
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
KNAS – Green Neural Architecture Search
Many existing neural architecture search (NAS) solutions rely on downstream training for architecture evaluation, which takes enormous computations. Considering that these computations bring a large carbon footprint, this paper aims to explore a green (namely environmental-friendly) NAS solution that evaluates architectures without training. Intuitively, gradients, induced by the architecture itself, directly decide the convergence and generalization results. This paper proposes the gradient kernel hypothesis: Gradients can be used as a coarse-grained proxy of downstream training to evaluate random-initialized networks. To support the hypothesis, a theoretical analysis was conducted to find a practical gradient kernel that has good correlations with training loss and validation performance. According to this hypothesis, a new kernel based architecture search approach KNAS was proposed. Experiments show that KNAS achieves competitive results with orders of magnitude faster than “train-then-test” paradigms on image classification tasks. Furthermore, the extremely low search cost enables its wide applications. The searched network also outperforms strong baseline RoBERTA-large on two text classification tasks. The GitHub report associates with this paper can be found HERE.
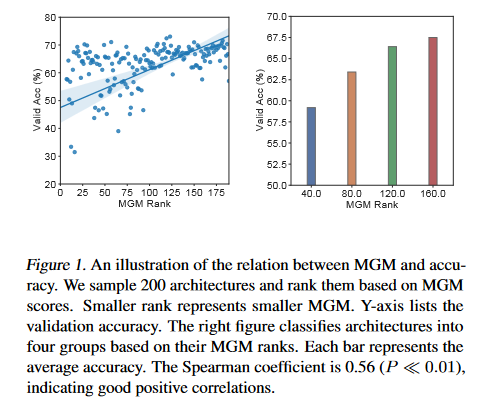
Swin Transformer V2: Scaling Up Capacity and Resolution
This paper presents techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,5361,536 resolution. By scaling up capacity and resolution, Swin Transformer sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1/54.4 box/mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification. The techniques discussed are generally applicable for scaling up vision models, which has not been widely explored as that of NLP language models, partly due to the following difficulties in training and applications: 1) vision models often face instability issues at scale and 2) many downstream vision tasks require high resolution images or windows and it is not clear how to effectively transfer models pre-trained at low resolutions to higher resolution ones. The GPU memory consumption is also a problem when the image resolution is high. The GitHub repo associated with this paper can be found HERE.
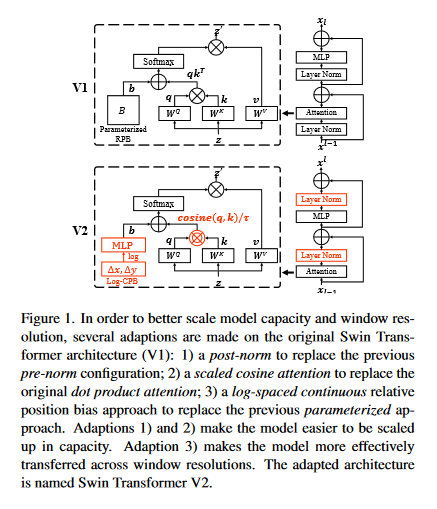
Although state-of-the-art object detection methods have shown compelling performance, models often are not robust to adversarial attacks and out-of-distribution data. This paper introduces a new dataset, Natural Adversarial Objects (NAO), to evaluate the robustness of object detection models. NAO contains 7,934 images and 9,943 objects that are unmodified and representative of real-world scenarios, but cause state-of-the-art detection models to misclassify with high confidence. The mean average precision (mAP) of EfficientDet-D7 drops 74.5% when evaluated on NAO compared to the standard MSCOCO validation set. Moreover, by comparing a variety of object detection architectures, it’s found that better performance on MSCOCO validation set does not necessarily translate to better performance on NAO, suggesting that robustness cannot be simply achieved by training a more accurate model. NAO can be downloaded HERE.
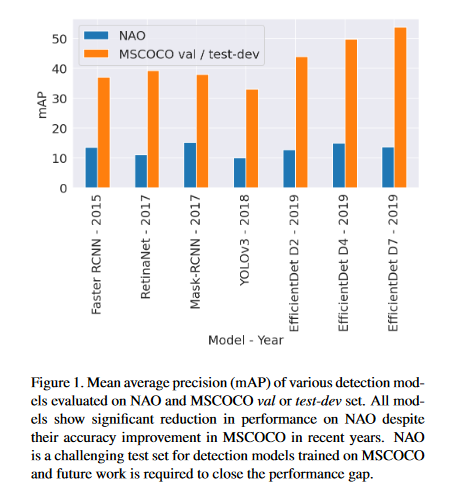
Is Dynamic Rumor Detection on social media Viable? An Unsupervised Perspective
With the growing popularity and ease of access to the internet, the problem of online rumors is escalating. People are relying on social media to gain information readily but fall prey to false information. There is a lack of credibility assessment techniques for online posts to identify rumors as soon as they arrive. Existing studies have formulated several mechanisms to combat online rumors by developing machine learning and deep learning algorithms. The literature so far provides supervised frameworks for rumor classification that rely on huge training datasets. However, in the online scenario where supervised learning is exigent, dynamic rumor identification becomes difficult. Early detection of online rumors is a challenging task, and studies relating to them are relatively few. It is the need of the hour to identify rumors as soon as they appear online. This paper proposes a novel framework for unsupervised rumor detection that relies on an online post’s content and social features using state-of-the-art clustering techniques. The proposed architecture outperforms several existing baselines and performs better than several supervised techniques. The proposed method, being lightweight, simple, and robust, offers the suitability of being adopted as a tool for online rumor identification.
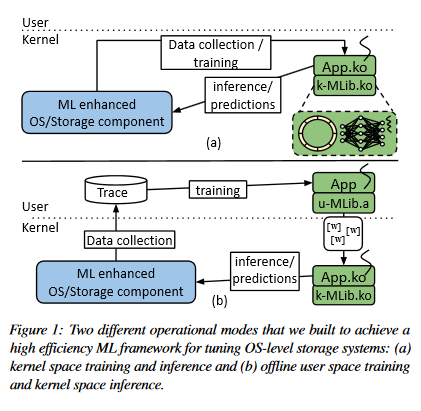
KML – Using Machine Learning to Improve Storage Systems
Operating systems include many heuristic algorithms designed to improve overall storage performance and throughput. Because such heuristics cannot work well for all conditions and workloads, system designers resorted to exposing numerous tunable parameters to users – essentially burdening users with continually optimizing their own storage systems and applications. Storage systems are usually responsible for most latency in I/O heavy applications, so even a small overall latency improvement can be significant. Machine learning (ML) techniques promise to learn patterns, generalize from them, and enable optimal solutions that adapt to changing workloads. This paper proposes that ML solutions become a first-class component in OSs and replace manual heuristics to optimize storage systems dynamically. The paper describes a proposed ML architecture, called KML. The researchers developed a prototype KML architecture and applied it to two problems: optimal readahead and NFS read-size values. The experiments show that KML consumes little OS resources, adds negligible latency, and yet can learn patterns that can improve I/O throughput by as much as 2.3x or 15x for the two use cases respectively – even for complex, never-before-seen, concurrently running mixed workloads on different storage devices.
Generative Adversarial Networks for Astronomical Images Generation

Space exploration has always been a source of inspiration for humankind, and thanks to modern telescopes, it is now possible to observe celestial bodies far away from us. With a growing number of real and imaginary images of space available on the web and exploiting modern deep Learning architectures such as Generative Adversarial Networks, it is now possible to generate new representations of space. In this research, using a Lightweight GAN, a dataset of images obtained from the web, and the Galaxy Zoo Dataset, thousands of new images of celestial bodies, galaxies have been generated, and finally, by combining them, a wide view of the universe. The GitHub repo associated with this paper can be found HERE. and the generated images can be explored HERE. at

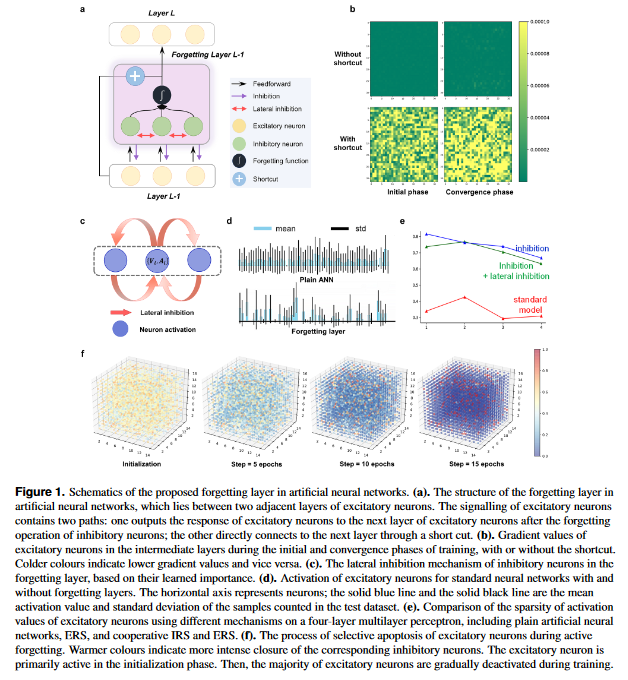
Learning by Active Forgetting for Neural Networks
Remembering and forgetting mechanisms are two sides of the same coin in a human learning-memory system. Inspired by human brain memory mechanisms, modern machine learning systems have been working to endow machine with lifelong learning capability through better remembering while pushing the forgetting as the antagonist to overcome. Nevertheless, this idea might only see the half picture. Up until very recently, increasing researchers argue that a brain is born to forget, i.e., forgetting is a natural and active process for abstract, rich, and flexible representations. This paper presents a learning model by active forgetting mechanism with artificial neural networks. The active forgetting mechanism (AFM) is introduced to a neural network via a “plug-and-play” forgetting layer (P&PF), consisting of groups of inhibitory neurons with Internal Regulation Strategy (IRS) to adjust the extinction rate of themselves via lateral inhibition mechanism and External Regulation Strategy (ERS) to adjust the extinction rate of excitatory neurons via inhibition mechanism. Experimental studies have shown that the P&PF offers surprising benefits: self-adaptive structure, strong generalization, long-term learning and memory, and robustness to data and parameter perturbation. This work sheds light on the importance of forgetting in the learning process and offers new perspectives to understand the underlying mechanisms of neural networks.
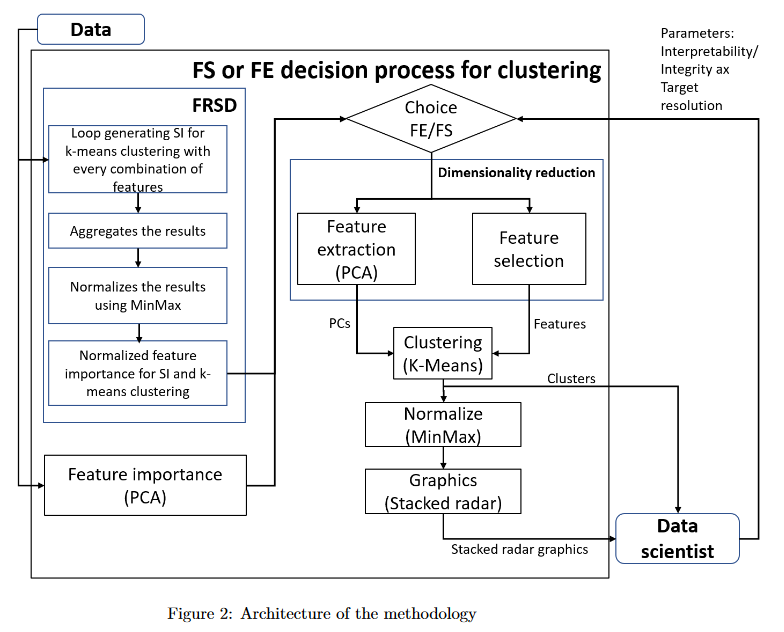
Feature selection or extraction decision process for clustering using PCA and FRSD
This paper concerns the critical decision process of extracting or selecting the features before applying a clustering algorithm. It is not obvious to evaluate the importance of the features since the most popular methods to do it are usually made for a supervised learning technique process. A clustering algorithm is an unsupervised method. It means that there is no known output label to match the input data. This paper proposes a new method to choose the best dimensionality reduction method (selection or extraction) according to the data scientist’s parameters, aiming to apply a clustering process at the end. It uses Feature Ranking Process Based on Silhouette Decomposition (FRSD) algorithm, a Principal Component Analysis (PCA) algorithm, and a K-Means algorithm along with its metric, the Silhouette Index (SI). This paper presents 5 use cases based on a smart city dataset. This research also aims to discuss the impacts, the advantages, and the disadvantages of each choice that can be made in this unsupervised learning process.
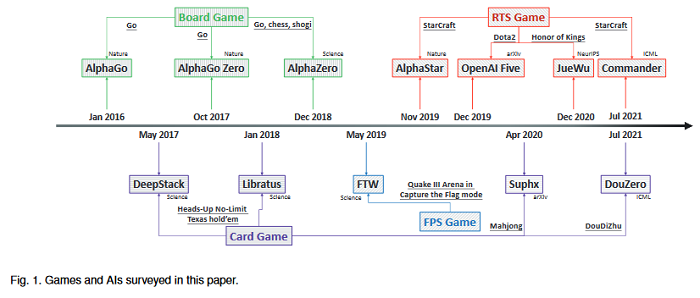
AI in Games: Techniques, Challenges and Opportunities
With breakthrough of AlphaGo, AI in human-computer game has become a very hot topic attracting researchers all around the world, which usually serves as an effective standard for testing artificial intelligence. Various game AI systems (AIs) have been developed such as Libratus, OpenAI Five and AlphaStar, beating professional human players. This paper surveys recent successful game AIs, covering board game AIs, card game AIs, first-person shooting game AIs and real time strategy game AIs. This survey: 1) compares the main difficulties among different kinds of games for the intelligent decision making field ; 2) illustrates the mainstream frameworks and techniques for developing professional level AIs; 3) raises the challenges or drawbacks in the current AIs for intelligent decision making; and 4) tries to propose future trends in the games and intelligent decision making techniques. Finally, the hope is that this brief review can provide an introduction for beginners, inspire insights for researchers in the filed of AI in games.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind