 In this special guest feature, Charly Walther, VP of Product and Growth at Gengo.ai, discusses a topic of critical importance to machine learning and AI: training. He goes through the three stages: training, validation, and testing and also points out the importance of data quality. Gengo.ai is a global, people-powered translation platform optimized for developers of multilingual ML/AI applications. With 10+ years of know-how in providing AI training data, Gengo has an impressive track record of successful projects with the world’s top technology companies. Walther joined Gengo from Uber, where he was a product manager in Uber’s Advanced Technologies Group.
In this special guest feature, Charly Walther, VP of Product and Growth at Gengo.ai, discusses a topic of critical importance to machine learning and AI: training. He goes through the three stages: training, validation, and testing and also points out the importance of data quality. Gengo.ai is a global, people-powered translation platform optimized for developers of multilingual ML/AI applications. With 10+ years of know-how in providing AI training data, Gengo has an impressive track record of successful projects with the world’s top technology companies. Walther joined Gengo from Uber, where he was a product manager in Uber’s Advanced Technologies Group.
Training is a fundamental part of any AI project. It’s absolutely crucial that everyone involved in the development of your model understands how it works. However, it can be surprising just how many people see the process as impossible to grasp. Even when all the terms are fully understood, training can seem pretty abstract to those not dealing directly with data. This general lack of understanding could prove a major stumbling block to the progress of your business. When it comes to AI, a working example does wonders for understanding. Let’s use one to get a closer look at training in action.
Before training your AI
For our example, we’ll pretend that we have a large data set of different songs in English and Spanish. We want our model to be able to categorize the songs according to language. However, before diving into training, there are a few things that we need to check.
First, we need to make sure that we have high-quality data. For all machine learning, data must be clean and organized, with no duplicates or irrelevant samples. Rogue samples or a disorganized structure could ruin the whole project, so it’s crucial that the data has been checked thoroughly. Also, for many projects, it can be extremely difficult for the AI to learn without a range of useful tags and annotations. In our example, useful tags for each song could include the artist name and record label. These provide the AI with some helpful clues when it makes predictions using the training data.
Once our data is ready, it should be randomly assigned into three different categories: training, validation, and testing data. This will help us to avoid any selection bias having an impact on the training process. After this, we’re ready to start training our AI for the job.
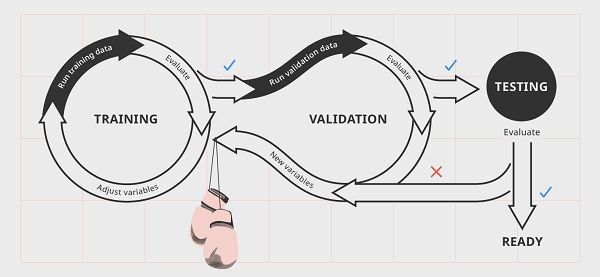
Phase 1: Training
- First, using random variables available to us in the data, we ask the model to predict whether the songs are English or Spanish. We check the results and, unsurprisingly, it has done an awful job. The first time around, the AI has very little idea of how any of the variables relate to the target, so this is no cause for alarm.
- We have some idea of how these variables will relate to the answers we want the AI to predict. Once the model has run the training data, we’re able to start adjusting the parameters of these variables in a way that we think will help the AI do better next time. In our model, perhaps we’re able to tweak things so that the algorithm can recognize sounds that are present only in English or Spanish. We spend a bit of time honing these variables until we’re ready to run the training data again.
- The model runs the training data again and does slightly better. At this point, we simply repeat this process, improving the algorithm little by little every time it attempts to predict the language of our songs. Each one of these cycles is called a training step. During the first few attempts it will perform poorly, but after a while we have a machine that we think may be ready for validation.
Phase 2: Validation
- It’s time to test our model against some new data. We take our validation data, with its inputs and targets, and use it to run our program. The algorithm should do better than when it encountered the training data for the first time, but an amazing performance is by no means guaranteed. Perhaps it has identified a few songs correctly while others are still wide of the mark.
- We look at our results and evaluate them. It’s possible we may see evidence of overfitting, where the model has been trained a little too specifically to only recognize examples in the training data. Alternately, we might be seeing evidence of new variables that we hadn’t thought of — but need to adjust. For example, the machine may be struggling to identify words that sound similar in English and Spanish, such as music and música. We will need to account for this in our next training step.
- We go back to training with our new variables in mind, adjusting and improving the algorithm. We may also want to adjust some hyperparameters: perhaps validation has suggested to us that artists who have separate songs in both English and Spanish are always being identified as Spanish. In this case, we want to adjust the model to reduce the importance of artist name in its predictions.
- Alternatively, our model has done really well at categorizing the songs, so we skip straight to testing.
Phase 3: Testing
- If our model has aced the validation process, it’s ready to be tested against data without tags or targets. This simulates the state of the data it will be expected to perform against in the real world. If our model does well here, it’s ready to be used for the purpose it was designed for. We can be confident that it will identify English or Spanish songs to a high degree of accuracy. If not, then it’s back to training until we feel satisfied.
Why is data quality important?
Looking at the training process as a whole, it’s easy to see that high-quality data with relevant tags is essential. If the data is messy or inaccurately labeled, the model will learn incorrectly and the whole project could be jeopardized. In our example, a few Portuguese songs in our training data could seriously impede the machine’s ability to recognize Spanish. Furthermore, if our tags were added by someone with shaky Spanish or an automated program, we simply can’t rely on it to provide the gold standard our model needs. Each and every tag in our vast dataset is important and could be the difference between a brilliant AI and an expensive mess.
Currently, there is no way to annotate first-class data that doesn’t involve manual labeling. However, it is possible to have large volumes of data quickly cleaned and tagged. Some crowdsourcing platforms make clever use of tech to get your data in front of a pool of highly qualified humans, improving the speed of your project without sacrificing on the quality.
Sign up for the free insideBIGDATA newsletter.



Artificial Intelligence is used in a diverse field nowadays and helps to solve various problems. Artificial intelligence has enhanced the field like Education, defense, medical etc.