
Barbara Murphy, VP of Marketing at WekaIO, explores the path of artificial intelligence from the fringe to mainstream business practices. Find out what is driving AI growth.

Barbara Murphy, VP of Marketing, WekaIO
According to a recent Gartner survey, artificial intelligence (AI) learning has moved from a specialized field into mainstream business use with 37 percent of respondents reporting their enterprises either had deployed AI or would do so shortly. The high growth is being driven by repetitive applications that traditionally relied on human interpretation. AI cuts across many industries including healthcare (MRI, pathology, predictive medicine) to security (facial recognition, fraud detection), manufacturing (predictive maintenance, QA analysis, visual inspection, autonomous driving), agriculture (crop management, animal husbandry), to sales improvements (conversation intelligence, purchasing intent), to mention a few. The challenge with machine learning is the sheer size of the data sets needed to train and develop models, and the winners will be the companies that have the best data models. It was beautifully captured by Andrew Ng in the following quote: “AI is akin to building a rocket ship. You need a huge engine and a lot of fuel. The rocket engine is the learning algorithms, but the fuel is the huge amounts of data we can feed to these algorithms.”
Huge amounts of data translates to huge amounts of storage, and AI/machine learning workloads require a solution which can cost effectively store and scale as the data grows. In addition, the workloads demand very high IOPS and/or throughput and low-latency performance to efficiently fuel the AI rocket engine. Given the size, scale and performance requirements, AI infrastructure closely resembles the high-performance computing (HPC) market, the early pioneer in computing at scale. Data sets frequently reach multi petabyte scale while performance demands will saturate the network infrastructure.
How to Fuel a Rocket Ship
Just like the race to the moon in the 1960’s, AI is a race to the answer, and the winners will get there first. Just look at the autonomous vehicle market to see how only a few vendors have pulled ahead in the race while most have not seen the light of day. The AI rocket engine (the learning algorithm) requires massive compute power, typically delivered on high performance GPU servers that scale out and work together to quickly develop the training model. This environment requires the use of a global file systems to share the massive data sets across the many GPU servers. The challenge with legacy shared storage systems (typically NAS) is that they were never designed for this workload.
A data-hungry GPU server can easily process thousands of images per second while training a model. NVMe technology is the most performant solution to deliver the necessary throughput performance but is costly to scale. As companies go into production with AI, data sets can grow to tens and even hundreds of petabytes and will exceed the capacity of traditional storage appliances. With a 10x difference between traditional disk technology and NVMe an all NVMe solution is impractical at this scale. To achieve scalability and performance while simultaneously controlling costs require a storage system that accommodates separate tiers of storage for hot (working) data and cold data, utilizing object storage for the colder data and NVMe for performance. At a ratio of approximately 10 percent NVMe to 90 percent object storage provides an ideal balance in performance/capacity and dramatically lowers the total cost of ownership.
Introducing the HPE AI Data Node
Hewlett Packard Enterprise, in partnership with WekaIO and Scality, have developed a package of storage solutions tailored to HPC and AI workloads using WekaIO Matrix parallel file system and Scality Ring object storage deployed on HPE ProLiant and HPE Apollo servers. With this combined solution, customers can have the highest performance, petabyte-scale storage solution with integrated data lifecycle management, providing tiering management by the file system and a single namespace.
This hybrid approach (figure 1) combines both tier elements into a scalable cluster, utilizing storage servers, which are optimized for both NVMe flash capacity and scale-out bulk data storage. This is the concept behind the HPE AI Data Node, based on the HPE Apollo 4200 Gen10 storage server. HPE AI Data Node offers a building block for production AI that can scale linearly in performance and capacity.
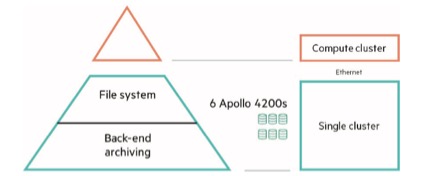
Figure 1: Hybrid architecture for tiered AI storage. (Graph: WekaIO)
This hybrid architecture provides administrative simplicity, eliminating the need for multiple data lakes, data archiving software or a complex hierarchical storage system. The intelligence of the matrix file system integrates the object back-end archiving tier into one simplified infrastructure, which contains both great performance with NVMe flash storage, great scaling and great cost dynamics leveraging the economics of HDD storage. All data in both tiers is distributed in shards across the entire server cluster for performance, with distributed data protection to provide durability and availability even in the event of an unexpected server fault.
To learn more about the HPE AI Data Node Reference Configuration, see here.
Barbara Murphy is VP of Marketing at WekaIO.



Speak Your Mind