About a year ago at Arvato, we faced a number of challenges that hampered our development and deployment processes, all of which stemmed from the monolithic architecture we had in place at the time. In fact, the team lived in a state of fear for the next deployment – the process had become difficult and involved, to the degree that deploying new features was as big a challenge as developing them in the first place. Deployment was also tremendously time-consuming, taking half a day to complete even when everything went as it should.
Hoping to alleviate these issues, we set out on a mission to build a new, streamlined infrastructure. More specifically, our goals were to create a well-defined process for deploying any infrastructure we needed, to achieve generic infrastructure elements, to have a reproducible environment for all areas and layers, and to make sure the process wouldn’t be painful for anyone involved.
To accomplish these goals, we began to explore a possible implementation of a microservices-based architecture. Because our work within Arvato is in the financial services space – helping e-commerce businesses detect and prevent consumer fraud – we also pursued this new architecture while conscious of the need to have fully effective security and data handling measures in place. Doing so would best serve our customers’ requirements and meet the very strict data protection laws regulating our industry.
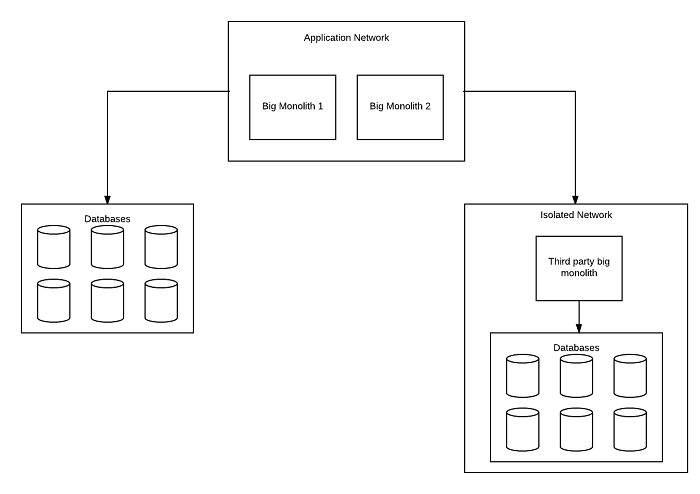
As you can see in this diagram, our previously existing architecture was a very traditional one, including an application space, monolithic apps, segmented databases, and third-party software that was mysterious and untrusted within our organization.
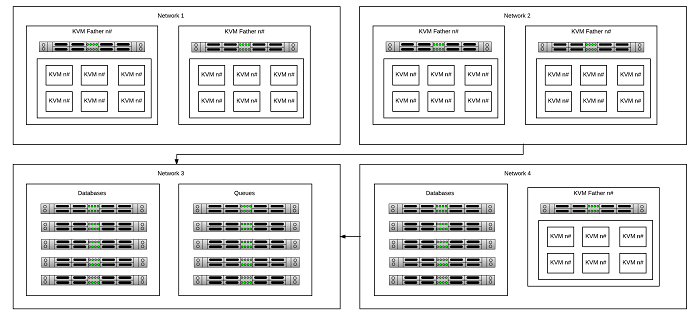
A look at our infrastructure at the time shows a complex environment, with a high number of KVMs in use. To make matters more complicated, each of these KVMs was unique – meaning that they were not reproducible and were quite difficult to maintain.
Working with a microservices-based infrastructure was a first for the company, and a completely new challenge for our team. To begin implementing this new infrastructure, we began by bootstrapping the old environment, setting up an orchestrator and throwing away some components that hadn’t worked well for us. But we also adjusted our whole process (including our build pipelines), and got the servers for the new infrastructure prepared and running. We then went to work on making a prototype that was highly-flexible and suited for complete integration with Docker and our new toolchain.
One thing we learned early on about microservices: the perfect microservice is completely decoupled. It doesn’t know anything. It doesn’t know who talks to it, whom it talks to, where it is, or who it is. It doesn’t necessarily depend on a queue, and shouldn’t (it took building a queue for us to learn this). We don’t even know where a microservice is, unless we look it up in the infrastructure.
From the initial prototype created last year, this new infrastructure has grown very quickly. With Docker in production and in use since the prototype, we were able to set up one-click deployments and reach our goal of having reproducible environments. We did face a number of issues while migrating old services, which led us to discover that the node package rc is a very advantageous config package to Dockerize.
In changing our stack in support of our new infrastructure, we utilized GitLab as a repository for solutions. Docker, as mentioned, has enabled us to achieve our goals as far as reproducibility, genericness, and trackability are concerned. We tapped Rancher as our orchestration solution, because it was the most native experience for our developers and allowed us for a rapid translation of our legacy infrastructure. Instana serves us as a powerful Application performance monitoring and microservice monitoring framework capable of useful automation, providing us the deep insight into the System we need. Kibana, Elasticsearch, and Logstash also have key parts. To meet our unique-but-critical regulatory needs, NeuVector plays an important role here as an automated solution for creating firewall rules, and to capably handle security within the complexity of the microservices environment.
Now looking at our new microservices-based infrastructure shows that our databases are the same and the basic design is very similar. What’s changed is that everything is now a microservice, with the exception of some legacy monoliths that are being worked on and necessary third-party apps that can’t be altered.
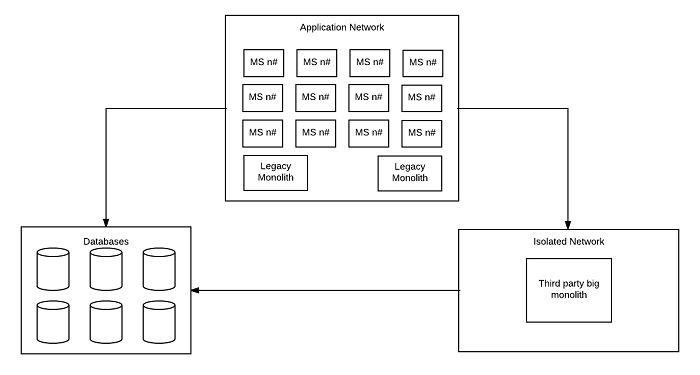
Previously, we relied on network segmentation, using four segmented networks to meet the necessary data protection regulations. Due to these regulations, we have certain data we are not allowed to combine, and we must maintain strict control over which applications can access which other applications.
Today, we’re able to meet our regulatory needs while utilizing a much simpler and more maintainable microservices-based infrastructure, which is more secure than before, since environmental constraints can be more strict, thanks to docker and immutable infrastructure. Now only two networks are used: the database network and the application network.
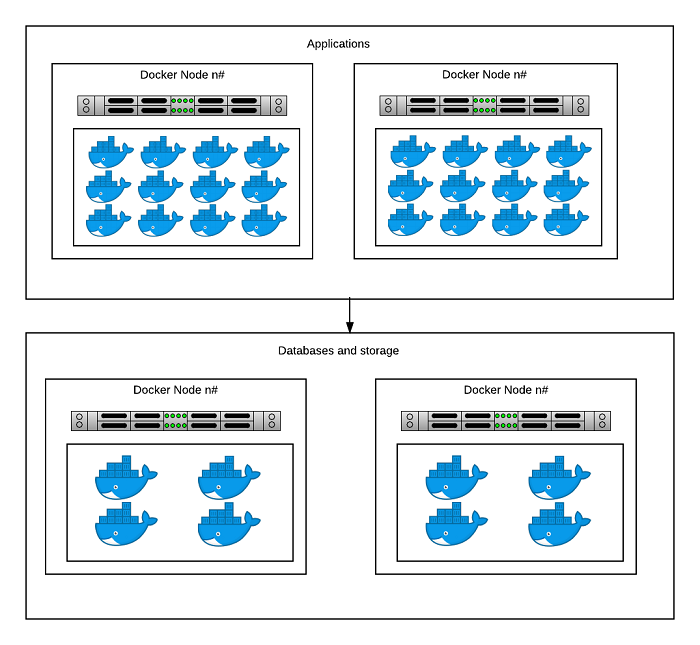
Separating the database is not required, but is done in this case in order to provide dedicated service for high performance. This setup also offers generic data storage, which isn’t often needed in the realm of Docker but can be useful for serving legacy needs. At the same time, special services like databases demand special treatment; you want to protect them more, because this is where your data lies. There are also examples where you might have special hardware requirements you want to address, such as having an NVMe disk installed, or having a special CPU architecture installed, like IBM’s POWER8. Putting a database into Docker offers several advantages: it makes the database reproducible, generic, and easier to scale (if done correctly, of course). We used CockroachDB to meet these needs.
From here, our final steps in preparing for production included readying our security, logging, and monitoring capabilities. Doing so required gaining insight into our traffic and how our application behaves, not just for the purpose of security but also to help with troubleshooting issues. Keep in mind that within a microservices framework, it’s critical to be able to understand which services talk to one another. Here Docker generates another benefit by providing immutability, which allows for strict access rules controlling communication internally between services or externally with the internet.
For security automation, we rely heavily on NeuVector to deal with the complexity of the container environment. Because manual firewall rules are far too vast to manage in microservices systems, an automated approach to security is necessary (NeuVector provides the advantage that these rules are automatically created for you). This strategy also helps handling common vulnerabilities and exposures (CVEs), which are published when a fix for an issue becomes available. When an image is in production that needs a CVE fix, NeuVector automatically applies the fix, by triggering our CI Pipeline which redeploys these vulnerable images with patched ones.
One more point on the topic: the container security software also has systems intelligence within the containerized environment, further upping security. Immutability allows for detailed behavioral analysis of how systems act before and after becoming compromised, such that usual traffic within the environment is white-listed, and any anomalies are immediately recognized and disallowed from doing harm. These security features are a perfect extension to our in-house systems intelligence and provide tremendous support in achieving the data security our organization is legally required to maintain.
With the new microservices infrastructure, our epic cycle that would take 1-2 months has been accelerated to 1-2 weeks. Our small feature cycle took the time of a normal sprint before. Now small features can be pushed out as soon as they’re ready, meaning that customers aren’t left waiting for important updates to be deployed. Previously, staging couldn’t be done on demand but was deployed nightly because it was too complicated – and we had a big preparation time before each deployment because of the fear of what could happen. This is called fear driven business, which ultimately leads to bad software: You suffer from paralysis and decisions made upon fear will harm you more than they help you. Now, staging happens on demand, and no prep time is necessary. Our previously troublesome deployment process has been rendered straightforward, and both development and deployment are much more rapid.
In the course of implementing these solutions, we learned a few important things. We discovered that the main challenge in making these changes was to win support for them within the company culture – systems and processes aren’t as emotional about changes as people are. When others see that the business case makes sense and generates benefits for them, they’re going to accept it and want to work on it with you. Shortly: Acceptance begins where people start to live and feel the benefits. Be sure to recognize the cultural shift that changes like this bring, and make people want the new solutions rather than simply enforcing them. In fact, one of our developers said that he hated operations so much, that automation was not an alternative but the solution. In our team’s experience, if you’re able to successfully navigate the cultural shift involved, going to the trouble of implementing a highly automated microservices-based architecture pays dividends, as Docker can accelerate your pace by orders of magnitude.
About the Authors
 Tobias Gurtzick is a Security Architect at Arvato Infoscore, a global financial services subsidiary of Bertelsmann that helps e-commerce companies detect and prevent consumer fraud.
Tobias Gurtzick is a Security Architect at Arvato Infoscore, a global financial services subsidiary of Bertelsmann that helps e-commerce companies detect and prevent consumer fraud.
 Dr. Sayf Al-Sefou is CTO at Arvato Infoscore.
Dr. Sayf Al-Sefou is CTO at Arvato Infoscore.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind