
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
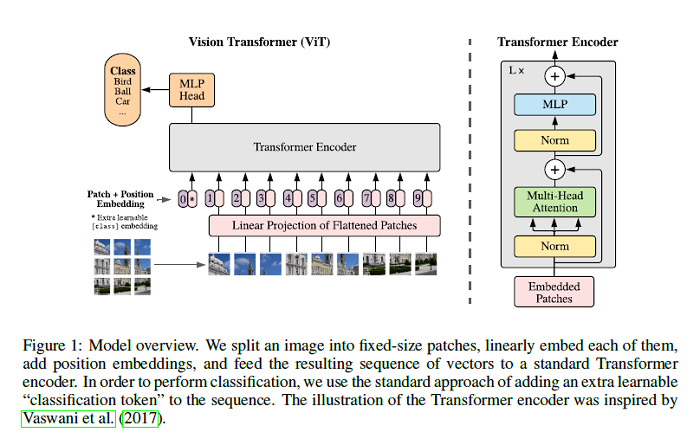
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale

While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. This paper shows that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train. The PyTorch code associated with this paper can be found HERE.
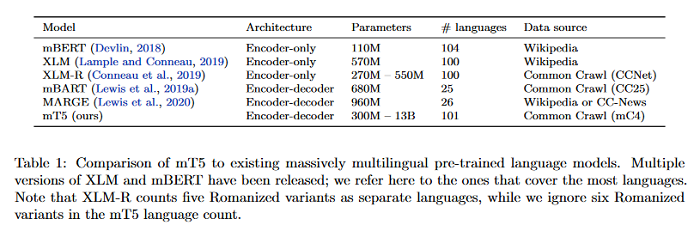
mT5: A massively multilingual pre-trained text-to-text transformer
The recent “Text-to-Text Transfer Transformer” (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. This paper introduces mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based data set covering 101 languages. Also described is the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the TensorFlow code and model checkpoints used in this work are publicly available HERE.
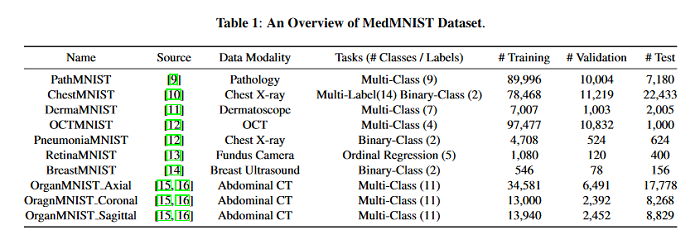
MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
This paper presents MedMNIST, a collection of 10 pre-processed medical open datasets. MedMNIST is standardized to perform classification tasks on lightweight 28×28 images, which requires no background knowledge. Covering the primary data modalities in medical image analysis, it is diverse on data scale (from 100 to 100,000) and tasks (binary/multi-class, ordinal regression and multi-label). MedMNIST could be used for educational purpose, rapid prototyping, multi-modal machine learning or AutoML in medical image analysis. Moreover, MedMNIST Classification Decathlon is designed to benchmark AutoML algorithms on all 10 datasets; The paper compares several baseline methods, including open-source or commercial AutoML tools. The data sets, evaluation PyTorch code and baseline methods for MedMNIST are publicly available HERE.
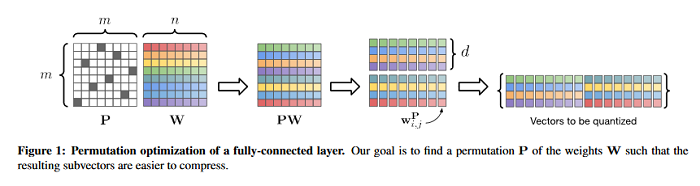
Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks
Compressing large neural networks is an important step for their deployment in resource-constrained computational platforms. In this context, vector quantization is an appealing framework that expresses multiple parameters using a single code, and has recently achieved state-of-the-art network compression on a range of core vision and natural language processing tasks. Key to the success of vector quantization is deciding which parameter groups should be compressed together. Previous work has relied on heuristics that group the spatial dimension of individual convolutional filters, but a general solution remains unaddressed. This is desirable for pointwise convolutions (which dominate modern architectures), linear layers (which have no notion of spatial dimension), and convolutions (when more than one filter is compressed to the same codeword). This paper makes the observation that the weights of two adjacent layers can be permuted while expressing the same function. A connection is then established to rate-distortion theory and search for permutations that result in networks that are easier to compress. Finally, an annealed quantization algorithm is used to better compress the network and achieve higher final accuracy. Results are shown on image classification, object detection, and segmentation, reducing the gap with the uncompressed model by 40 to 70% with respect to the current state of the art. The PyTorch code associated with this paper is available HERE.
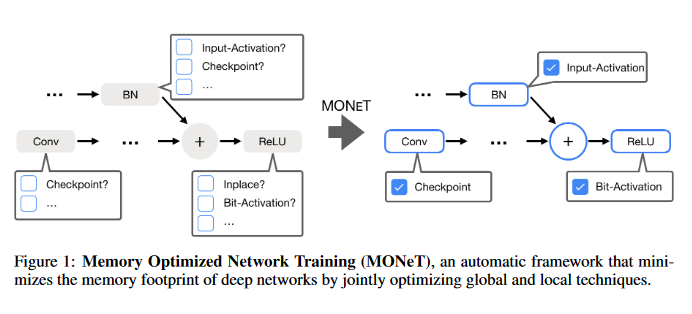
Memory Optimization for Deep Networks
Deep learning is slowly, but steadily, hitting a memory bottleneck. While the tensor computation in top-of-the-line GPUs increased by 32x over the last five years, the total available memory only grew by 2.5x. This prevents researchers from exploring larger architectures, as training large networks requires more memory for storing intermediate outputs. This paper presents MONeT, an automatic framework that minimizes both the memory footprint and computational overhead of deep networks. MONeT jointly optimizes the checkpointing schedule and the implementation of various operators. MONeT is able to outperform all prior hand-tuned operations as well as automated checkpointing. MONeT reduces the overall memory requirement by 3x for various PyTorch models, with a 9-16% overhead in computation. For the same computation cost, MONeT requires 1.2-1.8x less memory than current state-of-the-art automated checkpointing frameworks. The PyTorch code associated with this paper is available HERE.
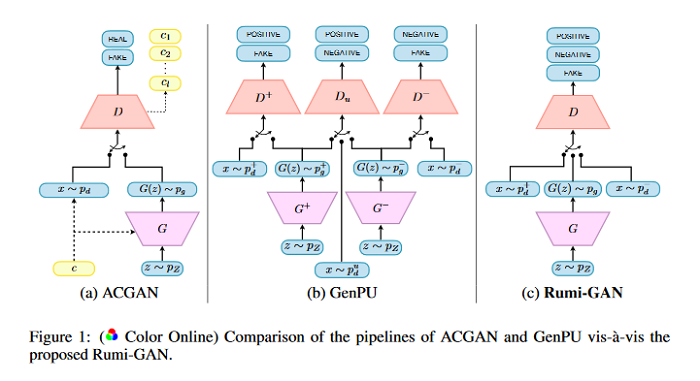
Teaching a GAN What Not to Learn
Generative adversarial networks (GANs) were originally envisioned as unsupervised generative models that learn to follow a target distribution. Variants such as conditional GANs, auxiliary-classifier GANs (ACGANs) project GANs on to supervised and semi-supervised learning frameworks by providing labelled data and using multi-class discriminators. This paper approaches the supervised GAN problem from a different perspective, one that is motivated by the philosophy of the famous Persian poet Rumi who said, “The art of knowing is knowing what to ignore.”
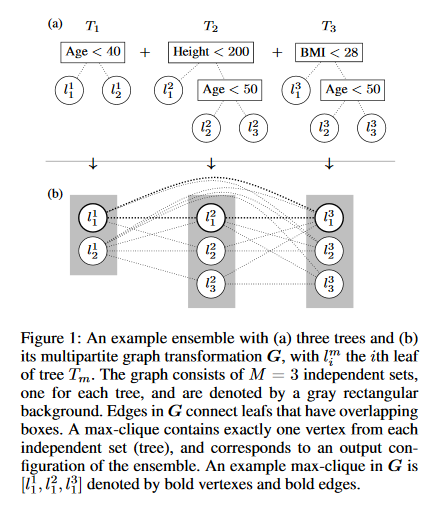
Versatile Verification of Tree Ensembles
Machine learned models often must abide by certain requirements (e.g., fairness or legal). This has spurred interested in developing approaches that can provably verify whether a model satisfies certain properties. This paper introduces a generic algorithm called Veritas that enables tackling multiple different verification tasks for tree ensemble models like random forests (RFs) and gradient boosting decision trees (GBDTs). This generality contrasts with previous work, which has focused exclusively on either adversarial example generation or robustness checking. Veritas formulates the verification task as a generic optimization problem and introduces a novel search space representation. Veritas offers two key advantages. First, it provides anytime lower and upper bounds when the optimization problem cannot be solved exactly. In contrast, many existing methods have focused on exact solutions and are thus limited by the verification problem being NP-complete. Second, Veritas produces full (bounded suboptimal) solutions that can be used to generate concrete examples. Experimentally, Veritas is shown to outperform the previous state of the art by (a) generating exact solutions more frequently, (b) producing tighter bounds when (a) is not possible, and (c) offering orders of magnitude speed ups. Subsequently, Veritas enables tackling more and larger real-world verification scenarios.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind