![]() Unravel Data, provider of a full-stack performance intelligence platform for optimizing Big Data operations (DataOps [1]), emerged from stealth, announcing a new platform to accelerate Big Data applications, optimize resource usage, and provide operations intelligence, all from a single platform. Addressing the larger Big Data market, which analysts at IDC estimate will be worth $187 billion by 2019 [2], Unravel Data helps DataOps teams, which includes data scientists, BI analysts, IT operations and systems architects, resolve performance and reliability issues with Big Data applications running on clusters scaling up to several thousand nodes. With a click of a button, the Unravel platform provides DataOps teams with actionable information to accelerate time-to-value from their Big Data applications.
Unravel Data, provider of a full-stack performance intelligence platform for optimizing Big Data operations (DataOps [1]), emerged from stealth, announcing a new platform to accelerate Big Data applications, optimize resource usage, and provide operations intelligence, all from a single platform. Addressing the larger Big Data market, which analysts at IDC estimate will be worth $187 billion by 2019 [2], Unravel Data helps DataOps teams, which includes data scientists, BI analysts, IT operations and systems architects, resolve performance and reliability issues with Big Data applications running on clusters scaling up to several thousand nodes. With a click of a button, the Unravel platform provides DataOps teams with actionable information to accelerate time-to-value from their Big Data applications.
Too Many Problems, Too Little Time
Until now, visibility into the entire Big Data application stack has not been available – a situation made dire by the fact that problems with an application could result from anywhere in the stack. For example, from bad code, inefficient data partitioning, mismatched system configuration settings, best-guessed resource allocation, or infrastructure issues. Making matters worse, a Big Data stack running multiple applications must deal with resource contention and prioritization issues that can reduce both individual application and overall system performance. Amidst these mounting challenges, no solutions have emerged for making analytics-based recommendations in plain English to improve individual application and full-stack performance.
Adding to the challenge, industry analysts have highlighted the acute shortage of talent for running and maintaining Big Data systems. Speaking of Hadoop alone, Gartner estimates that, “through 2018, 70 percent of Hadoop deployments will fail to meet cost savings and revenue generation objectives due to shortage of skills and integration challenges.”[3]
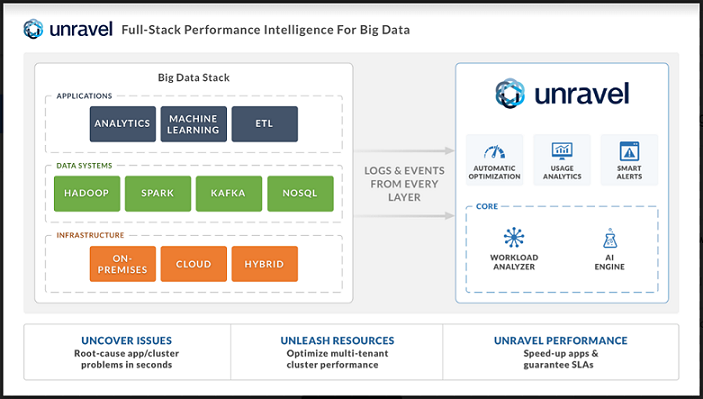
Automating Performance Intelligence
Unravel Data has pioneered a system that provides full-stack performance intelligence by tracking all activity related to Big Data applications, infrastructure, services, datasets, and users. It is also designed to be multi-platform, meaning it can support various systems such as Spark, Hadoop, and Kafka, whether on premises or in the cloud. With Unravel Data, operations teams can solve on-going operations problems by a) ensuring that mission-critical applications meet SLAs, b) providing actionable insights on applications that could run faster or use fewer resources, c) setting automatic policies to resolve recurring problems such as rogue jobs, and d) reporting users and applications that are using the most resources on a multi-tenant cluster.
Unlike monitoring tools that provide stack traces or logs and leave it to users to identify the root cause of issues, Unravel Data automatically discovers and fixes performance and reliability issues; proactively pin-points problems that could reside anywhere in the stack; provides end-to-end visibility and alerting for both data pipelines and ad-hoc applications; and provides deep drill-down visibility from the application level down to fine-grained resource utilization.
Unravel Data also tracks all information about data usage and access, automatically classifying data by usage frequency and age into hot, warm, or cold; creating audit reports of data usage and access by users and applications; and providing recommendations of which datasets should be cached and how datasets should be partitioned for best performance.
Unravel Data’s analytics-based recommendations are presented in plain English on a single console, which allows users of all skill levels to resolve their problems quickly. Unravel Data does away with the need for the multiple, disparate tools that are required today. And, because Unravel Data maintains an overview of entire Big Data clusters, cluster operations staff are able to provide their users enforceable service level agreements guaranteeing specific levels of performance.
Delivering Rapid Insights
Companies such as Autodesk and YP.com are already using Unravel Data to manage their production Big Data systems. “Unravel Data improves reliability and performance of our Big Data applications and helps us identify bottlenecks and inefficiencies in our Spark and Oozie workloads,” said Charlie Crocker, director of product analytics at Autodesk. “It also helps us understand how resources are being used on the cluster and forecasts our compute requirements.”
Big Data systems are extremely complex, and getting them to work efficiently is considered a black art,” said Kunal Agarwal, Co-Founder and CEO of Unravel Data. “Setting up a Hadoop or Spark cluster is just the beginning. To truly derive business value, these systems and the applications running on them must be high-performing and easy enough for everyone to use. Unravel Data is comprehensive, solving the interoperability and performance challenges of multiple application engines in a complex Big Data environment. That’s the value we bring to the market.”
Availability
Unravel Data is available immediately for on-premises, cloud or hybrid Big Data deployments. Unravel Data currently supports Hadoop, Spark and Kafka, with plans to add support for other systems such as for data ingestion (Storm, Flume), NoSQL systems (Cassandra, HBase) and MPP systems (Impala, Drill).
[1] DataOps refers to the practices and tools used to increase the velocity, quality and reliability of data analytics
[2] Worldwide Big Data and Business Analytics Revenues Forecast to Reach $187 Billion in 2019, According to IDC
[3] “Predicts 2016: Evolving Information Infrastructure Technologies and Approaches Bring New Challenges,” Published: 1 December 2015, Analyst(s): Ted Friedman, Roxane Edjlali, Guido De Simoni, Adam M. Ronthal, Nick Heudecker, Merv Adrian, Bill O’Kane, Mark A. Beyer, Donald Feinberg
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind