
In this special guest feature, Jörg Schad, Head of Machine Learning at ArangoDB, discusses the need for Machine Learning Metadata, solutions for storing and analyzing Metadata as well as the benefits for the different stakeholders. In a previous life, Jörg has worked on machine learning pipelines in healthcare and finance, distributed systems at Mesosphere, and in-memory databases. He received his Ph.D. for research around distributed databases and data analytics. He’s a frequent speaker at meetups, international conferences, and lecture halls.
It is a common fact that data is a crucial aspect for training Machine Learning Models. Especially when dealing with Deep Learning and Neural Networks the quality and quantity is one of the most important factors for Model accuracy.
Still, when productionizing Machine Learning we are not only concerned with building a single accurate model, but a platform on which we can enable us to build, rebuild, and serve multiple machine learning models (i.e., expose machine learning model to actual tasks/queries).
To build a production-grade Machine Learning Platform, there is another often overlooked type of data required: Metadata. It can include information about data sets, executions, features, models, and other artifacts from our Machine Learning Pipeline.
Metadata enables understanding the provenance of artifacts (e.g., “from which data set version was this model trained”) and hence is crucial for audit trails, data governance (think about GDPR or CCPA) and many other use-cases we will discuss in the remainder of this article.
What are Machine Learning Platforms?
But before diving deeper into the topic of Metadata, let us first look at Machine Learning Platforms. When thinking about Machine Learning, most people think about Machine Learning Frameworks such as TensorFlow, PyTorch, or MxNet and about training Machine Learning models. Unfortunately, dealing with Machine Learning code itself is only a very small fraction of the overall Machine Learning effort (for example Google shared some details on their effort allocation can be found in Hidden Technical Debt in Machine Learning Systems).
This is also reflected in the architecture of production-grade Machine Learning platforms. Here we typically find the a pipeline with the components shown in Figure 1 addressing the following challenges:
- Data Storage e.g., HDFS, Databases, or Cloud Storage
- Data Preprocessing and Feature Engineering, e.g., Spark, Jupyter Notebooks with various python Libraries, or TFX Transform
- Model Development and Training, e.g., TensorFlow, PyTorch, or MxNet
- Management of trained Models, e.g., DVC, ModelDB, or other DBMS
- Model Deployment and Serving e.g., TensorFlow Serving, Seldon.io, or NVIDIA TensorRT Inference Server
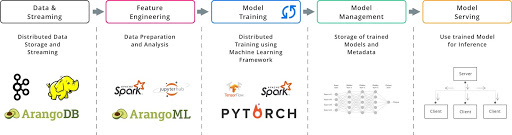
Often these pipelines are orchestrated by a a workflow scheduler such as Apache Airflow, Argo or Kubeflow Pipelines sometimes even allowing for continuous integration and deployment of updated models.
There exist a number of Machine Learning Platforms and probably the two most prominent Open Source solutions are TensorFlow Extended and Kubeflow. Another interesting OSS project for defining and managing Machine Learning Pipelines is MLflow.
Furthermore, most large Cloud Providers are offering a Machine Learning Platform including Google’s AI Platform, AWS’s Sagemaker, or Azure Machine Learning.
The Metadata Challenge
So with such an end-to-end Machine Learning Pipeline we can now develop, train, and manage models at scale.
But what about data governance and understanding the provenance of the deployed models? How can one identify all models derived from a particular dataset (which might have been identified to include incorrect data)? How can one justify high impact decisions (e.g., in health care or finance)? Further challenges of data governance might include:
- Audit trails
- Understanding the provenance of artifacts
- Version history of artifacts
- Comparing performance of different artifacts
- Identify reusable steps when building a new model
- Identifying a shift in the production data distribution compared to training data
To answer these questions one needs additional information from the Machine Learning Pipeline besides the actual model: Metadata capturing information about datasets, executions, features, models, and other artifacts from our Machine Learning Pipeline. Consider for example Metadata about a particular training run:
- Which features and model function have been used as input?
- What exact setting and other inputs have been used?
- What was the training, test, and validation performance?
- What type and amount of resources was required to train (i.e., how much did it cost)?
- What model has been created and where has it been persisted?
Some of the platform components might even store their own Metadata, for example the data storage component might provide information about different versions of a data set. But to be able to solve the above challenges it is critical to have a common view across the entire platform and not having to manually merge Metadata from different systems. A solution to these challenges can be provided by a common Metadata Layer for Machine Learning Platforms…
Common Metadata Layer
So what are options for such a common Metadata layer?
As this layer manages valuable data (i.e., audit relevant), database systems are a great fit as they already provide data governance features such as persistence, encryption or access control. When looking at different database systems as a backing store, one has to select between the different data models offered by relational and NoSQL database systems.
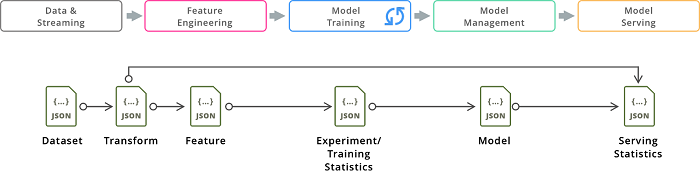
Here Metadata has interesting requirements also shown in Figure 2: on the one hand the Metadata associated with a single artifact (e.g., training statistics) nicely corresponds to a document data model, with a flexible schema. On the other hand the structure between different artifacts forms a graph structure, so would be a great fit for a graph database.
It is important to mention that in my experience over the years Machine Learning platforms tend to be highly flexible in both components used as well as workflow within a company but also over time as teams adapt quickly to new solutions.
In the recent past, first solutions to manage ML metadata have been published and many open-sourced. Next, let us look at some of these existing Metadata Management Solutions.
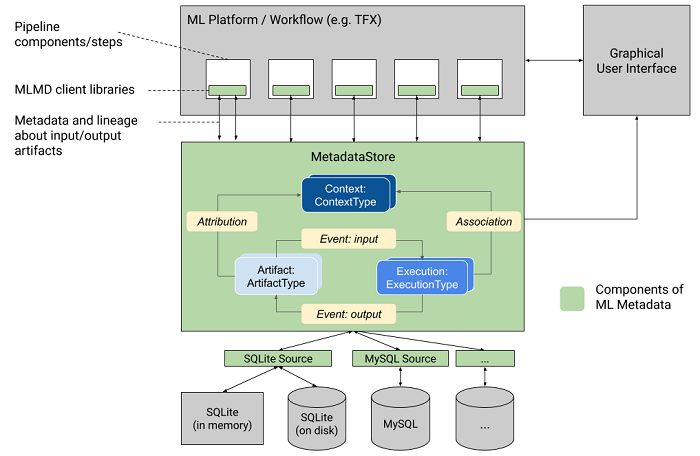
TensorFlow Extended ML Metadata
ML Metadata is “a library for recording and retrieving metadata associated with ML” and part of TensorFlow Extended (TFX), the ecosystem around the popular Machine Learning framework TensorFlow.
It is tightly integrated into the different pipeline components of TFX and so it is rather easy to collect the associated Metadata (in case you use components outside the TFX pipeline, it is a bit more challenging though).
ArangoML Pipeline
ArangoML Pipeline is an Open-Source project providing a common extensible Metadata layer for ML pipelines, which allows Data Scientists and DataOps to manage all information related to their ML pipelines.
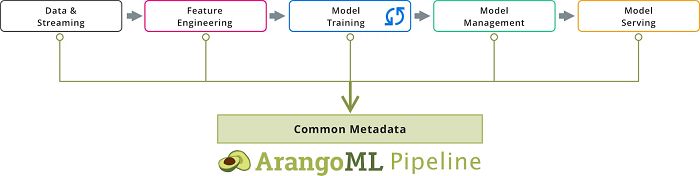
As ArangoML Pipeline is built on top of the Multi-Model Database ArangoDB, it allows queries across the entire platform to be formulated as simple graph queries: “Find all the models which are derived (i.e., have an path) from a particular data set”.
Furthermore, the graph model combined with the document model allows for a flexible structure as one can easily add new artifact types and also connect different artifacts types depending on the–potentially evolving–architecture of the Machine Learning Platform.
Implicit Metadata capture using HopsFS
Hopsworks is an Open Source ML platform built on top of HopsFS, an HDFS compatible Filesystem. As HopsFS is used as storage backend for all data and artifacts, the system can capture provenance and metadata implicitly by piggybacking on filesystem accesses.
MLFlow
MLFlow is “an open source platform for the machine learning lifecycle” and currently offers three components: Tracking, Projects, and Models.
The combination of the Models and Tracking components can be used to capture the model metadata (e.g., artifacts used to build a model) and experiment metadata. MLFlow offers–similar to ArangoML Pipeline–simple APIs (including a python and REST API) to explicitly capture metadata.
Metadata Analytics
Initially the Metadata layer is often targeted at DataOps professionals in order to provide them with audit and privacy relevant provenance trails across the Machine Learning Platform. But over time it turned out that Metadata also provides benefits and also for other personas including:
Data Scientist
- Finding relevant entities for given model
- Explore performance differences between different models (or features)
- Search for existing artifacts when developing a new model
- Capture all related settings for model training
DataOps
- Capture Audit trails
- Trace data lineage (e.g., for GDPR or CCPA requirements
- Enable reproducible model training
- Detect data shift when the production data distribution changes over time
DevOps (Infrastructure Owner)
- Resource accounting (keep in mind that especially distributed training is very resource intensive and costly)
- Permission tracking and enforcement
So the analysis of the captured Metadata allows for insights into the entire platform and is crucial for generating business value from the different machine learning models.
Sign up for the free insideBIGDATA newsletter.



This is a great big picture look at the ML life cycle in an enterprise setting. Increasingly, ML-as-a-Service platforms are touching every aspect of the process outlined as the toolset matures. So even mid-sized companies can cost-effectively develop, deploy, and monitor smart applications.
~Atakan Cetinsoy
BigML – Machine Learning made easy and beautiful for everyone.
Echoing Atakan’s sentiment, this does provide a nice picture of the ML lifecycle in certain settings. I’d like to add that as ML applications become more loosely used terms and conflate with more traditional SaaS platforms, AI objectives mature and evolve, it will be increasingly important to make distinctions on what outputs are being accomplished.