
The storage and processing of data is not a new problem. Since the invention of the computer users have needed to operate on data, save it and recall it at a later date to further operate on it. Over the past 50 years, an industry worth hundreds of billions of dollars (and an exciting and fulfilling career for me) has grown to support this and everything from general purpose solutions for your home user (yes Excel counts 😉 ) to huge distributed systems to work on unimaginably large datasets like those of Google, Facebook and LinkedIn are available.
Event streaming is a modern take on this problem. Instead of storing data X, recalling it, transforming it to Y and storing it again, event streaming stores the “event” that X was created and the “event” that X was changed to Y. Think of it as recording people going through a turnstile to a football game rather than counting the number of people in their seats. This approach creates a log of operations that can be read and responded to by the appropriate services in real time. The services that respond to events on these logs can typically be smaller and more self-contained than alternatives leading to more flexible, resilient and scalable solutions.
In this article we’re going to look at the role and evolution of event streaming platforms (software to store, transport and operate on event streams) and look at where this blossoming sector is headed in the future.
The beginning
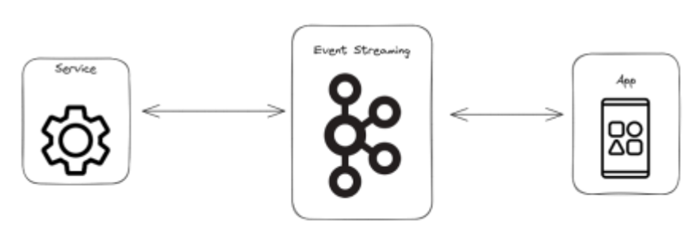
Event streaming platforms were designed with a very simple purpose in mind, to get event X from source A to sink B in a fast and resilient way. Like the message queueing systems that preceded them they also buffered data so that if sink B was not yet ready for event X it would be stored by the platform until it was.
Industry leaders such as Apache Kafka (developed at LinkedIn) became incredibly efficient at these tasks, transporting enormous amounts of data at tiny latencies! The success of the event streaming platform drove a shift in architectural thinking away from monolithic architectures: large applications that perform all the tasks in a business area, towards
microservices: small, independent services with a narrow scope that communicate with each other via event streams.
On the whole this shift is positive, breaking down complex problems into smaller pieces allows for more rapid development, increases reliability and allows for easier scaling. Much has been already written on this subject so I won’t add further and instead focus on one side effect of this shift: that organisations that have transitioned to a microservices architecture see far more data moving between their systems than before. It didn’t take long for someone to recognise that this “in transit” data could be useful.
Yesterday: Stream processing
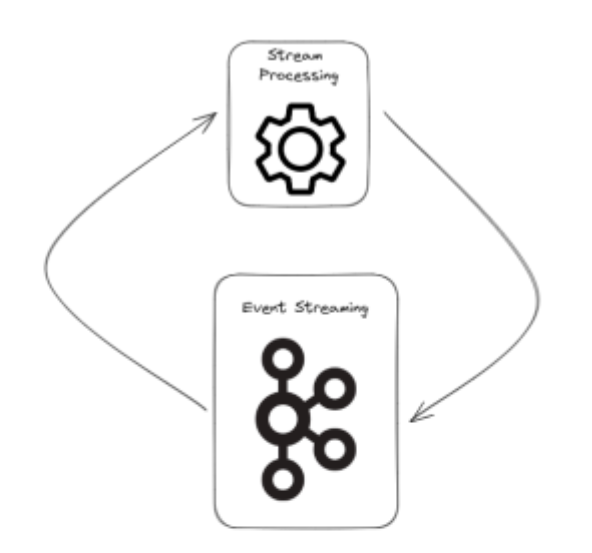
The shift to microservices architectures is pervasive, most organisations quickly see the value of this shift and soon employ it across the entire organisation. Stream processing is a natural extension of this where the source and sink of a given process are event streams. Using stream processing, events from one or more topics (logical streaming units) can be consumed, manipulated and produced out to another event stream ready for another service. To stay with our football analogy, stream processing would provide a running count of people in the stadium as they pass through the turnstile.
One new concept that stream processing introduced was state. Event values could be accumulated, stored and referenced in the context of other events. For instance in our football game application, we could have another stream that contains updates to season ticket holder details (a change of address or phone number). These can be played into a store that retains the latest details for each customer. This store can then be referenced by processing performed on other event streams, say our turnstile stream, to make sure that any offers for season ticket holders are sent to the most recent address.
This type of work would previously have required a database and complex logic to handle the nuances of event streams but stream processing tools and concepts wrapped this up into an easy to manage and develop package.
Today: The Streaming Database/Operational Warehouse
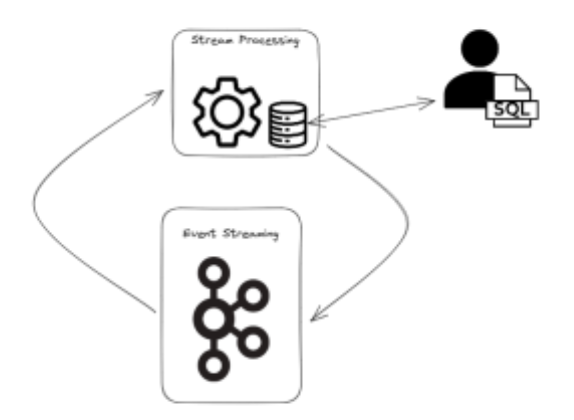
Today we’re starting to flip the stream processing analogy inside out. The success of stream processing as an architecture meant that the process of reading data from an event streaming system and “materializing” it to a store has become commonplace.
It was quickly noticed that these stores contain useful data suitable for cases beyond stream processing and an entire new sector was created that offered this data in the formats and protocols usually associated with databases rather than event streaming: Streaming Databases. In a modern streaming database users can write SQL and query views over the streaming data in their event streaming platforms. To take the example above, “SELECT PostCode FROM SeasonTicketHolders WHERE name = ‘Tom Scott’” would query my store of latest addresses and provide me with the correct answer as a result set rather than as an event stream.
Solutions of this type are excellent for providing the well known advantages of event streaming (freshness of data etc.) but also provide the ease of use and ready access that comes with SQL.
Tomorrow: The Streaming Datalake
The difference between a database and a datalake is that a database typically stores the processed, current data required to power applications whereas a datalake stores historical and raw data generally for the purpose of analytics. The event streaming version of the database is well covered by the streaming database offerings described above but there is no real version of a datalake within the event streaming ecosystem at present.
The reason for this is unlikely to be that there is no need. I have spoken with many frustrated analysts and data engineers that would love a wider variety and volume of data to be made available from event streaming platforms (if you ever meet an analyst that doesn’t want more data please call me 😉 ). Instead the problems are largely technical. Event streaming platforms were not designed for analytical workloads and so storage of large amounts of data can be expensive and performance can be affected when we get to extreme scales in terms of variety.
Thankfully this is changing, if we take the most popular event streaming platform: Apache Kafka, we have recently seen the introduction of 2 new features aimed specifically at increasing the volume and variety of data stored in the platform:
● KIP-405 – practically unlimited and cheap storage for data in Kafka
● KIP-833 – a different approach to metadata that greatly expands the variety of data that can be stored in Kafka.
With just these two changes (more are coming) suddenly the event streaming platform becomes a viable data single source of truth for all of the data in an organisation. Simply change a configuration property and suddenly all historical data flowing through an event streaming platform is retained in a cost effective and easily recallable way. These architectures are in their infancy but offer significant advantages to the Streaming Platform + ETL/ELT + Datalake architectures that are their equivalents today:
Consistency – Any time there are multiple copies of the same data consistency must be maintained between them. The typical pattern of copying data from an event stream into a data warehouse requires extra work to ensure that consistency is maintained between the two. By storing and sourcing the data directly from the event streaming system a single, totally consistent, copy of the data is maintained. Analytical workloads can be certain they are working with the same data as their operational equivalents.
Complexity – Less is more in data infrastructure, the more moving pieces you have the more risk you introduce. A single system to store and access data greatly simplifies a data architecture. Streaming Datalakes remove the need for complex ETL/ELT processes and separate Datalake maintenance by moving data read directly to the source.
Cost – Data storage costs money and conversely, reducing the required storage for data infrastructure saves money. The Streaming datalake removes the need for duplicate copies of data in the streaming system and in the separate datalake. A massive saving for high data volumes.
A call to arms
The future is bright! Never before have there been so many options for data engineers in terms of the way in which data can be stored and presented to users. Event streaming already has a critical role in powering the operational concerns of modern businesses but I believe in a future where the benefits in terms of data freshness and consistency afforded by event streaming can be shared with analytical workloads too. When considering new data systems and pipelines involving event streaming here’s 3 principles to help guide your decision making process:
1. Events are better than facts – Facts tell the current state but events tell the story, once you update a row in a table the previous value is lost and along with it any clues to the reason it was updated. The former tends to be fine for operational concerns but analytical workloads are all about that historical journey.
2. Data tastes better from the source – The point at which a piece of data is generated is the point at which it is most correct, fresh and purposeful. It wouldn’t be generated if this was not the case. This principle can be carried on to data consumers: the closer they are to the source the more flexible and complete their usage of the data can be.
3. Resiliency efficiency is more than the sum of its parts – All modern systems are resilient but almost all of the resiliency features of one system cannot be used by another. Streamlining your architecture can maintain the same resilience without relying on costly and complex resilience features in multiple systems.
Event streaming is here to stay and, with effective usage, the data journey from raw to relevant has never been shorter. Seize the opportunities offered by this game changing technology and the real time future it offers.
About the Author

Long time enthusiast of Kafka and all things data integration, Tom Scott has more than 10 years experience (5yrs+ Kafka) in innovative and efficient ways to store, query and move data. Tom is pioneering the Streaming Datalake at Streambased. An exciting new approach to raw and historical data management in your event streaming infrastructure.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: https://twitter.com/InsideBigData1
Join us on LinkedIn: https://www.linkedin.com/company/insidebigdata/
Join us on Facebook: https://www.facebook.com/insideBIGDATANOW



Speak Your Mind