
In this edition of Industry Perspectives, HPE explores how reducing the cycle time for inferencing helps to accelerate time to market for deep learning and AI insights and solutions.
Artificial intelligence (AI), with an emphasis on deep learning (DL), has fuelled the growth of innovation across a broad range of use cases including autonomous vehicles (AV), fraud detection, speech recognition, and predictive medicine. NVIDIA® has led the industry with GPU acceleration advancements that allow data scientists to build increasingly more complex models with huge data training sets—in the petascale range—putting greater focus on the underlying infrastructure required to create a balanced solution.
The deep learning dataflow can be complex, with multiple steps required to transform and manipulate data for use with DL models.
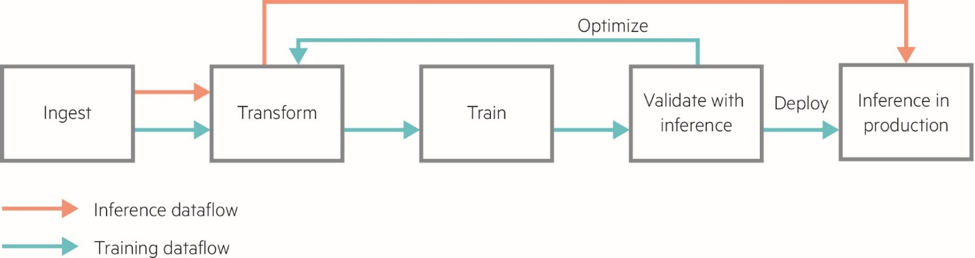
Data is ingested and transformed through cleansing and pre-processing techniques to be usable as part of a data set to train a DL model. Critically, after a model is trained, it must be validated to ensure it meets production inference requirements before deployment. To ensure the trained model meets accuracy, reliability, and other quality and performance requirements, the model must be tested in a batch inferencing or simulated environment. For example, a model for autonomous vehicles designed to recognize pedestrians must be tested to ensure it will recognize them in varying lighting conditions. If the model fails in the validation stage, it must be further trained. This is an iterative phase of model development and is analogous to many continuous integration workflows that exist in other disciplines of software development.
HPE partnered with engineers from WekaIO, NVIDIA and Mellanox to examine the effects of storage on the deep learning development cycle using a simple system consisting of a single HPE Apollo 6500 Gen10 system with eight NVIDIA Tesla V100 SXM2 16 GB GPUs, WekaIO Matrix flash-optimized parallel file system, and high speed Mellanox 100 Gb EDR InfiniBand network. Since this benchmarking was designed to provide a comparison of external storage and local storage behaviour, only a single NVMe SSD was used in the Apollo 6500. The WekaIO Matrix storage cluster used a total of 32 NVMe SSDs in 8 HPE ProLiant DL360 Gen10 servers. Deep Learning benchmarks used to test training and inferencing performance were ResNet152, VGG16, ResNet50, GoogleNet, and AlexNetOWT.
Given the relatively small scale of these benchmarks, it was easy to saturate GPU compute resources while easily addressing the I/O demands of the various benchmarks. So while these tests didn’t stress storage greatly, they did show that WekaIO Matrix was essentially equivalent to the local file system in most tests. These results show that the WekaIO Matrix file system combined with Mellanox EDR networking should minimize data locality as an issue for Deep Learning training. Local data copies would not have to be created for training, reducing overall complexity, and this configuration bodes well for production environments that would have much larger datasets, GPU clusters and a scaled-out environment.
Inferencing is not often emphasized or considered as much as training when developing infrastructure planning. The assumption is that training requirements will be sufficient for inferencing usage. However, our benchmarks show that the I/O demands of the single HPE Apollo 6500 with NVIDIA Tesla GPUs can extend well beyond the capability of the local NVMe drive, and that I/O can definitely be a bottleneck. The local drive became I/O bound when the benchmarks scale to 4 GPUs and beyond. WekaIO clearly outstrips the local NVMe drive, doubling the number of images per second with 8 GPUs in the ResNet50 and GoogleNet benchmarks.
Model validation, the phase within the AI development cycle where a trained deep learning model is tested for accuracy, performance and reliability, is based on testing the inferencing capabilities of the trained model. As such, reducing the cycle time for inferencing helps to accelerate time to market, as it reduces the development time in tuning the neural network to meet production requirements. Our testing clearly shows that increased storage throughput, over 6 GB/sec, can be used during inferencing.
Inferencing is not only used during the development cycle, but also to further enhance deep learning models. Consider that autonomous vehicle manufacturers need to drive their car millions of miles to ensure their deep learning models perform properly. This is impractical to do physically. However, presenting models with new data via inferencing allows ongoing testing and refinement of their models without actual physical vehicle use, saving time and money.
As with many things in life, AI infrastructure needs to be balanced for effective overall performance. For example, fast GPUs can’t be used to their full potential with slow networking and storage. And when planning for AI infrastructure, inference needs should be considered as well as training needs.
Read about the benchmarks and their results in the white paper, Accelerate Time to Value and AI Insights.
To learn more about NVIDIA, see here.
To learn more about WekaIO Matrix, see here.
HPE Deep Learning Cookbook: benchmarking results to inform decisions about hardware and software stacks for different workloads.



Speak Your Mind