
NetApp, a leading cloud data services provider has teamed up with Run:AI, a company virtualizing AI infrastructure, have teamed up to allow faster AI experimentation with full GPU utilization. The partnership allows teams to speed up AI by running many experiments in parallel, with fast access to data, utilizing limitless compute resources. Run:AI enables full GPU utilization by automating resource allocation, and NetApp® ONTAP® AI proven architecture allows every experiment to run at maximum speed by eliminating data pipeline bottlenecks. Together, teams scaling AI with NetApp and Run:AI technology see a double benefit: faster experiments on top of full resource utilization.
Speed is critically important in AI; fast experimentation and successful business outcomes of AI are directly correlated. And yet AI projects are rife with inefficient processes. The combination of data processing time and outdated storage solutions creates bottlenecks. In addition, workload orchestration issues and static allocation of GPU compute resources limit the number of experiments that researchers can run.
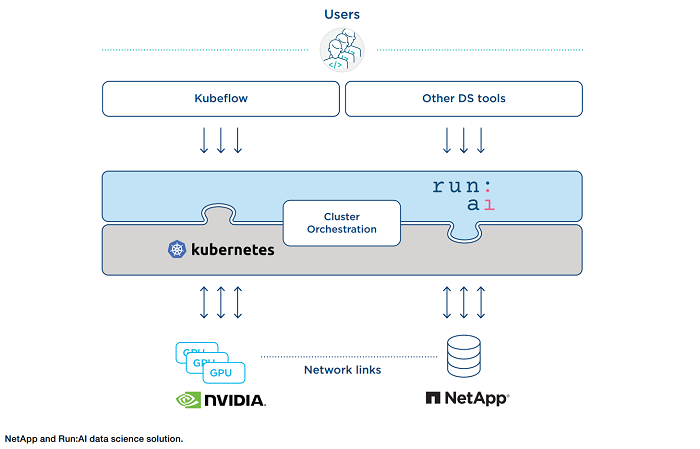
NetApp and Run:AI have partnered to simplify the orchestration of AI workloads, streamlining the process of both data pipelines and machine scheduling for deep learning (DL). Enterprises can fully realize the promise of AI and DL by simplifying, accelerating, and integrating their data pipeline with the NetApp ONTAP AI proven architecture. Run:AI’s orchestration of AI workloads adds a proprietary Kubernetes-based scheduling and resource utilization platform to help researchers manage and optimize GPU utilization. Together, the products enable numerous experiments to run in parallel on different compute nodes, with fast access to many datasets on centralized storage.
By using Run:AI’s centralized resource pooling, queueing, and prioritization mechanisms together with the NetApp storage system, researchers are removed from infrastructure management hassles and can focus exclusively on data science. With Run:AI and NetApp technology, they can increase productivity by running as many workloads as they need without compute or data pipeline bottlenecks.
Run:AI’s fairness algorithms guarantee that all users and teams get their fair share of resources. For example, they can preset policies for prioritization. With the Run:AI Scheduler and virtualization technology, researchers can easily use fractional GPUs, integer GPUs, and multiple nodes of GPUs for distributed training on Kubernetes. In this way, AI workloads run based on need, not capacity and data science teams can run more AI experiments on the same infrastructure.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind