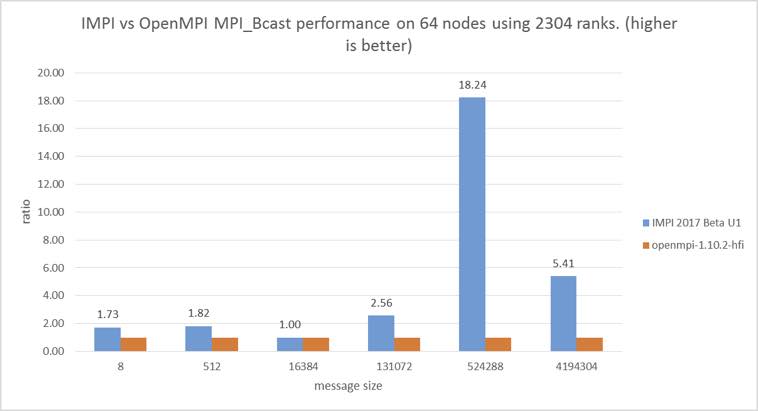
Figure 10: MPI Broadcast performance relative to message size (Source: Intel Corporation)
The Intel MPI team has tuned the reduction operations (key to deep and machine learning) to deliver greater performance than the OpenMPI MPI_Reduce() implementation. Reductions are particularly tricky to optimize as they tend to be latency rather than bandwidth limited and utilize small messages.
The following graph shows a 1.34x performance improvement when using the Intel MPI library as opposed to OpenMPI. For reduction limited applications, this translates to a significant time-to-model improvement simply by “dropping in” the Intel MPI library for MPICH compatible binaries (or simply recompile to transition from non-MPICH libraries like OpenMPI).

Figure 11: Reduction performance of Intel MPI relative to OpenMPI (Source: Intel Corporation)
Intel libraries
Feedback from customers has motivated the development of optimized libraries that are included in Intel SSF. Much of this work has been contributed by Intel back to the open-source community. For example, the Intel Data Analytics Acceleration Library (Intel DAAL) offers faster ready-to-use high-level algorithms plus Intel Math Kernel Library (Intel MKL) that provides lower-level primitive functions to speed data analysis and machine learning. These libraries can be called from any big-data framework and use communications schemes like Hadoop and MPI. More about them can be seen in the video, “Faster Machine Learning and Data Analytics Using Intel® Performance Libraries.”
Figure 12: An important building block for machine learning and data analytic applications (Source: Intel Corporation)
Summary
Training a machine learning algorithm to accurately solve complex problems requires large amounts of data that greatly increases the computational, memory, and network requirements. With the right technology mix as illustrated by Intel SSF, machine and deep learning neural networks can be trained to solve complex pattern recognition tasks – sometimes even better than humans.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He can be reached at info@techenablement.com.
[1] Vector Peak Perf: 3+TF DP and 6+TF SP Flops Scalar Perf: ~3x over Knights Corner Streams Triad (GB/s): MCDRAM : 400+; DDR: 90+; See slide 4 http://www.hotchips.org/wp-content/uploads/hc_archives/hc27/HC27.25-Tuesday-Epub/HC27.25.70-Processors-Epub/HC27.25.710-Knights-Landing-Sodani-Intel.pdf.
[3] See Figure 1 in Transforming the Economics of HPC Fabrics with Intel® Omni-Path Architecture.
[4] See https://software.intel.com/en-us/intel-mpi-library/details.
* Product and Performance Information can be found at http://www.intel.com/content/www/us/en/benchmarks/intel-data-center-performance.html.



Speak Your Mind