
In this special guest feature, Charles Fan, CEO of MemVerge, believes that in the years ahead, the data universe will continue to expand, and the new normal will be real-time analytics and AI/ML integrated into mainstream business apps … but only if in-memory computing infrastructure can keep pace. Prior to MemVerge, Charles was CTO of Cheetah Mobile, leading its technology teams in AI, big data and cloud. Charles received his Ph.D. and M.S. in Electrical Engineering from the California Institute of Technology, and his B.E. in Electrical Engineering from The Cooper Union.
Real-Time Analytics & AI/ML Are Becoming Mainstream
Business Intelligence (BI) technology is undergoing a major transformation. The change is driven by a tsunami of real-time data and the corresponding migration of real-time analytics and artificial intelligence into the BI mainstream. Real-time analytics and AI/ML are also technologies that need yet another new technology, called Big Memory, to continue their growth.

What People Don’t Know: “Real-Time” Data Will Swell to 30% of All Data by 2024
According to IDC, worldwide data is growing at a 26.0% CAGR, and in 2024 there will be 143 zettabytes of data. Real time data was less than 5% of all data in 2015, but will comprise almost 30% of all data by 2024. The analyst firm also projects that by 2021, 60-70% of the Global 2000 will have at least one mission-critical real-time workload.
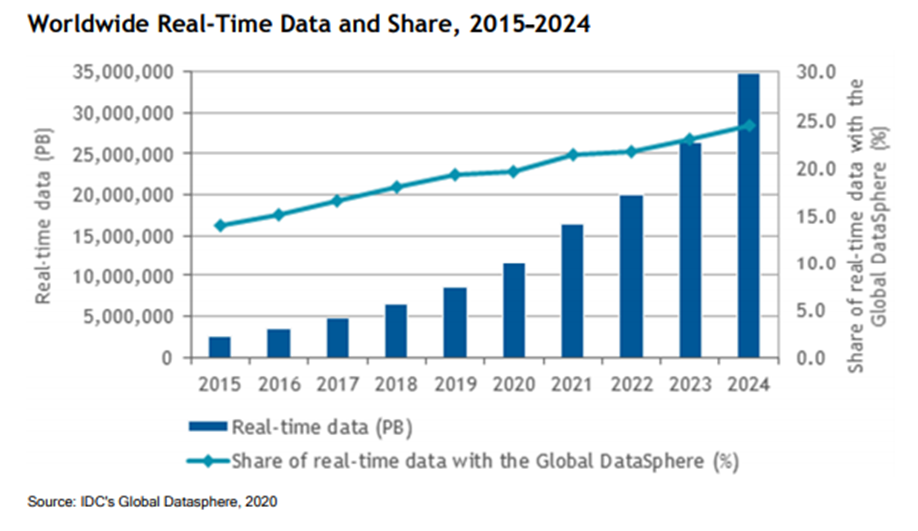
Big (Real-Time) Data Creates Challenges, Even for Apps Using In-Memory Computing
As data sets grow, business is calling for faster analysis, which leads to the need for augmented intelligence. According to the 2019 Artificial Intelligence Index report, 58% of large companies surveyed report adopting AI in at least one function or business unit in 2019, up from 47% in 2018.
Social media facial recognition, fraud detection, and retail recommendation engines are just a few examples of applications that rely on real-time analytics and AI/ML working together. The technologies produce a super-human ability to almost instantly analyze vast amounts of data and make decisions. But for each of these applications, providers are challenged with maintaining response times and business continuity as their data sets explode in size, even when using powerful in-memory computing systems.
In-memory computing was invented a decade ago to provide the performance needed by real-time analytics and AI/ML applications accessing hundreds of gigabytes of memory per server. But driven by the growth of data, today’s applications need to provide instantaneous response after working on hundreds of terabytes of data, and that’s where in-memory computing infrastructure is breaking down. DGM. Data is greater than memory.
Another problem emerged as memory capacity scaled-up. The blast zone for crashes grew to hundreds of gigabytes and enterprise-class protection for volatile memory simply did not exist. Recovery from crashes remains a painfully complex and time-consuming process. One financial services organization recently disrupted business for 3 hours to restore 500 gigabytes of data from storage to memory after a crash.
Big Memory. Where Memory is Abundant, Persistent and Highly Available
This new category of IT consists of DRAM and PMEM memory, plus a layer of Big Memory software that virtualizes the DRAM and PMEM. Together they create a platform for enterprise-class data services and massive pools of memory called memory lakes.
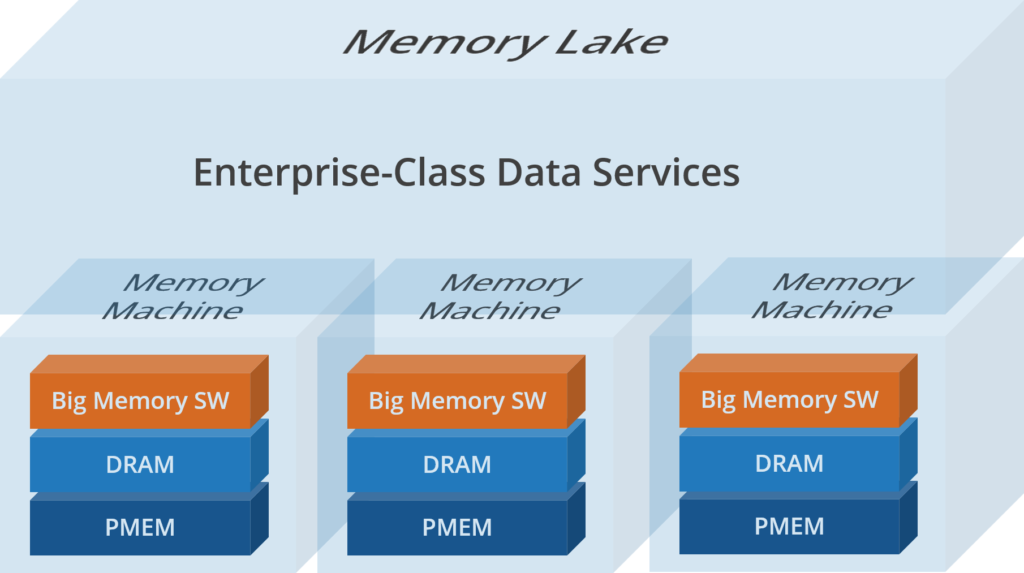
1. PMEM enables more memory. A key to putting the “Big” in Big Memory is the recent availability of high-density and affordable persistent memory (PMEM). PMEM 512GB DIMM modules offer 50% more capacity than the largest 256GB DRAM DIMMs, at one third to one fourth the cost per gigabyte.
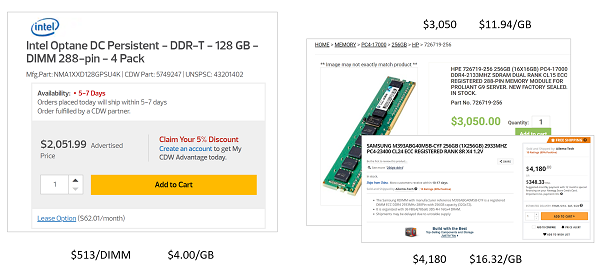

2. PMEM transforms memory from volatile to persistent. Although not quite as fast as DRAM, PMEM promises the magical ability to keep the data intact for lightning fast in-memory start-up and recovery.
3. Big Memory software enables transparent access to PMEM – without Big Memory software, applications must be modified to access persistent memory. This is a major obstacle to simple and fast deployment of PMEM and all its benefits. Big Memory software responds by virtualizing DRAM and PMEM so it’s transparent memory service can do the work needed for applications to access PMEM without code changes. Deployment of PMEM becomes simple and fast.
4. Big Memory software takes memory capacity to the next level – PMEM offers higher density memory modules. Big Memory software allows DRAM and high-density PMEM to scale-out in a cluster to form giant Memory Lakes with hundreds of terabytes in a single pool.
5. Big Memory software brings data services for high-availability – Big Memory software is a platform for a wide array of memory data services starting with snapshot, cloning, replication and fast recovery. The same type of data services that help disk and flash storage achieve high-availability, only performing at memory speeds.
The Bottom Line
In the years ahead, the data universe will continue to expand, and the new normal will be real-time analytics and AI/ML integrated into mainstream business apps … but only if in-memory computing infrastructure can keep pace. Therefore the bottom line is that Big Memory Computing–where memory is abundant, persistent, and highly-available–will succeed to unleash Big (real-time) Data.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind