
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
NGBoost: Natural Gradient Boosting for Probabilistic Prediction

The Stanford ML Group presents the Natural Gradient Boosting (NGBoost), an algorithm which brings probabilistic prediction capability to gradient boosting in a generic way. Predictive uncertainty estimation is crucial in many applications such as healthcare and weather forecasting. Probabilistic prediction, which is the approach where the model outputs a full probability distribution over the entire outcome space, is a natural way to quantify those uncertainties. Gradient Boosting Machines have been widely successful in prediction tasks on structured input data, but a simple boosting solution for probabilistic prediction of real valued outputs is yet to be made. NGBoost is a gradient boosting approach which uses the Natural Gradient to address technical challenges that makes generic probabilistic prediction hard with existing gradient boosting methods. This approach is modular with respect to the choice of base learner, probability distribution, and scoring rule. The paper shows empirically on several regression data sets that NGBoost provides competitive predictive performance of both uncertainty estimates and traditional metrics.

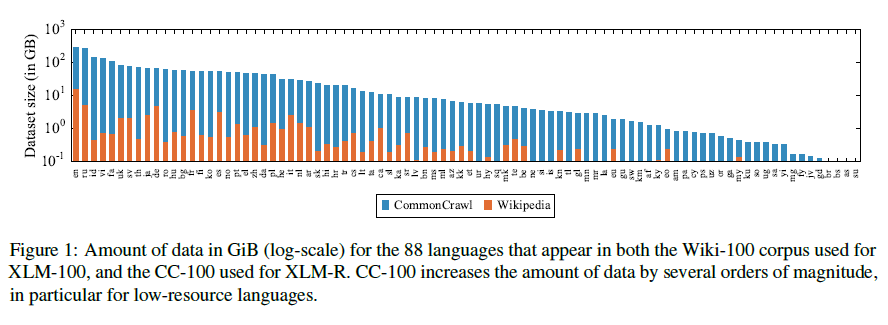
Unsupervised Cross-lingual Representation Learning at Scale
This paper shows that pretraining multilingual language models at scale leads to significant performance gains for a wide range of cross-lingual transfer tasks. The Facebook AI researchers trained a Transformer-based masked language model on one hundred languages, using more than two terabytes of filtered CommonCrawl data. The model, dubbed XLM-R, significantly outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks.
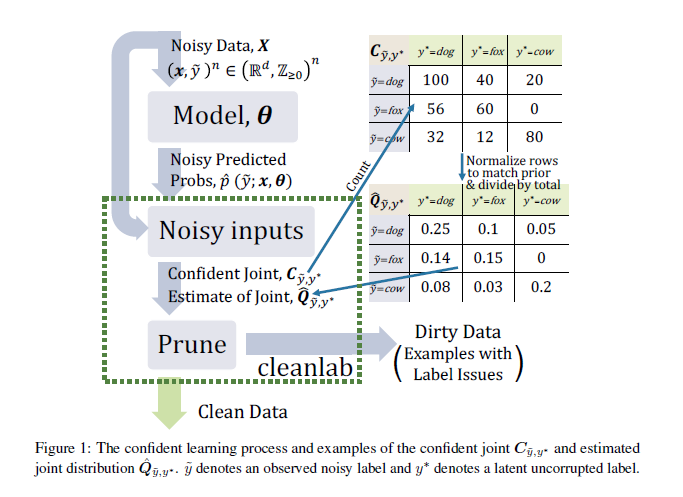
Confident Learning: Estimating Uncertainty in Dataset Labels
Learning exists in the context of data, yet notions of confidence typically focus on model predictions, not label quality. Confident learning (CL) has emerged as an approach for characterizing, identifying, and learning with noisy labels in data sets, based on the principles of pruning noisy data, counting to estimate noise, and ranking examples to train with confidence. This paper generalizes CL, building on the assumption of a classification noise process, to directly estimate the joint distribution between noisy (given) labels and uncorrupted (unknown) labels. This generalized CL, open-sourced as cleanlab, is provably consistent under reasonable conditions, and experimentally performant on ImageNet and CIFAR, outperforming recent approaches, e.g. MentorNet, by 30% or more, when label noise is non-uniform. cleanlab also quantifies ontological class overlap, and can increase model accuracy (e.g. ResNet) by providing clean data for training.
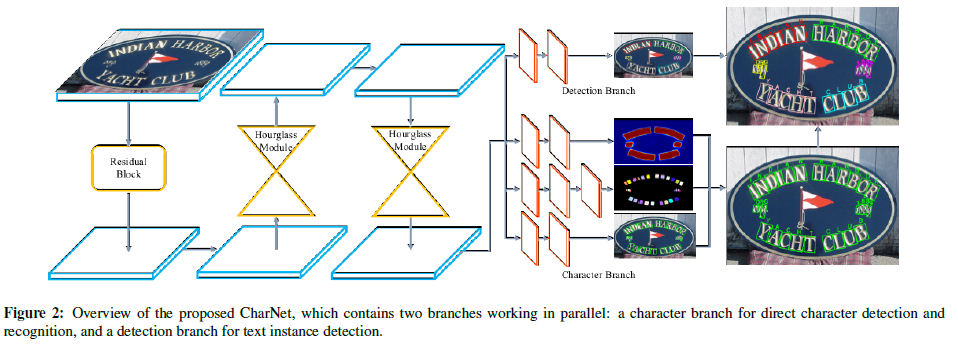
Convolutional Character Networks
Recent progress has been made on developing a unified framework for joint text detection and recognition in natural images, but existing joint models were mostly built on two-stage framework by involving ROI pooling, which can degrade the performance on recognition task. This proposes convolutional character networks, referred as CharNet, which is an one-stage model that can process two tasks simultaneously in one pass. CharNet directly outputs bounding boxes of words and characters, with corresponding character labels. The technology utilizes character as basic element, allowing us to overcome the main difficulty of existing approaches that attempted to optimize text detection jointly with a RNN-based recognition branch. In addition, the paper develops an iterative character detection approach able to transform the ability of character detection learned from synthetic data to real-world images. These technical improvements result in a simple, compact, yet powerful one-stage model that works reliably on multi-orientation and curved text. Code is available HERE.
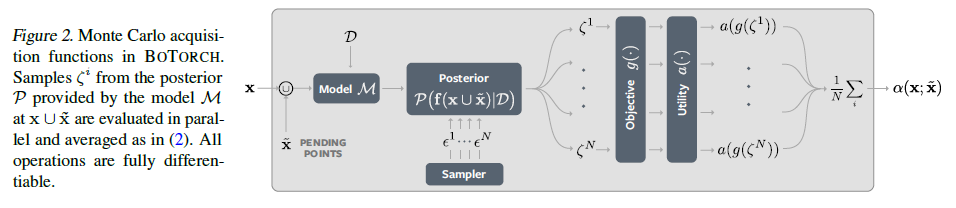
BoTorch: Programmable Bayesian Optimization in PyTorch
Bayesian optimization provides sample-efficient global optimization for a broad range of applications, including automatic machine learning, molecular chemistry, and experimental design. This paper introduces BoTorch, a modern programming framework for Bayesian optimization. Enabled by Monte-Carlo (MC) acquisition functions and auto-differentiation, BoTorch’s modular design facilitates flexible specification and optimization of probabilistic models written in PyTorch, radically simplifying implementation of novel acquisition functions. The MC approach is made practical by a distinctive algorithmic foundation that leverages fast predictive distributions and hardware acceleration. Experiments demonstrates the improved sample efficiency of BoTorch relative to other popular libraries. BoTorch is open source and available at HERE.
RLCard: A Toolkit for Reinforcement Learning in Card Games
RLCard is an open-source toolkit for reinforcement learning research in card games. It supports various card environments with easy-to-use interfaces, including Blackjack, Leduc Hold’em, Texas Hold’em, UNO, Dou Dizhu and Mahjong. The goal of RLCard is to bridge reinforcement learning and imperfect information games, and push forward the research of reinforcement learning in domains with multiple agents, large state and action space, and sparse reward. In this paper, we provide an overview of the key components in RLCard, a discussion of the design principles, a brief introduction of the interfaces, and comprehensive evaluations of the environments. The codes and documents are available HERE.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind