
By Matt Casey, Snorkel AI
Large language models (LLMs) have fascinated the public and upended data team priorities since ChatGPT arrived in November 2022. While the roots of technology stretch further into the past than you might think—all the way to the 1950s, when researchers at IBM and Georgetown University developed a system to automatically translate a collection of phrases from Russian to English—the modern age of large language models began only a few years ago.
The early days of natural language processing saw researchers experiment with many different approaches, including conceptual ontologies and rule-based systems. While some of these methods proved narrowly useful, none yielded robust results. That changed in the 2010s when NLP research intersected with the then-bustling field of neural networks. The collision laid the ground for the first large language models.
This post, adapted and excerpted from one on Snorkel.ai entitled “Large language models: their history, capabilities, and limitations,” follows the history of LLMs from that first intersection to their current state.
BERT, the first breakout large language model
In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers).
Their new model combined several ideas into something surprisingly simple and powerful. By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. By using a neural network architecture with a consistent width throughout, the researchers allowed the model to adapt to a variety of tasks. And, by pre-training BERT in a self-supervised manner on a wide variety of unstructured data, the researchers created a model rich with the understanding of relationships between words.
All of this made it easy for researchers and practitioners to use BERT. As the original researchers explained, “the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks.”
At its debut, BERT shattered the records for a suite of NLP benchmark tests. Within a short time, BERT became the standard tool for NLP tasks. Researchers adapted and built upon it in a way that made it one of the original foundation models. Less than 18 months after its debut, BERT powered nearly every English-language query processed by Google Search.
Bigger than BERT
At the time of its debut, BERT’s 340 million parameters tied it as the largest language model of its kind. (The tie was a deliberate choice; the researchers wanted it to have the same number of parameters as GPT to simplify performance comparisons.) That size is quaint according to modern comparisons.
From 2018 to the modern day, NLP researchers have engaged in a steady march toward ever-larger models. Hugging Face’s Julien Simon called this steady increase a “new Moore’s Law.”
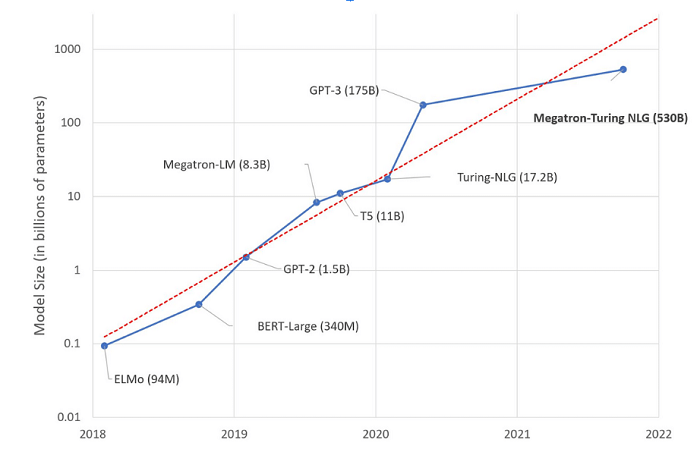
As large language models grew, they improved. OpenAI’s GPT-2, finalized in 2019 at 1.5 billion parameters, raised eyebrows by producing convincing prose. GPT-2’s impressive performance gave OpenAI pause; the company announced in February of that year that it wouldn’t release the full-sized version of the model immediately, due to “concerns about large language models being used to generate deceptive, biased, or abusive language at scale.” Instead, they released a smaller, less-compelling version of the model at first, and followed up with several increasingly-large variations.
Next, OpenAI released GPT-3 in June of 2020. At 175 billion parameters, GPT-3 set the new size standard for large language models. It quickly became the focal point for large language model research and served as the original underpinning of ChatGPT.
Most recently, OpenAI debuted GPT-4. At the time of this writing, OpenAI has not publicly stated GPT-4’s parameter count, but one estimate based on conversations with OpenAI employees put it at one trillion parameters—five times the size of GPT-3 and nearly 3,000 times the size of the original large version of BERT. The gargantuan model represented a meaningful improvement over its predecessors, allowing users to process up to 50 pages of text at once and reducing the incidence of “hallucinations” that plagued GPT-3.
The ChatGPT moment
While researchers and practitioners devised and deployed variations of BERT, GPT-2, GPT-3, and T5, the public took little notice. Evidence of the models’ impacts surfaced on websites in the form of summarized reviews and better search results. The most direct examples of the existing LLMs, as far as the general public was concerned, was a scattering of news stories written in whole or in part by GPT variations.
Then OpenAI released ChatGPT in Novermber 2022. The interactive chat simulator allowed non-technical users to prompt the LLM and quickly receive a response. As the user sent additional prompts, the system would take previous prompts and responses into account, giving the interaction conversation-like continuity.
The new tool caused a stir. The scattering of LLM-aided news reports became a tidal wave, as local reporters across the U.S. produced stories about ChatGPT, most of which revealed the reporter had used ChatGPT to write a portion of the story.
Following the frenzy, Microsoft, who had partnered with OpenAI in 2019, built a version of its Bing search engine powered by ChatGPT. Meanwhile, business leaders took a sudden interest in how this technology could improve profits.
Chasing ChatGPT
Researchers and tech companies responded to the ChatGPT moment by showing their own capabilities with large language models.
In February 2023, Cohere introduced the beta version of its summarization product. The new endpoint, built on a large language model customized specifically for summarization, allowed users to enter up to 18-20 pages of text to summarize, which was considerably more than users could summarize through ChatGPT or directly through GPT-3.
A week later, Google introduced Bard, its own LLM-backed chatbot. The event announcing Bard pre-empted Microsoft and OpenAI’s first public demonstration of a new, ChatGPT-powered Bing search engine, news of which had reached publications in January.
Meta rounded out the month when it introduced LLaMA (Large Language Model Meta AI). LLaMA wasn’t a direct duplication of GPT-3 (Meta AI had introduced their direct GPT-3 competitor, OPT-175B, in May of 2020). Instead, the LLaMA project aimed to enable the research community with powerful large language models of a manageable size. LLaMA came in four size varieties, the largest of which had 65 billion parameters—which was still barely more than a third of the size of GPT-3.
In April, DataBricks released Dolly 2.0. Databricks CEO Ali Ghodsi told Bloomberg that the open-sourced LLM replicated a lot of the functionality of “these existing other models,” a not-so-subtle wink to GPT-3. In the same interview, Ghodsi noted that his company chose the name “Dolly” in honor of the cloned sheep, and because it sounded a bit like Dall-E, another prominent model from OpenAI.
The age of giant LLMs is already over?
Shortly after OpenAI released GPT-4, OpenAI CEO Sam Altman told a crowd at the Massachusetts Institute of Technology that he thought the era of “giant, giant” models was over. The strategy of throwing ever more text at ever more neurons had reached a point of diminishing returns. Among other challenges, he said, OpenAI was bumping up against the physical limits of how many data centers the company owned or could build.
“We’ll make them better in other ways,” he told the crowd.
Altman isn’t alone. In the same piece, Wired cited agreement from Nick Frosst, a cofounder at Cohere.
The future of LLMs
If the future of LLMs isn’t about being bigger, then what is it about? It’s too early to say for certain, but the answer may be specialization, data curation, and distillation.
While the largest LLMs yield results that can look like magic at first glance, the value of their responses diminishes as their importance increases. Imagine a bank deploying a GPT model to handle customer inquiries and it hallucinating a balance.
Machine learning practitioners can minimize the risk of off-target responses by creating a specialized version of the model with targeted pre-training and fine-tuning. That’s where data curation comes in. By building a data set of likely prompts and high-quality responses, practitioners can train the model to answer the right questions in the right way. They can use additional software layers to keep their custom LLM from responding to prompts outside of its core focus.
However, LLMs will still be very expensive. Running hundreds of billions—or even trillions—of calculations to answer a question adds up. That’s where distillation comes in. Researchers at Snorkel AI pioneered work that has shown that smaller, specialized large language models focussed on specific tasks or domains can be made more effective than their behemoth siblings on the same tasks.
Regardless of what the next chapter of LLMs looks like, there will be a next chapter. While LLM projects right now are a novelty, they will soon work their way into enterprise deployments; their value is too obvious to ignore.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: https://twitter.com/InsideBigData1
Join us on LinkedIn: https://www.linkedin.com/company/insidebigdata/
Join us on Facebook: https://www.facebook.com/insideBIGDATANOW



Speak Your Mind