This is the third entry in an insideBIGDATA series that explores the intelligent use of big data on an industrial scale. This series, compiled in a complete Guide, also covers the exponential growth of data and the changing data landscape, as well as offerings from HPE for big data analytics. The third entry in the series is focused on realizing a scalable data lake.
Realizing a Scalable Data Lake

A modern analytics framework must be able to seamlessly manage and analyze data in a number of systems, with the intelligence to selectively move data between data stores based on value, time sensitivity, and cost. Choosing the right technology that optimizes this framework is crucial to delivering real-time access to troves of complex data, with total cost of ownership and ease of management being equally important.
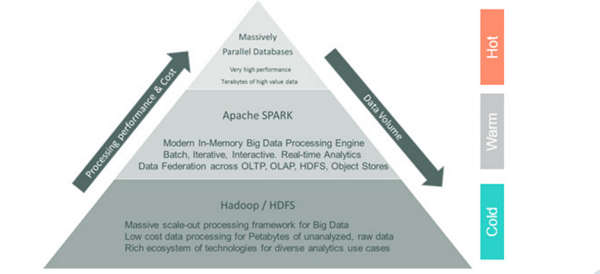
Data can be classified as hot, warm, or cold. Small volumes of business critical data (hot) are processed in massively parallel in-memory databases. Larger volumes of less frequently accessed data (warm) are processed in a low-cost tier, typically flash-based storage and memory. Petabytes of raw interaction data and archived business data (cold) reside in a lower-cost analytics platform like Hadoop, or in an object store.
As the Hadoop ecosystem matures, new processing frameworks like Spark enable a wide range of analytics use cases, from real-time streaming to machine learning, acting as a storage-layer agnostic data federation platform which supports streaming, batch, and iterative analytics.
Since being founded in 2006, Hadoop has proven to be a cost-effective solution for managing data growth across organizations. Rather than buying expensive “latest and greatest” machines to perform massive data workloads, distributing the processing power across a cluster mitigates the need for expensive supercomputers. Hadoop contributors favor data locality, with co-located compute and storage at the node. Each server adds additional compute and storage capacity, scaling linearly. This is what many consider to be a traditional, symmetric architecture where each server is configured identically.
Since being founded in 2006, Hadoop has proven to be a cost-effective solution for managing data growth across organizations.
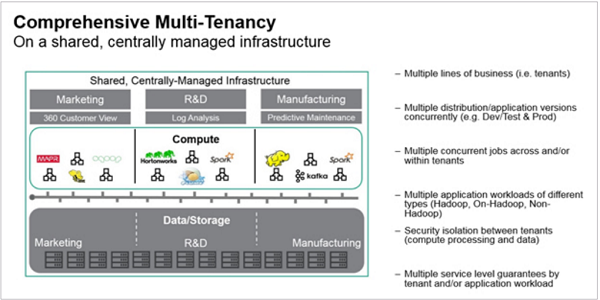
Many organizations share a vision of having all workloads, analytics, and applications running on a common dataset, or a scalable, multi-tenant platform for all data and analytics workloads. This movement begins with consolidating data, using Hadoop as a repository and for simple workloads like ETL and pre-processing data. The variety in the Hadoop software stack can accelerate a diverse set of analytics use cases beyond just ETL and ELT, driving organizations to rapidly evaluate and deploy these technologies to promote new business capabilities. These entities rely on enterprisegrade performance to run various workloads and consolidate data, with the ability to scale these workloads across a common, flexible infrastructure.
From a platform perspective, it is clear that a homogeneous hardware architecture cannot address all of the required functions:
- Low-latency compute and event processing
- High-latency compute extract-transform-load (ETL) offload and archival storage
- Big memory compute and in-memory data analytics
- HPC compute and deep learning
- HDFS storage
- Archival storage
Organizations are now evaluating hardware options that were traditionally limited to the HPC domain, ranging from general-purpose graphics processing units (GPGPUs) for parallel computing, non-volatile memory express (NVMe), persistent memory for workloads requiring low-latency, and hardware accelerators for offloading compression/decompression tasks and storage efficiency. This allows for growth and scalability as data volume, variety, and workload needs evolve over time.
[clickToTweet tweet=”Organizations are now evaluating hardware options that were traditionally limited to the HPC domain.” quote=”Organizations are now evaluating hardware options that were traditionally limited to the HPC domain.”]
Over the next few weeks, this series on the use of big data on an industrial scale will cover the following additional topics:
- The Exponential Growth of Data
- The Changing Data Landscape
- The HPE Elastic Platform for Big Data Analytics
- HPE Workload and Density Optimized System
- The Five Blocks of the HPE WDO Solution
You can also download the complete report, “insideBIGDATA Guide to the Intelligent Use of Big Data on an Industrial Scale,” courtesy of Hewlett Packard Enterprise.



Speak Your Mind