
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Hacking Neural Networks: A Short Introduction

A large chunk of research on the security issues of neural networks is focused on adversarial attacks. However, there exists a vast sea of simpler attacks one can perform both against and with neural networks. This paper gives a quick introduction on how deep learning in security works and explore the basic methods of exploitation, but also look at the offensive capabilities deep learning enabled tools provide. All presented attacks, such as backdooring, GPU-based buffer overflows or automated bug hunting, are accompanied by short open-source exercises for anyone to try out. The TensorFlow code for this paper can be found HERE.
Kaolin: A PyTorch Library for Accelerating 3D Deep Learning Research
This paper presents Kaolin, a PyTorch library aiming to accelerate 3D deep learning research. Kaolin provides efficient implementations of differentiable 3D modules for use in deep learning systems. With functionality to load and preprocess several popular 3D data sets, and native functions to manipulate meshes, pointclouds, signed distance functions, and voxel grids, Kaolin mitigates the need to write wasteful boilerplate code. Kaolin packages together several differentiable graphics modules including rendering, lighting, shading, and view warping. Kaolin also supports an array of loss functions and evaluation metrics for seamless evaluation and provides visualization functionality to render the 3D results. Importantly, we curate a comprehensive model zoo comprising many state-of-the-art 3D deep learning architectures, to serve as a starting point for future research endeavors. Kaolin is available as open-source software HERE.

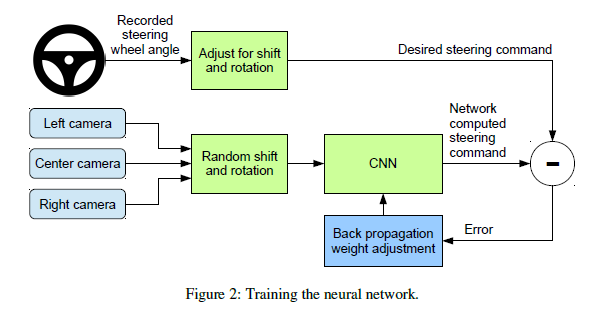
End to End Learning for Self-Driving Cars
The research detailed in this paper trained a convolutional neural network (CNN) to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads. The system automatically learns internal representations of the necessary processing steps such as detecting useful road features with only the human steering angle as the training signal. The NVIDIA researchers never explicitly trained it to detect, for example, the outline of roads. Compared to explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously. It’s argued that this will eventually lead to better performance and smaller systems.
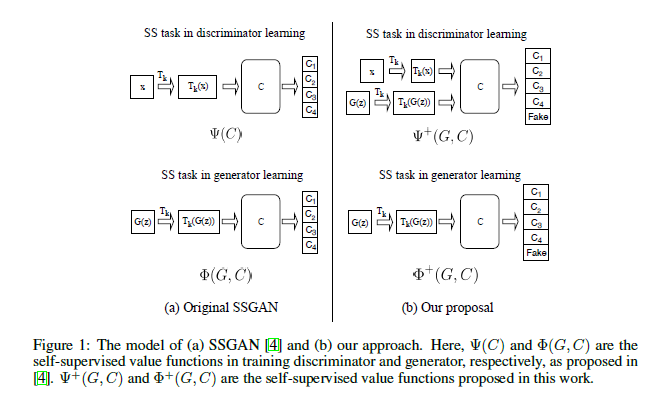
Self-supervised GAN: Analysis and Improvement with Multi-class Minimax Game
Self-supervised (SS) learning is a powerful approach for representation learning using unlabeled data. Recently, it has been applied to Generative Adversarial Networks (GAN) training. Specifically, SS tasks were proposed to address the catastrophic forgetting issue in the GAN discriminator. This paper performs an in-depth analysis to understand how SS tasks interact with learning of generator. From the analysis, there is an identification of issues of SS tasks which allow a severely mode-collapsed generator to excel the SS tasks. To address the issues, the researchers propose new SS tasks based on a multi-class minimax game. The competition between proposed SS tasks in the game encourages the generator to learn the data distribution and generate diverse samples. The paper provides both theoretical and empirical analysis to support that the proposed SS tasks have better convergence property. The TensorFlow code for this paper can be found HERE.
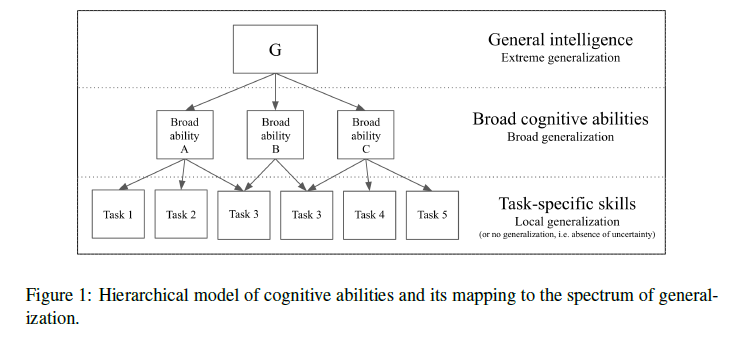
On the Measure of Intelligence
To make deliberate progress towards more intelligent and more human-like artificial systems, we need to be following an appropriate feedback signal: we need to be able to define and evaluate intelligence in a way that enables comparisons between two systems, as well as comparisons with humans. Over the past hundred years, there has been an abundance of attempts to define and measure intelligence, across both the fields of psychology and AI. This paper summarizes and critically assesses these definitions and evaluation approaches, while making apparent the two historical conceptions of intelligence that have implicitly guided them. It’s noted that in practice, the contemporary AI community still gravitates towards benchmarking intelligence by comparing the skill exhibited by AIs and humans at specific tasks such as board games and video games. The Google author argues that solely measuring skill at any given task falls short of measuring intelligence, because skill is heavily modulated by prior knowledge and experience: unlimited priors or unlimited training data allow experimenters to “buy” arbitrary levels of skills for a system, in a way that masks the system’s own generalization power. He then articulates a new formal definition of intelligence based on Algorithmic Information Theory, describing intelligence as skill-acquisition efficiency and highlighting the concepts of scope, generalization difficulty, priors, and experience. Using this definition, a set of guidelines is proposed for what a general AI benchmark should look like.
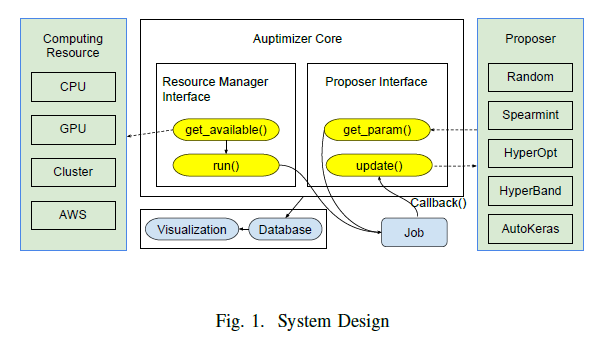
Auptimizer — an Extensible, Open-Source Framework for Hyperparameter Tuning
Tuning machine learning models at scale, especially finding the right hyperparameter values, can be difficult and time-consuming. In addition to the computational effort required, this process also requires some ancillary efforts including engineering tasks (e.g., job scheduling) as well as more mundane tasks (e.g., keeping track of the various parameters and associated results). This paper presents Auptimizer, a general Hyperparameter Optimization (HPO) framework to help data scientists speed up model tuning and bookkeeping. With Auptimizer, users can use all available computing resources in distributed settings for model training. The user-friendly system design simplifies creating, controlling, and tracking of a typical machine learning project. The code for the paper can be found HERE.
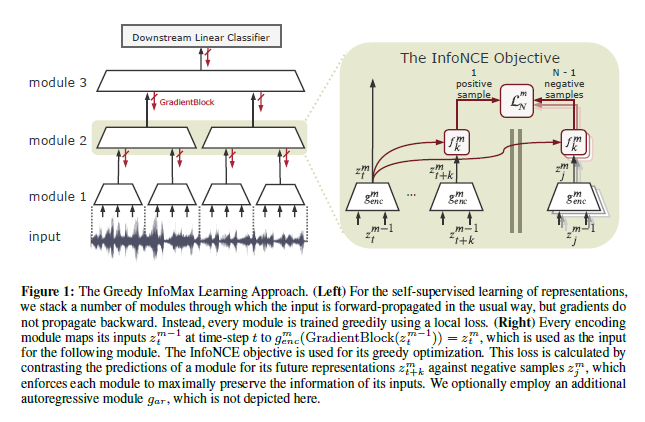
Putting An End to End-to-End:Gradient-Isolated Learning of Representations
This paper proposes a novel deep learning method for local self-supervised representation learning that does not require labels nor end-to-end backpropagation but exploits the natural order in data instead. Inspired by the observation that biological neural networks appear to learn without backpropagating a global error signal, the team split a deep neural network into a stack of gradient-isolated modules. Each module is trained to maximally preserve the information of its inputs using the InfoNCE bound from Oord et al. [2018]. Despite this greedy training, the results demonstrate that each module improves upon the output of its predecessor, and that the representations created by the top module yield highly competitive results on downstream classification tasks in the audio and visual domain. The proposal enables optimizing modules asynchronously, allowing large-scale distributed training of very deep neural networks on unlabelled data sets.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind