
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
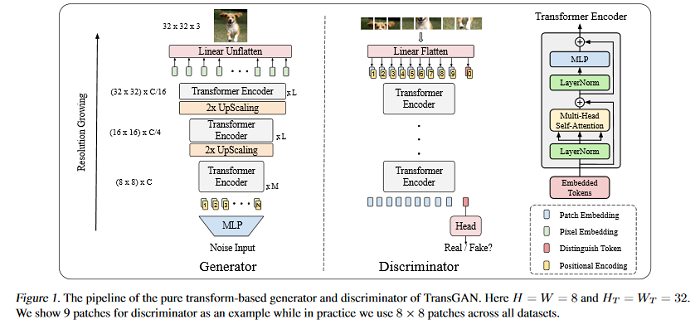
TransGAN: Two Transformers Can Make One Strong GAN
The recent explosive interest with transformers has suggested their potential to become powerful “universal” models for computer vision tasks, such as classification, detection, and segmentation. An important question is how much further transformers can go – are they ready to take some more notoriously difficult vision tasks, e.g., generative adversarial networks (GANs)? Driven by that curiosity, this paper conducts the first pilot study in building a GAN completely free of convolutions, using only pure transformer-based architectures. The proposed vanilla GAN architecture, dubbed TransGAN, consists of a memory-friendly transformer-based generator that progressively increases feature resolution while decreasing embedding dimension, and a patch-level discriminator that is also transformer-based. We see TransGAN to notably benefit from data augmentations (more than standard GANs), a multi-task co-training strategy for the generator, and a locally initialized self-attention that emphasizes the neighborhood smoothness of natural images. Equipped with those findings, TransGAN can effectively scale up with bigger models and high-resolution image datasets. Specifically, our the best architecture achieves highly competitive performance compared to current state-of-the-art GANs based on convolutional backbones. The code associated with this paper is available HERE.
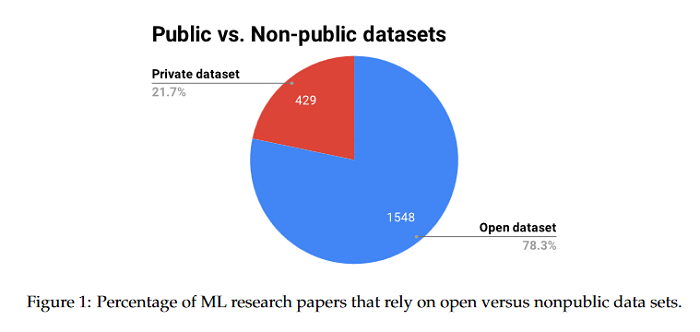
Data engineering is one of the fastest-growing fields within machine learning (ML). As ML becomes more common, the appetite for data grows more ravenous. But ML requires more data than individual teams of data engineers can readily produce, which presents a severe challenge to ML deployment at scale. Much like the software-engineering revolution, where mass adoption of open-source software replaced the closed, in-house development model for infrastructure code, there is a growing need to enable rapid development and open contribution to massive machine learning data sets. This paper shows that open-source data sets are the rocket fuel for research and innovation at even some of the largest AI organizations. The analysis of nearly 2000 research publications from Facebook, Google and Microsoft over the past five years shows the widespread use and adoption of open data sets. Open data sets that are easily accessible to the public are vital to accelerating ML innovation for everyone. But such open resources are scarce in the wild. So, what if we are able to accelerate data-set creation via automatic data set generation tools?
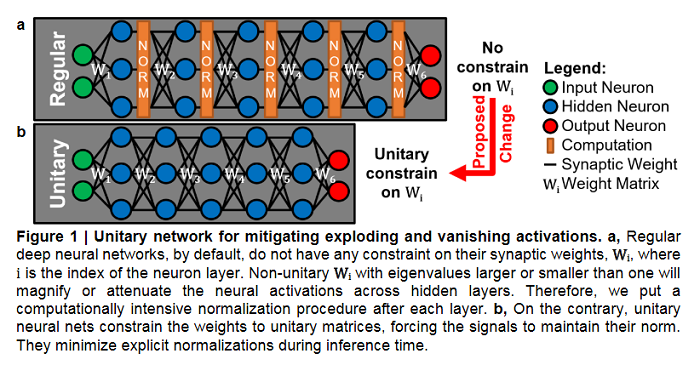
Deep Convolutional Neural Networks with Unitary Weights
While normalizations aim to fix the exploding and vanishing gradient problem in deep neural networks, they have drawbacks in speed or accuracy because of their dependency on the data set statistics. This paper is a comprehensive study of a novel method based on unitary synaptic weights derived from Lie Group to construct intrinsically stable neural systems. Here it’s shown that unitary convolutional neural networks deliver up to 32% faster inference speeds while maintaining competitive prediction accuracy. Unlike prior arts restricted to square synaptic weights, the paper expands the unitary networks to weights of any size and dimension.
QuPeL: Quantized Personalization with Applications to Federated Learning
Traditionally, federated learning (FL) aims to train a single global model while collaboratively using multiple clients and a server. Two natural challenges that FL algorithms face are heterogeneity in data across clients and collaboration of clients with diverse resources. This paper introduces a quantized and personalized FL algorithm QuPeL that facilitates collective training with heterogeneous clients while respecting resource diversity. For personalization, clients are allowed to learn compressed personalized models with different quantization parameters depending on their resources. Towards this, an algorithm is proposed for learning quantized models through a relaxed optimization problem, where quantization values are also optimized over. When each client participating in the (federated) learning process has different requirements of the quantized model (both in value and precision), a quantized personalization framework is formulated by introducing a penalty term for local client objectives against a globally trained model to encourage collaboration.

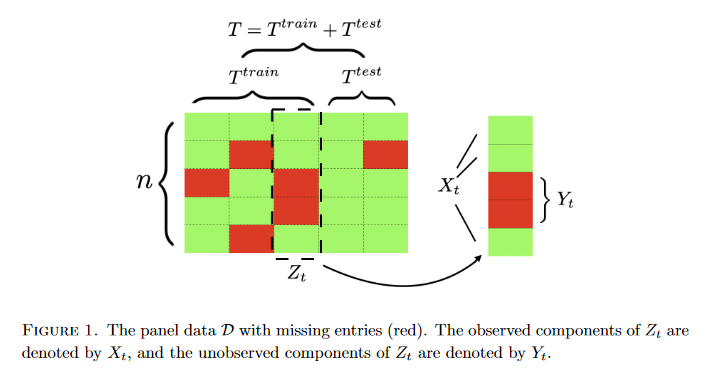
Missing time-series data is a prevalent practical problem. Imputation methods in time-series data often are applied to the full panel data with the purpose of training a model for a downstream out-of-sample task. For example, in finance, imputation of missing returns may be applied prior to training a portfolio optimization model. Unfortunately, this practice may result in a look-ahead-bias in the future performance on the downstream task. There is an inherent trade-off between the look-ahead-bias of using the full data set for imputation and the larger variance in the imputation from using only the training data. By connecting layers of information revealed in time, this paper proposes a Bayesian posterior consensus distribution which optimally controls the variance and look-ahead-bias trade-off in the imputation. The benefit of the methodology both in synthetic and real financial data is demonstrated.
Automatic Story Generation: Challenges and Attempts

The scope of this survey paper is to explore the challenges in automatic story generation. The goal is to contribute in the following ways: 1. Explore how previous research in story generation addressed those challenges. 2. Discuss future research directions and new technologies that may aid more advancements. 3. Shed light on emerging and often overlooked challenges such as creativity and discourse.
Constrained Optimization for Training Deep Neural Networks Under Class Imbalance
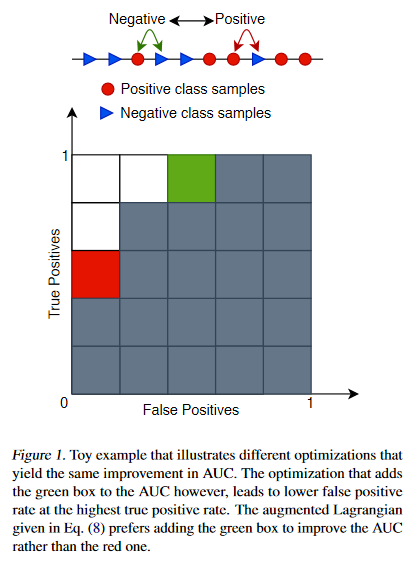
Deep neural networks (DNNs) are notorious for making more mistakes for the classes that have substantially fewer samples than the others during training. Such class imbalance is ubiquitous in clinical applications and very crucial to handle because the classes with fewer samples most often correspond to critical cases (e.g., cancer) where misclassifications can have severe consequences. Not to miss such cases, binary classifiers need to be operated at high True Positive Rates (TPR) by setting a higher threshold but this comes at the cost of very high False Positive Rates (FPR) for problems with class imbalance. Existing methods for learning under class imbalance most often do not take this into account. This paper argues that prediction accuracy should be improved by emphasizing reducing FPRs at high TPRs for problems where misclassification of the positive samples are associated with higher cost. To this end, it’s posed the training of a DNN for binary classification as a constrained optimization problem and introduce a novel constraint that can be used with existing loss functions to enforce maximal area under the ROC curve (AUC). The resulting constrained optimization problem is solved using an Augmented Lagrangian method (ALM), where the constraint emphasizes reduction of FPR at high TPR. Results demonstrate that the proposed method almost always improves the loss functions it is used with by attaining lower FPR at high TPR and higher or equal AUC.
Attention Models for Point Clouds in Deep Learning: A Survey
Recently, the advancement of 3D point clouds in deep learning has attracted intensive research in different application domains such as computer vision and robotic tasks. However, creating feature representation of robust, discriminative from unordered and irregular point clouds is challenging. The goal of this paper is to provide a comprehensive overview of the point clouds feature representation which uses attention models. More than 75+ key contributions in the recent three years are summarized in this survey, including the 3D objective detection, 3D semantic segmentation, 3D pose estimation, point clouds completion etc. Also provided are: a detailed characterization (1) the role of attention mechanisms, (2) the usability of attention models into different tasks, (3) the development trend of key technology.
Towards Causal Representation Learning
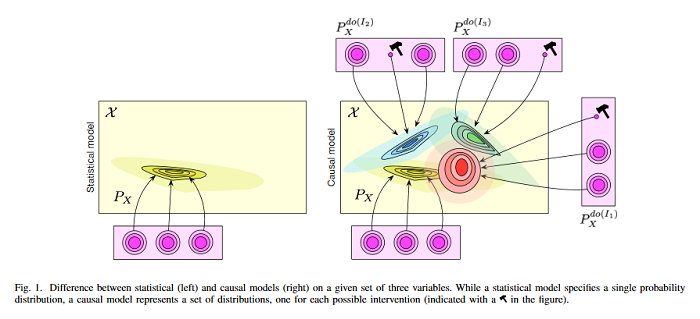
The two fields of machine learning and graphical causality arose and developed separately. However, there is now cross-pollination and increasing interest in both fields to benefit from the advances of the other. This paper reviews fundamental concepts of causal inference and relate them to crucial open problems of machine learning, including transfer and generalization, thereby assaying how causality can contribute to modern machine learning research. This also applies in the opposite direction: we note that most work in causality starts from the premise that the causal variables are given. A central problem for AI and causality is, thus, causal representation learning, the discovery of high-level causal variables from low-level observations. Finally, the paper delineates some implications of causality for machine learning and propose key research areas at the intersection of both communities.
An Evaluation of Edge TPU Accelerators for Convolutional Neural Networks
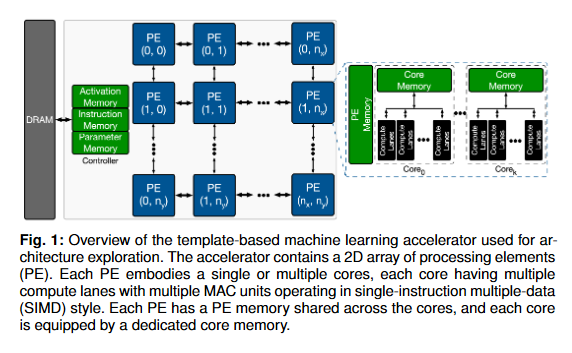
Edge TPUs are a domain of accelerators for low-power, edge devices and are widely used in various Google products such as Coral and Pixel devices. This paper first discusses the major microarchitectural details of Edge TPUs. This is followed by an extensive evaluation of three classes of Edge TPUs, covering different computing ecosystems, that are either currently deployed in Google products or are the product pipeline, across 423K unique convolutional neural networks. Building upon this extensive study, the paper discusses critical and interpretable microarchitectural insights about the studied classes of Edge TPUs. Mainly discussed is how Edge TPU accelerators perform across convolutional neural networks with different structures. Finally, the paper presents ongoing efforts in developing high-accuracy learned machine learning models to estimate the major performance metrics of accelerators such as latency and energy consumption. These learned models enable significantly faster (in the order of milliseconds) evaluations of accelerators as an alternative to time-consuming cycle-accurate simulators and establish an exciting opportunity for rapid hard-ware/software co-design.
Improving DeepFake Detection Using Dynamic Face Augmentation
The creation of altered and manipulated faces has become more common due to the improvement of DeepFake generation methods. Simultaneously, we have seen detection models’ development for differentiating between a manipulated and original face from image or video content. We have observed that most publicly available DeepFake detection datasets have limited variations, where a single face is used in many videos, resulting in an oversampled training dataset. Due to this, deep neural networks tend to overfit to the facial features instead of learning to detect manipulation features of DeepFake content. As a result, most detection architectures perform poorly when tested on unseen data. This paper provides a quantitative analysis to investigate this problem and present a solution to prevent model overfitting due to the high volume of samples generated from a small number of actors.

Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind