![]() Unravel Data, the Application Performance Management (APM) platform designed for Big Data, announced that it has integrated support for Cloudera Impala and Apache Kafka into its platform, allowing users to derive the maximum value from those applications. Unravel continues to offer the only full-stack solution that doesn’t just monitor and unify system-level data, but rather tracks, correlates, and interprets performance data across the full-stack in order to optimize, troubleshoot, and analyze from a single pane. Following closely on the heels of its recent announcement of Unravel 4.0, the platform continues to advance in its support of industry’s leading mission-critical big data applications.
Unravel Data, the Application Performance Management (APM) platform designed for Big Data, announced that it has integrated support for Cloudera Impala and Apache Kafka into its platform, allowing users to derive the maximum value from those applications. Unravel continues to offer the only full-stack solution that doesn’t just monitor and unify system-level data, but rather tracks, correlates, and interprets performance data across the full-stack in order to optimize, troubleshoot, and analyze from a single pane. Following closely on the heels of its recent announcement of Unravel 4.0, the platform continues to advance in its support of industry’s leading mission-critical big data applications.
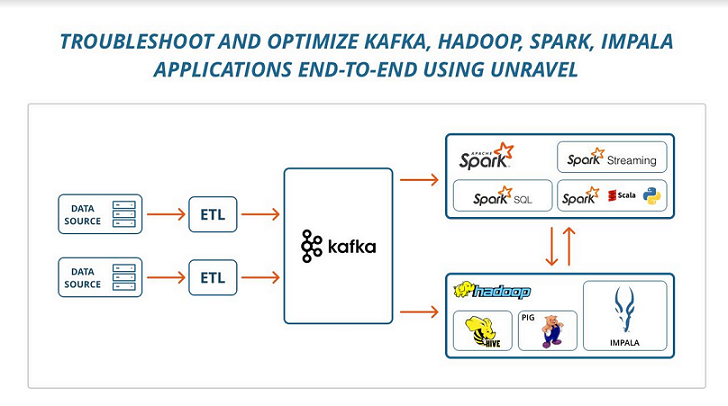
Impala and Kafka have become critical applications on the Big Data stack. As companies continue to adopt multiple Big Data technologies for their needs, the complexity and time required to diagnose and resolve performance problems has grown exponentially. The challenge is to take an application-first approach to manage a single view of performance within and across the many components of the stack that underpin applications like ETL, Machine Learning, and analytics. Unravel was the first company—and remains the only company—to tackle this challenge across the Big Data stack.
Impala
Cloudera Impala is an SQL query engine that runs on Apache Hadoop. It brings scalable parallel database technology to Hadoop, enabling users to issue low-latency SQL queries to data stored in HDFS and Apache HBase without requiring data movement or transformation. But Impala queries too often fail due to poor performance.
Unravel for Impala boosts query performance and improves reliability. Unravel provides visuals and deep analysis for Impala queries helping users understand quickly why their query is slow. Unravel automatically tunes Impala queries for the best performance by considering many possible root causes of query slowdown and taking autonomous measures to improve query performance. For example, resource contention on some Impala workers, memory allocation problems, excessive data spilling, suboptimal join processing, presence of data skew, poor choice of data partitioning, storage, or caching, and many others.
Unravel also enables users to understand the true multi-tenant nature of their Impala workloads, helping them to avoid hotspots and failures.
With Unravel, users can quickly understand bottlenecks and causes of unpredictable performance in their Impala-based applications, allowing them to deliver on their SLAs (Service Level Agreements). Users can also identify which SQL queries from engines such as Hive or Spark are good candidates for running in Impala, and which queries are not.
Kafka
Apache Kafka is an open-source stream processing platform that aims to provide a unified, high-throughput, low-latency methodology for handling real-time data feeds. Kafka has seen surging adoption—in fact, in a recent survey, 86 percent of respondents indicated that they were increasing their Kafka use. However, because Kafka is widely integrated into enterprise-level infrastructures, monitoring Kafka performance at scale has become an increasingly important issue.
In addition, while Big Data applications use Kafka as a data source for a variety of use cases (such as ingesting data into clusters, live data feeds to enable real-time processing, and replicating input data across clusters and data centers to provide 24×7 application uptime), managing these applications has become problematical. Today, problems with Kafka can arise at the level of applications and multi-tenant infrastructures, but also within Kafka itself.
Unravel for Kafka manages not only the performance, but also the predictability and reliability, of Kafka-based applications. For example, it correlates application KPIs with infrastructure and Kafka performance metrics, allowing rapid problem diagnosis in general as well as fast failure detection for Kafka-based applications.
In addition, Unravel troubleshoots and tunes applications that are unable to keep up with input data rates in Kafka. Unravel also remediates load imbalances in Kafka caused by factors such as poor data partitioning or multi-tenancy. And because Unravel understands resource allocation on the stack, it helps in planning Kafka capacity, which is critical to meeting application SLAs.
There are arguably two forces at work in the evolution of Big Data,” said Kunal Agarwal. “First is the proliferation of applications—such as Hadoop and Spark, and now Impala and Kafka—each with its own role in parsing, ingesting, or analyzing data to help owners of that data profit from it. Second is the growing number of interactions between apps on the stack, which are multiplying almost geometrically. In such an environment, something will break—in fact, it’s bound to break. Big Data practitioners come to the table with that understanding, and yet they have no tools to cope with that complexity. And the challenges continue to multiply with the exponential growth of data in most organizations. Unravel Data—from conception, to launch, to mainstream adoption by users—is helping users find their way in making Big Data live up to its promise.”
Availability
Unravel 4.0, with support for Impala and Kafka, is available now. Companies such as Autodesk and YP.com are already using Unravel Data to manage the performance of their production Big Data systems. Unravel Data is available immediately for on-premises, cloud or hybrid Big Data deployments. Unravel Data currently supports Hadoop, Spark and Kafka, with plans to add support for other systems such as for data ingestion (Storm, Flume), NoSQL systems (Cassandra, HBase) and MPP systems (Impala, Drill). Unravel Data fully supports secure deployments with Kerberos, Apache Sentry, Encryption, etc.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind