
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
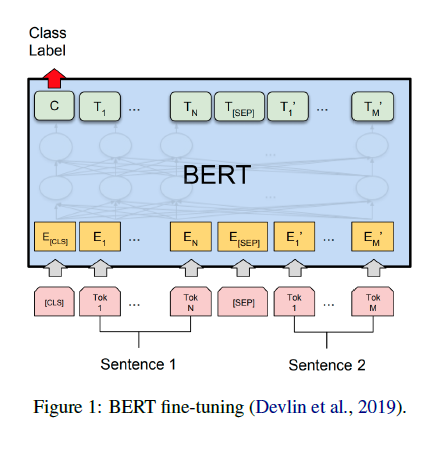
A Primer in BERTology: What we know about how BERT works

Transformer-based models are now widely used in NLP, but we still do not understand a lot about their inner workings. This paper describes what is known to date about the famous BERT model (Devlin et al. 2019), synthesizing over 40 analysis studies. Also provided is an overview of the proposed modifications to the model and its training regime. Also included is an outline of the directions for further research.
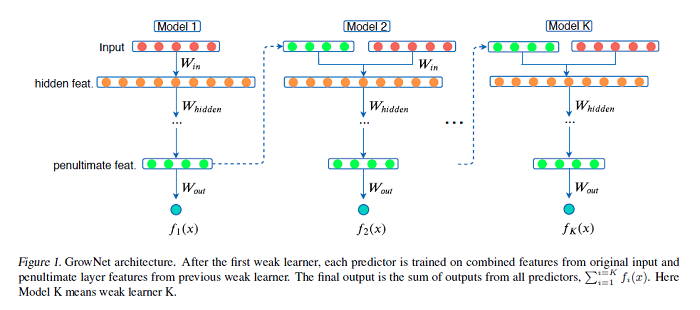
Gradient Boosting Neural Networks: GrowNet
A novel gradient boosting framework is proposed where shallow neural networks are employed as “weak learners.” General loss functions are considered under this unified framework with specific examples presented for classification, regression and learning to rank. A fully corrective step is incorporated to remedy the pitfall of greedy function approximation of classic gradient boosting decision tree. The proposed model rendered state-of-the-art results in all three tasks on multiple data sets. An ablation study is performed to shed light on the effect of each model components and model hyperparameters.
The Deep Learning Compiler: A Comprehensive Survey
The difficulty of deploying various deep learning (DL) models on diverse DL hardware has boosted the research and development of DL compilers in the community. Several DL compilers have been proposed from both industry and academia such as Tensorflow XLA and TVM. Similarly, the DL compilers take the DL models described in different DL frameworks as input, and then generate optimized codes for diverse DL hardware as output. However, none of the existing surveys has analyzed the unique design of the DL compilers comprehensively. This paper performs a comprehensive survey of existing DL compilers by dissecting the commonly adopted design in details, with emphasis on the DL oriented multi-level IRs, and frontend/backend optimizations. This is the first survey paper focusing on the unique design of DL compiler, and it is hoped this can pave the road for future research towards the DL compiler.
Stochastic Gradient Methods with Layer-wise Adaptive Moments for Training of Deep Networks
This paper proposes NovoGrad, an adaptive stochastic gradient descent method with layer-wise gradient normalization and decoupled weight decay. In experiments on neural networks for image classification, speech recognition, machine translation, and language modeling, it performs on par or better than well tuned SGD with momentum and Adam or AdamW. Additionally, NovoGrad (1) is robust to the choice of learning rate and weight initialization, (2) works well in a large batch setting, and (3) has two times smaller memory footprint than Adam.

GANILLA: Generative Adversarial Networks for Image to Illustration Translation
This paper explores illustrations in children’s books as a new domain in unpaired image-to-image translation. It’s shown that although the current state-of-the-art image-to-image translation models successfully transfer either the style or the content, they fail to transfer both at the same time. A new generator network is proposed to address this issue and show that the resulting network strikes a better balance between style and content. The PyTorch code for this paper can be found HERE.

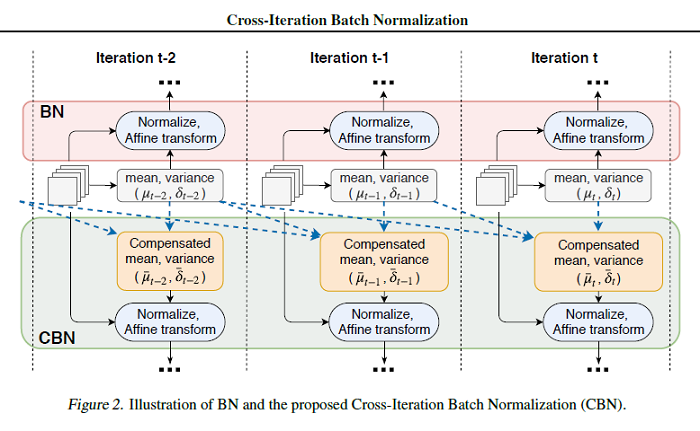
Cross-Iteration Batch Normalization
A well-known issue of Batch Normalization is its significantly reduced effectiveness in the case of small mini-batch sizes. When a mini-batch contains few examples, the statistics upon which the normalization is defined cannot be reliably estimated from it during a training iteration. To address this problem, this paper presents Cross-Iteration Batch Normalization (CBN), in which examples from multiple recent iterations are jointly utilized to enhance estimation quality. On object detection and image classification with small mini-batch sizes, CBN is found to outperform the original batch normalization and a direct calculation of statistics over previous iterations without the proposed compensation technique. The PyTorch code for this paper can be found HERE.
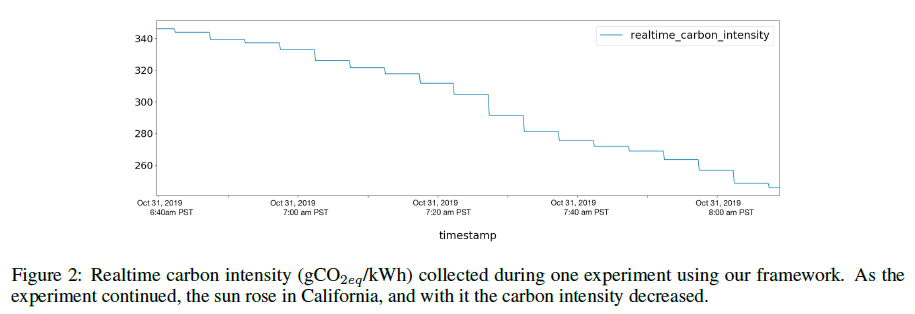
Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning
Accurate reporting of energy and carbon usage is essential for understanding the potential climate impacts of machine learning research. This paper introduces a framework that makes this easier by providing a simple interface for tracking real-time energy consumption and carbon emissions, as well as generating standardized online appendices. Utilizing this framework, the paper creates a leaderboard for energy efficient reinforcement learning algorithms to incentivize responsible research in this area as an example for other areas of machine learning. Finally, based on case studies using the framework, strategies for mitigation of carbon emissions and reduction of energy consumption are proposed. By making accounting easier, the hope is to further the sustainable development of machine learning experiments and spur more research into energy efficient algorithms. The code for this paper can be found HERE.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind