![]() FIELD REPORT
FIELD REPORT
In this field report, I wanted to share the insideBIGDATA experience last week at the Strata Data Conference 2017 in New York City, September 25-28, sponsored by O’Reilly and Cloudera. These shows are always recognized extravaganzas and never disappoint with respect to the technology being showcased. Many members of the big data vendor ecosystem wait for Strata to release their biggest announcements. We take the opportunity to attend Strata (with a little stealth) to get a behind-the-scenes pulse of the industry. This edition of Strata served this purpose well. With tech eyes wide open, and conducting top-level meetings we were able to find a number of exciting developments that I will summarize here in our special “Strata Data Conference Roundup.”
The sheer quantity of news flow for this Strata was somewhat overwhelming, so to help you make sense of it all, below is a series of vignettes that highlight breaking news items that we feel are important for our readers. We’ve organized the announcements by categories or your convenience. I hope you’ll feel like you were on the exhibition floor! Enjoy.
Daniel – Managing Editor, insideBIGDATA
AI, Deep Learning and GPU Acceleration
BlueData®, provider of the leading Big-Data-as-a-Service (BDaaS) software platform, announced the new fall release for BlueData EPIC™ and introduced initial availability on Google Cloud Platform (GCP) and Microsoft Azure. This release adds new innovations and options for running Hadoop, Spark, and other Big Data workloads on Docker containers — delivering on the requirements from its rapidly growing customer base, including many of the world’s largest enterprises across multiple industries. This new fall release builds on the innovative functionality introduced in BlueData EPIC version 3.0, with support for deep learning use cases, GPU support, and flexible container placement policies. And by extending availability of BlueData EPIC from Amazon Web Services (AWS) to Azure and GCP, BlueData is the first and only BDaaS solution that can be deployed on-premises, in the public cloud, or in hybrid and multi-cloud architectures.
H2O.ai announced an offering built on NVIDIA DGX Systems to further democratize machine learning and address the growing demands placed on a limited number of trained data scientists. Traditional approaches to machine learning require organizations to rely on highly skilled data scientists with years of domain knowledge. These experts continuously experiment to discover features that make machine learning algorithms more accurate and interpretable for business teams to consume. With most of the world’s elite data scientists flocking to Software AI giants, there is a vacuum in the diverse talent needed to transform businesses with AI.
H2O.ai’s Driverless AI platform fully integrated on NVIDIA DGX systems, lets business users, analysts and data scientists use an incredibly fast, intuitive computing platform. Now customers can apply Automatic Feature Engineering and quickly develop hundreds of machine learning models to help businesses mitigate risks and maximize revenue potential. Driverless AI offers the first of its kind model interpretability to explain model accuracy and predictions transparently.
For example, with this new solution, banks can build pipelines and engineer thousands of features to reduce false positives in anti-money laundering or credit scores with lightning speed to make credit decisions on the spot. Likewise, online retailers can analyze consumer behavior as it happens to optimize order fulfillment and minimize shipping costs.
H2O.ai’s GPU-accelerated algorithms are optimized for NVIDIA DGX systems – a portfolio of purpose-built AI supercomputers that serve as the essential tool of leading-edge AI development. DGX systems feature an integrated software stack that enables organizations to get the fastest start in AI and the world’s most advanced data center GPU, the NVIDIA® Tesla® V100. NVIDIA DGX systems running H2O.ai’s Driverless AI deliver effortless productivity for business, with time-critical, accurate and explainable predictions in hours instead of days.
NVIDIA (NASDAQ: NVDA) and its systems partners Dell EMC, Hewlett Packard Enterprise, IBM and Supermicro unveiled more than 10 servers featuring NVIDIA® Volta architecture-based Tesla® V100 GPU accelerators — the world’s most advanced GPUs for AI and other compute-intensive workloads. NVIDIA V100 GPUs, with more than 120 teraflops of deep learning performance per GPU, are uniquely designed to deliver the computing performance required for AI deep learning training and inferencing, high performance computing, accelerated analytics and other demanding workloads. A single Volta GPU offers the equivalent performance of 100 CPUs, enabling data scientists, researchers and engineers to tackle challenges that were once impossible. Seizing on the AI computing capabilities offered by NVIDIA’s latest GPUs, Dell EMC, HPE, IBM and Supermicro are bringing to the global market a broad range of multi-V100 GPU systems in a variety of configurations.
 Pure Storage® (NYSE: PSTG), a leading independent all-flash data platform vendor for the cloud era, announced significant customer momentum for FlashBlade™, the industry’s first system purpose-built for modern analytics. Since general availability in January 2017, FlashBlade has gained traction among organizations running and innovating with emerging workloads, specifically modern analytics, artificial intelligence (AI) and machine learning (ML). Data is at the center of the modern analytics revolution. Large amounts of data must be delivered to the parallel processors, like multi-core CPUs and GPUs, at incredibly high speeds in order to train machine learning and analytic algorithms faster and more accurately. Today, most machine learning production is undertaken by hyperscalers and large, web-scale companies. Recently, however, ML has moved to the forefront in numerous industries. In the automotive industry, where the global race to market the first autonomous vehicles has heated up, ML has become the de facto approach. In finance, organizations are implementing AI and ML to automate trades, understand credit exposure and manage risk. In healthcare research, analysis of MRI images can pick out genetic markers in brain tumors that are invisible to the naked eye to assist medical professionals in clinical diagnosis. FlashBlade, which is optimized for any and all unstructured workloads, is best positioned to accelerate modern emerging workloads for the world’s most innovative organizations.
Pure Storage® (NYSE: PSTG), a leading independent all-flash data platform vendor for the cloud era, announced significant customer momentum for FlashBlade™, the industry’s first system purpose-built for modern analytics. Since general availability in January 2017, FlashBlade has gained traction among organizations running and innovating with emerging workloads, specifically modern analytics, artificial intelligence (AI) and machine learning (ML). Data is at the center of the modern analytics revolution. Large amounts of data must be delivered to the parallel processors, like multi-core CPUs and GPUs, at incredibly high speeds in order to train machine learning and analytic algorithms faster and more accurately. Today, most machine learning production is undertaken by hyperscalers and large, web-scale companies. Recently, however, ML has moved to the forefront in numerous industries. In the automotive industry, where the global race to market the first autonomous vehicles has heated up, ML has become the de facto approach. In finance, organizations are implementing AI and ML to automate trades, understand credit exposure and manage risk. In healthcare research, analysis of MRI images can pick out genetic markers in brain tumors that are invisible to the naked eye to assist medical professionals in clinical diagnosis. FlashBlade, which is optimized for any and all unstructured workloads, is best positioned to accelerate modern emerging workloads for the world’s most innovative organizations.
Big Data
Paxata, the pioneer and leader in empowering all business consumers to intelligently transform raw data into ready information instantaneously, announced the early availability of Paxata’s Intelligent Ingest as part of its next major release of the company’s award-winning Adaptive Information Platform. The new automated ingest capabilities will significantly simplify the ability for business consumers to swiftly incorporate data from any cloud or format to prepare data for business analysis.
iguazio, a leading data platform for continuous analytics and event driven-applications, announced the general availability of its Unified Data Platform. iguazio simplifies data pipeline complexities while providing a turnkey solution to accelerate the development and deployment of machine learning and artificial intelligence in the enterprise, generating fresh insights in real-time. The iguazio Unified Data Platform comes with fully integrated essential applications dynamically deployed over Kubernetes, including artificial intelligence and machine learning frameworks like Spark, R and TensorFlow, visualization and a real-time serverless framework. iguazio’s solution enables the entire continuum of analytics – including predictive and prescriptive analytics – through the ingestion and enrichment of streams, objects, files and database records.
