Sponsored Post
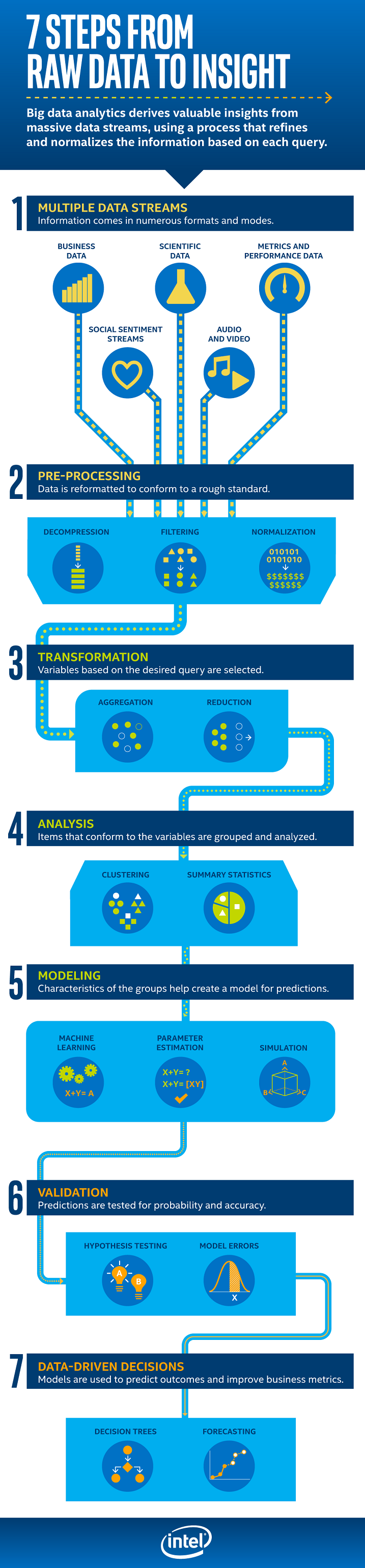
Data scientists generally ascribe to the “machine learning process” which is seen as a roadmap to follow when working on a data science project. The infographic at the end of this article provides a detailed work flow that it is general enough to encompass pretty much any data science project. Let’s drill down into each of the “7 steps from raw data to insight” to get a sense for how to approach this important process.
Step 1: Multiple data streams – where information comes in from numerous source and formats. The data for analysis may come from a data warehouse, data mart, data lake, or even Internet-of-Things (IoT) sensors. In some cases, the data may be an extract from a production systems, e.g. an e-commerce application. More and more these days, the data for machine learning projects come from a variety of source including unstructured sources such as social media.
Step 2: Pre-processing – often considered part of the early data wrangling (also known as munging) stage, this step involves the reformatting of raw data into a form more suitable for machine learning.
Step 3: Transformation – is very important early on in the project in order to clean and transform and the data into a form that makes sense for the machine learning problem being solved. Given the state of some enterprise data (dirty, inconsistent, missing values, etc.), this step may take considerable time and effort.
Step 4: Analysis – sometimes referred to as “exploratory data analysis” or EDA. This is when you use statistical methods and data visualizations to discover interesting characteristics and patterns in the data. Sometimes simple plots of raw data can reveal very important insights that will help dictate a direction for the project or at least provide critical insight that can be useful when interpreting the results of the machine learning project.
Step 5: Modeling – you should choose the machine learning model appropriate for the problem being solved. At this stage you need to make a commitment to the type of machine learning you’ll use. Are you going to make a quantitative prediction, a qualitative classification, or are you just exploring using a clustering technique?
[clickToTweet tweet=”7 Steps From Raw Data to Insight – the ‘machine learning’ process detailed” quote=”The infographic provides a detailed work flow that it is general enough to encompass pretty much any data science project. “]
Step 6: Validation – it is important to evaluate which method produces the best results for any given data set. Selecting the best approach can be one of the most challenging parts of machine learning in practice. As a result, performance evaluation of a model is critical to the success of the project. You need to measure how well its predictions actually match the observed data.
Step 7: Data-driven Decisions – this final step is when you engage “data story telling” in order to communicate the final results of the project. Often the final results of a machine learning project can best be understood with well-crafted visualizations that capture the essence of what the model is telling you about the data.



Speak Your Mind