
This article is the fifth and last in an editorial series that will provide direction for enterprise thought leaders on ways of leveraging in-memory computing to analyze data faster, improve the quality of business decisions, and use the insight to increase customer satisfaction and sales performance.
In last week’s article, we provided benchmarks that supported the viewpoint that IMC establishes a framework for: more data, more speed, more efficiency.
 GridGain In-Memory Data Fabric
GridGain In-Memory Data Fabric
Now that we’ve taken a tour of the IMC technology and business landscape, let’s evaluate a leading open-source product offering by GridGain Systems, Inc. (www.gridgain.com). As we discussed earlier in this Guide, In-Memory Computing is characterized by using high-performance, integrated, distributed memory systems to compute and transact on large scale data sets in real-time, orders of magnitude faster than possible with traditional disk-based or flash technologies. GridGain’s solution provides state-of-the-art technology to expertly align with these characterizations and much more. GraidGain was named by Gartner as one of the “Cool Vendors in In-Memory Computing Technologies” for 2014.
The technology backdrop for the IMC industry is basically a series of point solutions such as inmemory databases, in-memory data grids, in-memory streaming, etc. With the new GridGain In-Memory Data Fabric, these components are all under one central architecture. The logic for combining a collection of point solutions under a single cohesive platform is clear—they all share the same learning curve, same API, same configuration, same security, same product features. Now all of these important pieces are part of a central fabric.
Why is a data fabric an important advantage over individual point solutions? Point solutions are important in the beginning because they address specific customer problems. A complete platform might not be a priority at this early stage. But eventually you have a whole class of related problems, and you don’t need a point solution for each one, instead you need a more systematic, fabric kind of approach.
GridGain historically has been a point solution provider. Look back a couple of years, the company had an IMDG product, an IMHPC product, an in-memory streaming product, and recently a Hadoop product. Now the company is moving toward an in-memory data fabric based on all the previously mentioned drivers and benefits. It is a single comprehensive fabric that an organization can adopt to address all different types of data access and data processing problems. It has transactional capabilities to run transactional payloads in-memory in a highly distributed environment. It has analytical capabilities to run analytical payloads, i.e. non-transactional Hadoop based payloads such as MapReduce. You can run traditional HPC payloads. You also have support for streaming payloads that have very different types of algorithms designed to process this type of data.
When an organization uses the GridGain In-Memory Data Fabric, it is not limited to one particular type of use case, data type or application. Any type of data processing is possible in-memory with tremendous performance and scalability. This is what a comprehensive in-memory data fabric is all about: Access and process data from any data store—relational, NoSQL, Hadoop—for any application (Java, .NET, C++).
GridGain’s IMC solutions are designed to deliver uncompromised performance by providing developers with a comprehensive set of APIs. Developed for the most demanding use cases, including sub-millisecond SLAs, core platform products allow you to programmatically fine-tune
performance on large and super-large network topologies with hundreds to thousands of nodes.
The open-source project of the GridGain In-Memory Data Fabric is licensed under Apache 2.0 and is hosted on GitHub where you can review code, learn GridGain internals, and file and review issues. Developers may find it beneficial to look under the hood to understand details, programming style or specifics of implementations.
GridGain understands that In-Memory Computing is more than the latest tech trend. It’s the next major paradigm shift for an increasingly data-centric business world in which organizations face problems that traditional technology can’t even fathom, much less solve. IMC is a step all
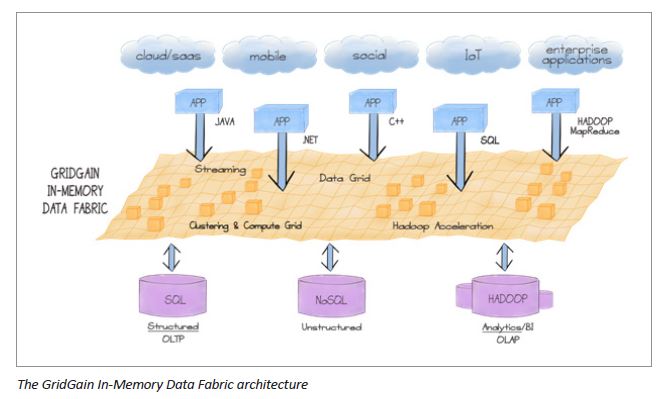
organizations must take to remain competitive. The following graphic illustrates the new GridGain In-Memory Data Fabric architecture.
The GridGain In-Memory Data Fabric includes the following unified functional areas: data grid, HPC, streaming, and Hadoop connector. All functional areas were re-engineered and are now fully integrated under the new data fabric architecture—combining all the GridGain technologies into a new cohesive whole. In the following sections, we’ll examine each functional area in more detail.
Data Fabric Feature: Data Grid
With its In-Memory Data Fabric, GridGain offers industry leading data grid functionality characterized by the fact that data are stored in-memory as opposed to traditional DBMS software that utilizes disk as the primary storage mechanism. By utilizing system memory rather than spinning disk, data grids are typically orders of magnitude faster than traditional DBMS systems. The GridGain data grid feature supports standard SQL for querying in-memory data including support for distributed SQL joins.
GridGain’s data grid feature contains an impressive feature set including—Hyper Clustering™, Zero Deployment™, advanced security, fault tolerance, topology resolutions, load balancing, collision resolutions, connected jobs, local node storage and much more. In a clustered in-memory solution like GridGain’s, the collection of all individual node memory can be used as a single, expansive “grid” of virtually connected memory. Large data sets can be effectively partitioned across all nodes for high-end scalability, and computations can be intelligently parallelized for optimal processing speed. At a fundamental level, GridGain enables promoting data up from residing in slow mechanical storage
systems to fast memory. GridGain’s data grid feature solves many critical IT pain-points at once:
- Performance
- Scalability
- High availability
- Data consistency and reliability
- Detailed insight and management
Data Fabric Feature: Real-time Streaming
To address the needs of a large family of applications for which traditional processing methods and disk-based storage, like databases or file systems, fall short—the GridGain In-Memory Data Fabric offers stream-processing capabilities. In-memory streaming combines both event workflow and Complex Event Processing (CEP) capabilities fully integrated in one product.
Processing of market feeds, electronic trading by many financial companies on Wall Street, security and fraud detection, military data analysis—all these applications produce large amounts of data at very fast rates and require appropriate infrastructure capable of processing data in real-time without blockages.
One of the most common use cases for stream processing is the ability to control and properly pipeline distributed events workflow. As events
are coming into the system at high rates, the processing of events is split into multiple stages and each stage has to be properly routed within a
cluster for processing.
One of the key features of many CEP systems is the ability to control the scope of operations on streamed data. As streaming data never ends, an application must be able to provide a size limit or a time boundary on how far back each request or each query should go.
Data Fabric Feature: Hadoop Acceleration
With its In-Memory Data Fabric, GridGain offers Hadoop acceleration as well as a standalone In-Memory Accelerator for Hadoop built on top of the In-Memory Data Fabric, which expand the benefits of IMC to the Hadoop world by enabling enterprises to achieve unmatched performance and scale with their existing MapReduce applications. All this is possible without requiring any code change to the native MapReduce, HDFS and YARN environment.
Prior to this offering, running IMC in an existing Hadoop environment required code changes to the application, reducing organization’s ability
to quickly derive the full performance benefits of an in-memory architecture. The In-Memory Accelerator for Hadoop allows for true plug and play deployment, meaning that within minutes of download, developers can deliver up to 10x performance improvement on their Map/Reduce
applications.
GridGain’s Hadoop acceleration is based on dual-mode, high-performance in-memory file system that is 100% compatible with Hadoop HDFS—and an in-memory optimized MapReduce implementation. GridGain’s in-memory MapReduce effectively parallelizes the processing of in-memory data stored in GGFS. It eliminates the overhead associated with job tracker and task trackers in a standard Hadoop architecture while providing lowlatency, HPC-style distributed processing.
By enabling companies to more readily leverage in-memory performance at scale for their Hadoop clusters, GridGain is extending the benefits of its proven IMC platform to a larger enterprise community.
If you prefer the complete insideBIGDATA Guide to In-Memory Computing is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of GridGain.



Speak Your Mind