 In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
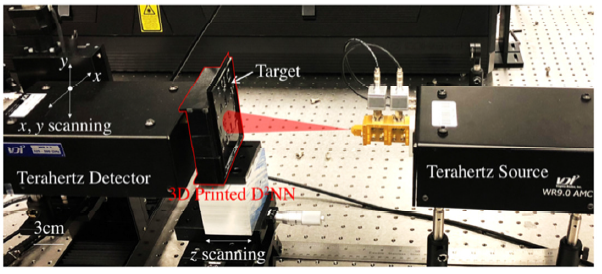
All-Optical Machine Learning Using Diffractive Deep Neural Networks
This paper introduces an all-optical Diffractive Deep Neural Network (D2NN) architecture that can learn to implement various functions after deep learning-based design of passive diffractive layers that work collectively. The UCLA researchers experimentally demonstrated the success of this framework by creating 3D-printed D2NNs that learned to implement handwritten digit classification and the function of an imaging lens at terahertz spectrum. With the existing plethora of 3D-printing and other lithographic fabrication methods as well as spatial-light-modulators, this all-optical deep learning framework can perform, at the speed of light, various complex functions that computer-based neural networks can implement.
Progressive Neural Architecture Search
This paper propose a new method for learning the structure of convolutional neural networks (CNNs) that is more efficient than recent state-of-the-art methods based on reinforcement learning and evolutionary algorithms. The approach uses a sequential model-based optimization (SMBO) strategy, in which we search for structures in order of increasing complexity, while simultaneously learning a surrogate model to guide the search through structure space.

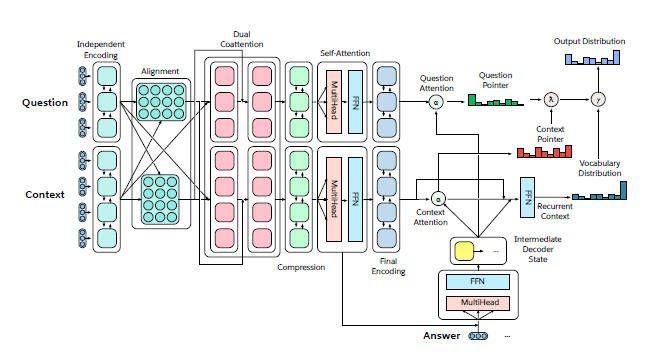
The Natural Language Decathlon: Multitask Learning as Question Answering
Deep learning has improved performance on many natural language processing (NLP) tasks individually. However, general NLP models cannot emerge within a paradigm that focuses on the particularities of a single metric, data set, and task. This paper introduces the Natural Language Decathlon (decaNLP), a challenge that spans ten tasks: question answering, machine translation, summarization, natural language inference, sentiment analysis, semantic role labeling, zero-shot relation extraction, goal-oriented dialogue, semantic parsing, and commonsense pronoun resolution.
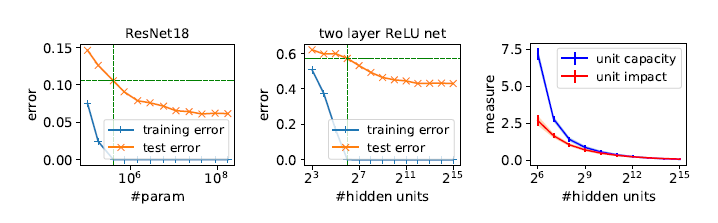
Towards Understanding the Role of Over-Parametrization in Generalization of Neural Networks
Despite existing work on ensuring generalization of neural networks in terms of scale sensitive complexity measures, such as norms, margin and sharpness, these complexity measures do not offer an explanation of why neural networks generalize better with over-parametrization. This work suggests a novel complexity measure based on unit-wise capacities resulting in a tighter generalization bound for two layer ReLU networks.
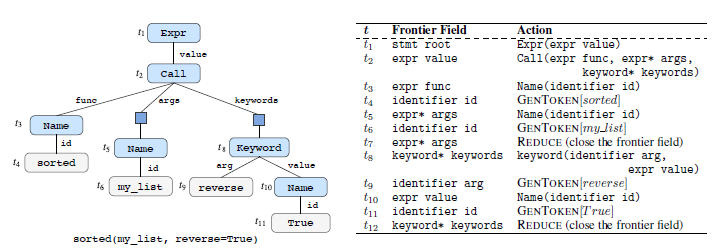
StructVAE: Tree-structured Latent Variable Models for Semi-supervised Semantic Parsing
Semantic parsing is the task of transducing natural language (NL) utterances into formal meaning representations (MRs), commonly represented as tree structures. Annotating NL utterances with their corresponding MRs is expensive and time-consuming, and thus the limited availability of labeled data often becomes the bottleneck of data-driven, supervised models. This paper introduces StructVAE, a variational auto-encoding model for semi-supervised semantic parsing, which learns both from limited amounts of parallel data, and readily-available unlabeled NL utterances.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind