
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
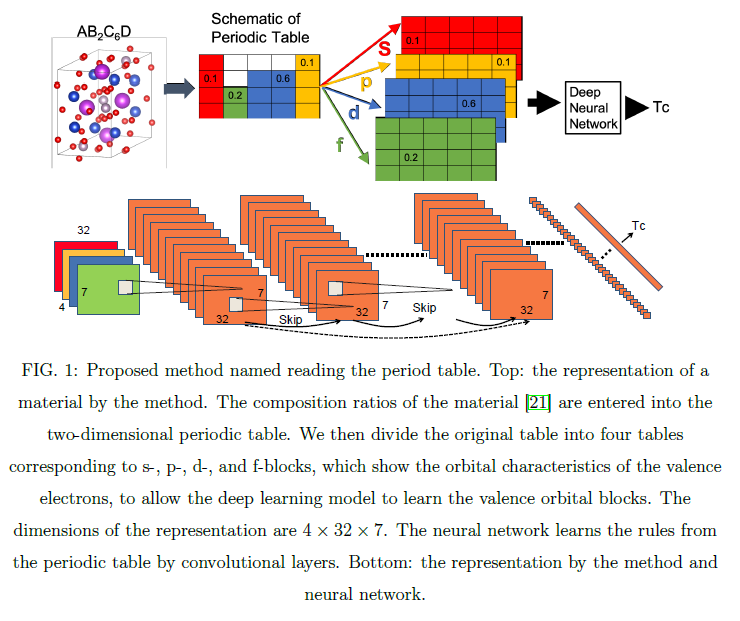
Deep Learning Model for Finding New Superconductors
Superconductivity has been extensively studied since its discovery in 1911. However, the feasibility of room-temperature superconductivity is unknown. It is very difficult for both theory and computational methods to predict the superconducting transition temperatures Tc of superconductors for strongly correlated systems, in which high-temperature superconductivity emerges. Exploration of new superconductors still relies on the experience and intuition of experts, and is largely a process of experimental trial and error. In one study, only 3% of the candidate materials showed superconductivity. The paper reports the first deep learning model for finding new superconductors. The periodic table is represented in a way that allows a deep learning model to learn it. The paper obtained three remarkable results. The deep learning method can predict superconductivity for a material with a precision of 62%, which shows the usefulness of the model; it found the recently discovered superconductor CaBi2, which is not in the superconductor database; and it found Fe-based high-temperature superconductors (discovered in 2008) from the training data before 2008. These results open the way for the discovery of new high-temperature superconductor families.
Causality for Machine Learning
Graphical causal inference as pioneered by Judea Pearl arose from research on artificial intelligence (AI), and for a long time had little connection to the field of machine learning. This paper discusses where links have been and should be established, introducing key concepts along the way. It argues that the hard open problems of machine learning and AI are intrinsically related to causality, and explains how the field is beginning to understand them.

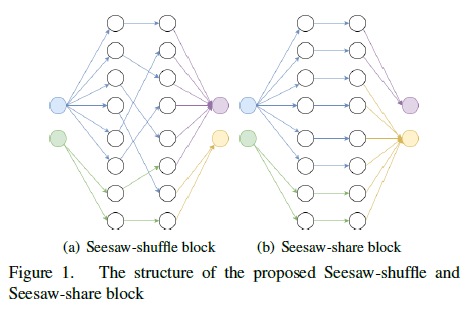
SeesawFaceNets: sparse and robust face verification model for mobile platform
Deep Convolutional Neural Network (DCNNs) come to be the most widely used solution for most computer vision related tasks, and one of the most important application scenes is face verification. Due to its high-accuracy performance, deep face verification models of which the inference stage occurs on cloud platform through internet plays the key role on most practical scenes. However, two critical issues exist: (i) individual privacy may not be well protected since they have to upload their personal photo and other private information to the online cloud back-end, and (ii) either training or inference stage is time-consuming and the latency may affect customer experience, especially when the internet link speed is not so stable or in remote areas where mobile reception is not so good, but also in cities where building and other construction may block mobile signals. Therefore, designing lightweight networks with low memory requirements and computational costs is one of the most practical solutions for face verification on mobile platform. In this paper, a novel mobile network named SeesawFaceNets, a simple but effective model, is proposed for productively deploying face recognition for mobile devices. The Pytorch code associated with the paper can be found HERE.
VIBE: Video Inference for Human Body Pose and Shape Estimation
Human motion is fundamental to understanding behavior. Despite progress on single-image 3D pose and shape estimation, existing video-based state-of-the-art methods fail to produce accurate and natural motion sequences due to a lack of ground-truth 3D motion data for training. To address this problem, this paper proposes Video Inference for Body Pose and Shape Estimation (VIBE), which makes use of an existing large-scale motion capture data set (AMASS) together with unpaired, in-the-wild, 2D key-point annotations. The key novelty is an adversarial learning framework that leverages AMASS to discriminate between real human motions and those produced by our temporal pose and shape regression networks. The researchers define a temporal network architecture and show that adversarial training, at the sequence level, produces kinematically plausible motion sequences without in-the-wild ground-truth 3D labels. Extensive experimentation is performed to analyze the importance of motion and demonstrate the effectiveness of VIBE on challenging 3D pose estimation data sets, achieving state-of-the-art performance. The PyTorch code associated with this paper can be found HERE.

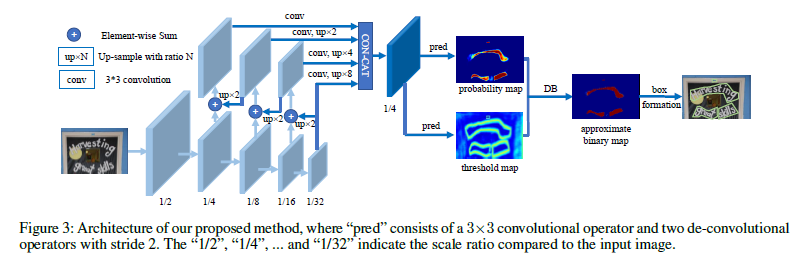
Real-time Scene Text Detection with Differentiable Binarization
Recently, segmentation-based methods are quite popular in scene text detection, as the segmentation results can more accurately describe scene text of various shapes such as curve text. However, the post-processing of binarization is essential for segmentation-based detection, which converts probability maps produced by a segmentation method into bounding boxes/regions of text. This paper proposes a module named Differentiable Binarization (DB), which can perform the binarization process in a segmentation network. Optimized along with a DB module, a segmentation network can adaptively set the thresholds for binarization, which not only simplifies the post-processing but also enhances the performance of text detection. Based on a simple segmentation network, the paper validates the performance improvements of DB on five benchmark data sets, which consistently achieves state-of-the-art results, in terms of both detection accuracy and speed. The PyTorch code associated with this paper can be found HERE.
CNN-generated images are surprisingly easy to spot… for now
This work in this paper asks whether it is possible to create a “universal” detector for telling apart real images from these generated by a CNN, regardless of architecture or data set used. To test this, the researchers collect a data set consisting of fake images generated by 11 different CNN-based image generator models, chosen to span the space of commonly used architectures today (ProGAN, StyleGAN, BigGAN, CycleGAN, StarGAN, GauGAN, DeepFakes, cascaded refinement networks, implicit maximum likelihood estimation, second-order attention super-resolution, seeing-in-the-dark). The work demonstrates that, with careful pre- and post-processing and data augmentation, a standard image classifier trained on only one specific CNN generator (ProGAN) is able to generalize surprisingly well to unseen architectures, data sets, and training methods (including the just released StyleGAN2). The findings suggest the intriguing possibility that today’s CNN-generated images share some common systematic flaws, preventing them from achieving realistic image synthesis.

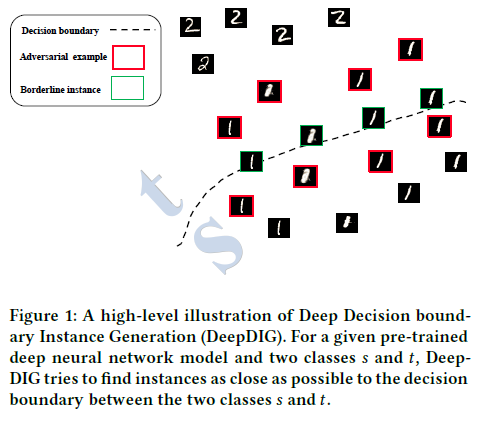
Characterizing the Decision Boundary of Deep Neural Networks

Deep neural networks and in particular, deep neural classifiers have become an integral part of many modern applications. Despite their practical success, we still have limited knowledge of how they work and the demand for such an understanding is ever growing. In this regard, one crucial aspect of deep neural network classifiers that can help us deepen our knowledge about their decision-making behavior is to investigate their decision boundaries. Nevertheless, this is contingent upon having access to samples populating the areas near the decision boundary. To achieve this, this paper proposes a novel approach called Deep Decision boundary Instance Generation (DeepDIG). DeepDIG utilizes a method based on adversarial example generation as an effective way of generating samples near the decision boundary of any deep neural network model. Then, a set of important principled characteristics are introduced that take advantage of the generated instances near the decision boundary to provide multifaceted understandings of deep neural networks.
BackPACK: Packing more into backprop
Automatic differentiation frameworks are optimized for exactly one thing: computing the average mini-batch gradient. Yet, other quantities such as the variance of the mini-batch gradients or many approximations to the Hessian can, in theory, be computed efficiently, and at the same time as the gradient. While these quantities are of great interest to researchers and practitioners, current deep-learning software does not support their automatic calculation. Manually implementing them is burdensome, inefficient if done naively, and the resulting code is rarely shared. This hampers progress in deep learning, and unnecessarily narrows research to focus on gradient descent and its variants; it also complicates replication studies and comparisons between newly developed methods that require those quantities, to the point of impossibility. To address this problem, this paper introduces BackPACK, an efficient framework built on top of PyTorch, that extends the backpropagation algorithm to extract additional information from first- and second-order derivatives. Its capabilities are illustrated by benchmark reports for computing additional quantities on deep neural networks, and an example application by testing several recent curvature approximations for optimization. The PyTorch code associated with this paper can be found HERE.

Sign up for the free insideBIGDATA newsletter.



Good