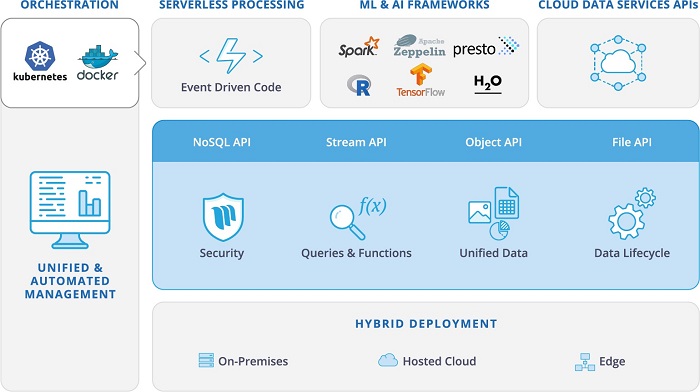
The iguazio Unified Data Platform
Qubole, the big data-as-a-service company, announced deeper integration with Microsoft Azure. Now, Qubole Data Service (QDS) supports Microsoft Azure Data Lake Store and adds workload aware auto-scaling capabilities that leverage Azure’s minute-based billing model for an up to 66 percent reduction in total cost of ownership (TCO). The Qubole platform leverages a range of big data intelligent solutions, including artificial intelligence (AI) and machine learning (ML) technologies to deliver a more accessible way to perform big data analytics on data stored in Azure. QDS’ native support for Microsoft Azure Data Lake Store provides a seamless way to perform analytics on Microsoft’s high-performance, scalable data store and is fully compliant with the Azure security framework. Big data workloads tend to be “bursty.” The amount of compute required can vary greatly over time. Azure cloud supports per-minute billing and when combined with QDS’ unique workload aware auto-scaling, creates a precise way to reduce wasted compute, lowering TCO by as much as 66 percent.
Databases, Data Warehouses, Data Lakes
Cambridge Semantics, leading provider of big data management and analytics solutions, announced the release of Anzo Smart Data Lake® (ASDL) 4.0, its flagship platform product that builds a semantic layer at scale on all enterprise data and empowers users to extract powerful insights at record speed. Incorporating several new technical advancements designed to deliver a generational shift over current data lake, data management and data analytics offerings. ASDL 4.0 offers an end-to-end, enterprise-scale open platform that creates a single semantic layer of an organization’s structured and unstructured data. The platform is designed to break down the IT barriers that can cost enterprises millions of dollars in lost opportunities by slowing down or blocking data access.
 MapR Technologies, Inc., a leader in delivering one platform for all types of data across every cloud, announced breakthrough database innovations for rich data-intensive applications. With new advancements for developers that enable rich applications, in-place and continuous machine learning/AI and SQL capabilities, and global real-time data integration and microservices support, MapR continues to push the boundaries of data management. As part of the MapR Converged Data Platform, MapR-DB enables faster time-to-market, always-on intelligent business processes and contextual user experiences. MapR-DB supports multiple data models (document, wide column, key value, etc.) and unifies operations and analytics for in-place and continuous real time business insights. MapR-DB can operate thousands of mission critical next gen applications with consistent ultra-low latencies and high scalability.
MapR Technologies, Inc., a leader in delivering one platform for all types of data across every cloud, announced breakthrough database innovations for rich data-intensive applications. With new advancements for developers that enable rich applications, in-place and continuous machine learning/AI and SQL capabilities, and global real-time data integration and microservices support, MapR continues to push the boundaries of data management. As part of the MapR Converged Data Platform, MapR-DB enables faster time-to-market, always-on intelligent business processes and contextual user experiences. MapR-DB supports multiple data models (document, wide column, key value, etc.) and unifies operations and analytics for in-place and continuous real time business insights. MapR-DB can operate thousands of mission critical next gen applications with consistent ultra-low latencies and high scalability.
As an extension to its Data Lake Management Platform, Zaloni introduced a machine-learning data matching engine, which leverages the data lake to create “golden” records and enable enriched data views for multiple use cases across business sectors. Zaloni’s data matching engine provides a new approach for creating an integrated, consistent view of data that is updated, efficiently maintained and can drive customer-facing applications. It addresses a gap in the marketplace for a simplified, much less expensive and faster-to-implement solution for data mastering. With Zaloni’s Data Master extension, companies can leverage their data lake environment to achieve an enriched view of customer or product data for applications such as intelligent pricing, personalized marketing, smart alerts, customized recommendations, and more. Because it works directly in the data lake, organizations can capture and combine any data type, including unstructured data, which allows the engine to create a more robust single version of truth. Further, Zaloni’s data matching engine can use your sample data to train its machine-learning algorithms.
MemSQL, provider of the fast real-time data warehouse, showcased how it is closing the machine learning (ML) gap between data science and operational applications. In the release of MemSQL 6, the company added new extensibility features to enable ML, massive performance improvements for analytical queries, and a broader set of online operations. Previously, the path to implement ML meant working between different environments in the development process. Now, developers can use ML functions with live data and SQL, and a real-time data warehouse to easily build operational applications without requiring multiple disparate systems. Based on input from some of the world’s largest enterprise companies there is a need for higher performance from operational applications. To address these demands, MemSQL 6 includes the ability to run ML algorithms in a distributed SQL environment, enhancements to online operations, and increases to query performance to deliver up to 80 times improvement from previous versions. For companies wanting to bring machine learning functions closer to live data, MemSQL 6 supports real-time scoring with existing or new models, DOT_PRODUCT for image recognition, and new extensibility capabilities that enable functions, such as K-means in SQL.
SAP SE (NYSE: SAP) announced the release of the SAP Data Hub solution to enable businesses to overcome the complexity of their data systems and capitalize on the vast amounts of data they collect from a growing variety of sources. SAP Data Hub creates value across the diverse data landscape through data integration, data orchestration and data governance, as well as by creating powerful data pipelines that can accelerate positive business results. Enterprise data landscapes have grown increasingly complex with proliferating data sources and destinations, such as data lakes, enterprise data warehouses (EDWs), data marts, cloud applications, cloud storage and business intelligence tools. According to a new global study from SAP, 74 percent of IT decision makers said their data landscape was so complex that it limited agility, and 86 percent said there was much more they could do with their data if they could simply access it. SAP Data Hub establishes a new software category that allows data pipeline processing to be managed, shared and distributed across the enterprise with enterprise-ready monitoring and landscape management capabilities.
Educational Resources
Zoomdata, developers of the fast visual analytics platform for Big Data, launched the an expert educational program — Big Data Master Class Series — to help enterprises find success implementing their big data platforms and business intelligence initiatives for high volume, streaming or high variety data sources. In addition to a massive amount of free online educational audio and document-based content, there is a video series, designed and delivered by leading industry experts and senior scientists and engineers, that offers more than 90 videos from noted speakers, with more to come. The Zoomdata Big Data Master Class series is comprised of videos that run from three to five minutes in length, as well as supplemental written, video and audio content. Classes will also include hands-on technical talks from engineers with real-world experience implementing big data analytics solutions.
Partnerships
Anaconda, Inc., the most popular Python data science platform provider, announced it is partnering with Microsoft to embed Anaconda into Azure Machine Learning, Visual Studio and SQL Server to deliver data insights in real time. Microsoft and Anaconda will partner to deliver Anaconda for Microsoft, a subset of the Anaconda distribution available on Windows, MacOS and Linux. Anaconda, Inc. will also offer a range of support options for Anaconda for Microsoft. Python is the leading data science language and Anaconda is the most popular Python data science distribution with over 4.5 million active users. Anaconda for Microsoft will initially be included in Microsoft Azure Machine Learning, Machine Learning Server, Visual Studio and SQL Server. In SQL Server, data scientists will be able to run Python code inside the database, eliminating the need to export data for processing. This accelerates the performance of Python data science on SQL Server, and improves data security and confidentiality. As part of the agreement, Anaconda will also make Microsoft R Open packages available by default to Anaconda users who also use the R language using Anaconda’s R Essentials package. Additionally, Visual Studio Code, R Client and R Tools for Visual Studio Code will be added to the Anaconda Navigator, which helps orient data scientists to the Anaconda ecosystem.
 MapR Technologies, Inc., a leader in delivering one platform for all types of data across every cloud, and C3 IoT, a leading AI and IoT software platform for digital transformation, are partnering to provide an end-to-end solution for AI and/or IoT applications. This partnership will address the large and growing market opportunity for a new generation of enterprise software that requires intelligent applications based on AI and IoT. C3 IoT and MapR are collaborating on new technology developments and go-to-market initiatives that enable rapid deployment of mission-critical, secure intelligent applications for commercial and public sector use cases, including real-time fraud detection, cyber and physical security, and predictive maintenance across industries such as healthcare, insurance, and manufacturing. This new partnership will provide both faster time to value for joint customers as well as broader deployment options, allowing applications to leverage any combination of public cloud, private data center, and edge computing technologies. Time to market to deploy end-to-end AI and IoT solutions is crucial for realizing business value. In just weeks, C3 IoT and MapR enable organizations to prove and deploy complete production applications. An end-to-end application leveraging the combined platforms from C3 IoT and MapR can aggregate data from numerous enterprise systems, Internet data feeds, and large-scale sensor networks, and process data in real-time with an AI/machine learning engine.
MapR Technologies, Inc., a leader in delivering one platform for all types of data across every cloud, and C3 IoT, a leading AI and IoT software platform for digital transformation, are partnering to provide an end-to-end solution for AI and/or IoT applications. This partnership will address the large and growing market opportunity for a new generation of enterprise software that requires intelligent applications based on AI and IoT. C3 IoT and MapR are collaborating on new technology developments and go-to-market initiatives that enable rapid deployment of mission-critical, secure intelligent applications for commercial and public sector use cases, including real-time fraud detection, cyber and physical security, and predictive maintenance across industries such as healthcare, insurance, and manufacturing. This new partnership will provide both faster time to value for joint customers as well as broader deployment options, allowing applications to leverage any combination of public cloud, private data center, and edge computing technologies. Time to market to deploy end-to-end AI and IoT solutions is crucial for realizing business value. In just weeks, C3 IoT and MapR enable organizations to prove and deploy complete production applications. An end-to-end application leveraging the combined platforms from C3 IoT and MapR can aggregate data from numerous enterprise systems, Internet data feeds, and large-scale sensor networks, and process data in real-time with an AI/machine learning engine.
Trifacta, a leader in data wrangling, announced that its Trifacta Wrangler Enterprise and Edge products now integrate with DataRobot‘s automated machine learning platform. This technology integration enables customers in financial services, life sciences and insurance to streamline the execution of machine learning at scale in order to become AI-driven. The integration between Trifacta and DataRobot supports a variety of deployment options across on-premise and cloud data platforms. Data wrangling processes have traditionally been carried out with hand coding techniques. Manual data preparation requires expertise in a coding language, like Python or Java, and is time-consuming, cumbersome and error-prone. As organizations scale their machine learning efforts and adopt modern solutions such as DataRobot, hand coding becomes an increasing bottleneck, which can stall and jeopardize machine learning initiatives. The integrated Trifacta and DataRobot solution enables organizations to accelerate data wrangling and empower analysts of any skill level to quickly build and deploy accurate predictive models.
Security
Dataguise, a leader in data-centric audit and protection (DCAP), introduced DgSecure 6.2. The company showcased its latest DCAP solution which provides state-of-the-art detection, protection, monitoring, and auditing of sensitive information throughout the enterprise for compliance with a wide range of privacy data regulations – including the General Data Protection Regulation (GDPR). DgSecure is a premier data-centric audit & protection platform that delivers simple, powerful software for sensitive data governance. The out-of-the-box solution deploys quickly and eliminates the need for custom programming, reducing the time, resources, compliance costs and complication of alternative products. With the influx of data and organizations leveraging this information across a broader range of computing platforms, legacy security solutions are quickly becoming less effective in ensuring comprehensive protection. With the evolving state of data architecture, the capabilities in DgSecure 6.2 have been optimized for maximum protection of data throughout structured, unstructured, and semi-structured data both on-premise and in public, hybrid, and private cloud environments. The range of coverage and new product features in DgSecure position the product well within the data-centric audit and protection category. This gives enterprises the confidence to address current and future data privacy challenges and regulations that include GDPR.
Striim™ (pronounced ‘Stream’) was promoting a holistic approach to real-time enterprise security analysis. Their solution enables businesses to achieve a comprehensive view of their potential internal and external vulnerabilities, and deliver a more timely and effective response to real threats. Striim is not meant to replace SIEMs. Striim complements existing security solutions and traditional SIEM software with an end-to-end streaming integration and analytics platform in support of a holistic security strategy. By ingesting, organizing, correlating, visualizing, and alerting on all security events – automatically, in real time – Striim enables businesses to detect and act on security threats immediately, with fewer false alarms. In addition, Striim enables users to operationalize artificial intelligence (AI) results via integration with leading AI frameworks, and to validate machine learning models.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind