
Below please find an excerpt from a new title, O’Reilly Media’s The Enterprise Big Data Lake: Delivering the Promise of Big Data and Data Science, a new release in the Data Warehousing category by Alex Gorelik.
The Enterprise Data Lake is a go-to resource for CTOs, CDOs, chief analytics officers and their teams, the people charged with extracting the strategic and operational insights from petabytes of data that will ultimately transform their organizations into sooth-seeing, agile businesses. The book charts in painstaking detail how to architect, implement, catalog and govern the modern-day data lake, all while keeping an eye on budget and organizational agility in the short and long terms. It also details use cases in a variety of industries, and provides perspectives from practitioners at Charles Schwab, the University of San Francisco and other organizations.
Over the course of his 30-year career, Alex has solved some of the thorniest data problems at some of the world’s largest enterprises, including Unilever, Google, Royal Caribbean, LinkedIn, Kaiser Permanente, Goldman Sachs, GlaxoSmithKline and Fannie Mae. He is currently the founder of Waterline Data, the holder of two patents on technology that aids the fast and easy discovery of data across the enterprise. Alex also founded two other companies that were acquired by IBM and SAP, and led the adoption of Hadoop as a Distinguished Engineer at IBM and GM at Informatica.
Sensitive Data Management and Access Control
Excerpt from The Enterprise Big Data Lake,” by Alex Gorelick. Published by O’Reilly Media, Inc. Copyright © 2019 Alex Gorelick. All rights reserved. Used with permission.
One of the great worries of data governance teams is how to manage sensitive data. There are numerous industry-specific and country-specific regulations that govern usage and protection of personal or sensitive information, such as the GDPR in Europe, HIPAA in the United States, and PCI internationally. In addition, companies often maintain their own lists of internal “secret” information that must be protected. We refer to any data that is subject to regulatory compliance and access restrictions as sensitive. To manage sensitive data, enterprises have to first catalog it (i.e., find out where it is stored) and then protect it, through either restricting access or masking the data.
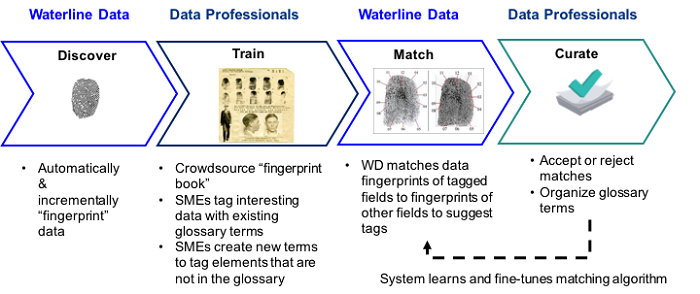
Traditionally, security administrators had to manually protect each field. For example, if a database had a table with a column that contained Social Security numbers (SSNs), the administrator had to figure that out and manually create a rule that allowed access to that field only to authorized users. If for some reason users started putting SSNs in a different field (say, the Notes field), that field would stay unprotected until someone noticed it and created a new rule to protect it. Instead, modern security systems such as Apache Ranger and Cloudera Sentry rely on what’s called tag-based security. Rather than defining data access and data masking policies for specific data sets and fields, these systems define policies for specific tags and then apply these policies to any data sets or fields with those tags.
Automated and manual vetting
Without an automated approach to sensitive data management, new data sets ingested into the data lake cannot be released for use until a human has reviewed them and figured out whether they contain anything sensitive. To drive this process, some companies have tried creating a “quarantine zone” where all new data sets go and stay until they’ve been manually reviewed and blessed for general use. Although the quarantine zone approach makes sense, these companies report significant backups in working their way through quarantined data sets. This is because the process is time- consuming and error prone—a problem that’s often exacerbated by a lack of budget for doing this type of work, because most of the data sets are not immediately being used for any projects. This neglect, unfortunately, leads to a vicious circle. Since the files in the quarantine zone are not accessible to anyone, they are not findable and cannot be used by the analysts, nor can the analysts influence the order of curation.
A much more elegant solution can be achieved by using automated sensitive data detection. Data sets in the quarantine zone can be automatically scanned by the cataloging software and automatically tagged with the type of sensitive data that they contain. Tag-based security can then be applied to automatically restrict access to those files or de-identify sensitive data.
As an additional precaution, instead of making the data sets automatically available, manual vetting can be done on demand. Such a system applies automated tagging and adds the metadata for the data sets to the catalog to make the data sets findable.
Once an analyst finds a data set that they would like to use, this data set is manually curated to verify the correctness of the tags, and any sensitive data can be de-identified. This way, while all the data sets are findable and available, the limited resources of the data steward group doing curation are spent on useful files and funded projects.
Finally, as data sets are provisioned, data sovereignty laws and other regulations can be respected. For example, if an analyst in the UK asks for access to German data, instead of shipping the data over to the UK, they may be granted permission to access the local German data lake.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind