
Sponsored Post
Apache Druid was invented to address the lack of a data store optimized for real-time analytics. Druid combines the best of real-time streaming analytics and multidimensional OLAP with the scale-out storage and computing principles of Hadoop to deliver ad hoc, search and time-based analytics against live data with sub-second end-to-end response times. Today, thousands of companies worldwide rely on Druid to provide real-time monitoring and analytics, including data-driven companies like Netflix, AirBnB, Lyft, Pinterest, Walmart and Alibaba. The largest Druid deployments deliver sub-second analytics against millions of events per second and 100s of petabytes of data.
This whitepaper provides an introduction to Apache Druid, including its evolution, core architecture and features, and common use cases. Founded by the authors of the Apache Druid database, Imply provides a cloud-native solution that delivers real-time ingestion, interactive ad-hoc queries, and intuitive visualizations for many types of event-driven and streaming data flows.
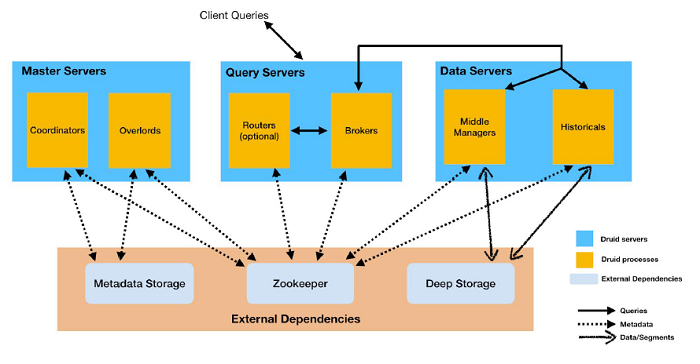
Druid was built to solve a problem in a specific industry, programmatic digital advertising, that turned out to be generalizable to any use case that requires sub-second query response against large data sets, particularly though with a streaming data component. Today it is used at-scale by large enterprises, often to support business-critical operations activities.
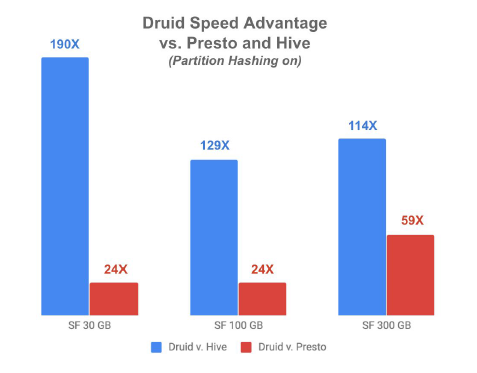
Druid delivers one to two orders of magnitude greater performance and lower latency (“data freshness”) at scale than data lakes or data warehouses for real-time analytics. The main reason is that it was designed for real-time streaming ingestion and the combination of time-based, ad hoc and search-based analytics operations and end customers need.
Download the new white paper courtesy of Imply Data, Inc. to learn more about Apache Druid, the open source distributed data store.



Speak Your Mind