 In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
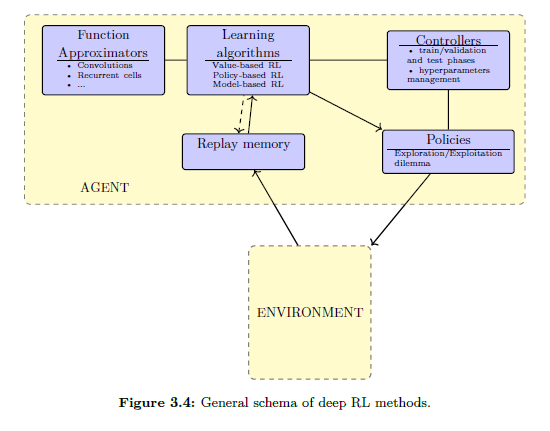
An Introduction to Deep Reinforcement Learning
 Deep reinforcement learning is the combination of reinforcement learning (RL) and deep learning. This field of research has been able to solve a wide range of complex decision-making tasks that were previously out of reach for a machine. Thus, deep RL opens up many new applications in domains such as healthcare, robotics, smart grids, finance, and many more. This paper provides an introduction to deep reinforcement learning models, algorithms and techniques. Particular focus is on the aspects related to generalization and how deep RL can be used for practical applications. The reader is assumed to be familiar with basic machine learning concepts.
Deep reinforcement learning is the combination of reinforcement learning (RL) and deep learning. This field of research has been able to solve a wide range of complex decision-making tasks that were previously out of reach for a machine. Thus, deep RL opens up many new applications in domains such as healthcare, robotics, smart grids, finance, and many more. This paper provides an introduction to deep reinforcement learning models, algorithms and techniques. Particular focus is on the aspects related to generalization and how deep RL can be used for practical applications. The reader is assumed to be familiar with basic machine learning concepts.
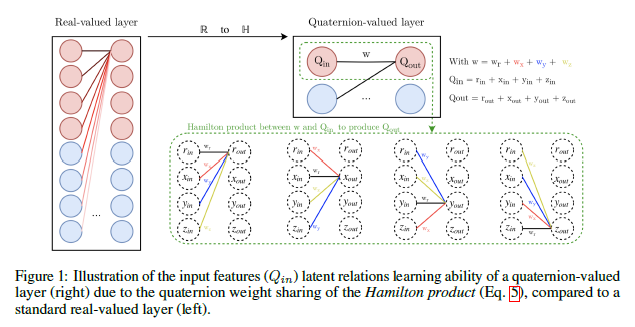
Quaternion Recurrent Neural Networks
Recurrent neural networks (RNNs) are powerful architectures to model sequential data, due to their capability to learn short and long-term dependencies between the basic elements of a sequence. Nonetheless, popular tasks such as speech or images recognition, involve multi-dimensional input features that are characterized by strong internal dependencies between the dimensions of the input vector. This paper proposes a novel quaternion recurrent neural network (QRNN), alongside with a quaternion long-short term memory neural network (QLSTM), that take into account both the external relations and these internal structural dependencies with the quaternion algebra. Visit the GitHub repo for this paper: Pytorch-Quaternion-Neural-Networks.
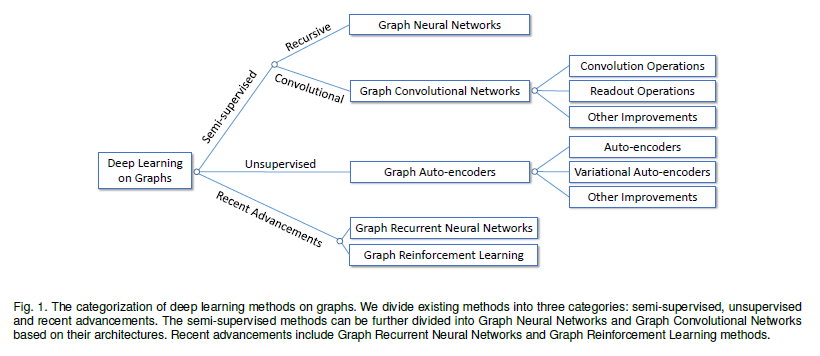
Deep Learning on Graphs: A Survey
Deep learning has been shown successful in a number of domains, ranging from acoustics, images to natural language processing. However, applying deep learning to the ubiquitous graph data is non-trivial because of the unique characteristics of graphs. Recently, a significant amount of research efforts have been devoted to this area, greatly advancing graph analyzing techniques. This survey provide a comprehensive review of different kinds of deep learning methods applied to graphs.
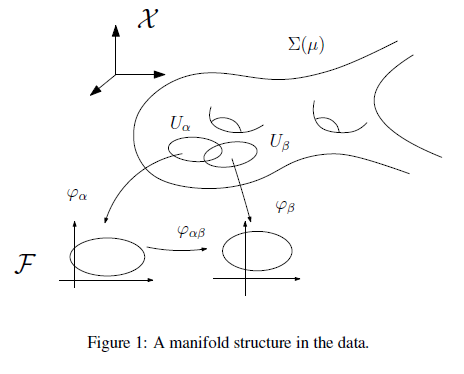
Geometric Understanding of Deep Learning
Deep learning is the mainstream technique for many machine learning tasks, including image recognition, machine translation, speech recognition, and so on. It has outperformed conventional methods in various fields and achieved great successes. Unfortunately, the understanding on how it works remains unclear. It has the central importance to lay down the theoretic foundation for deep learning. This paper gives a geometric view to understand deep learning: showing that the fundamental principle attributing to the success is the manifold structure in data, namely natural high dimensional data concentrates close to a low-dimensional manifold, deep learning learns the manifold and the probability distribution on it.
Sign up for the free insideBIGDATA newsletter.



Hi Daniel,
First of all, thank you for writing up these articles on the best of Arxiv, I follow these for some time and find most of the papers you post here interesting/relevant for my own research. Second, I wanted to ask you what is your strategy when picking papers for this article. Arxiv is flooded with (maybe) hundreds of papers a week and it is impossible for me to keep up with the good research out there.
Thank you,
Sergio
Hello Sergio, thank you for your comment, I’m glad you appreciate this regular feature. As a researcher in machine learning in a previous life, I simply pick the arXiv papers that I feel are the most important (totally subjective). I believe they’re all relevant to anyone seeking to move forward in the field. –Daniel