
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
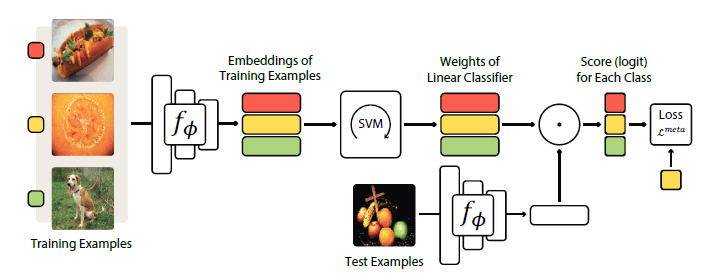
Meta-Learning with Differentiable Convex Optimization

Many meta-learning approaches for few-shot learning rely on simple base learners such as nearest-neighbor classifiers. However, even in the few-shot regime, discriminatively trained linear predictors can offer better generalization. This paper proposes to use these predictors as base learners to learn representations for few-shot learning and show they offer better trade-offs between feature size and performance across a range of few-shot recognition benchmarks. The objective is to learn feature embeddings that generalize well under a linear classification rule for novel categories. To efficiently solve the objective, the authors exploit two properties of linear classifiers: implicit differentiation of the optimality conditions of the convex problem and the dual formulation of the optimization problem. This allows the use of high-dimensional embeddings with improved generalization at a modest increase in computational overhead. The code for this paper can be found HERE.
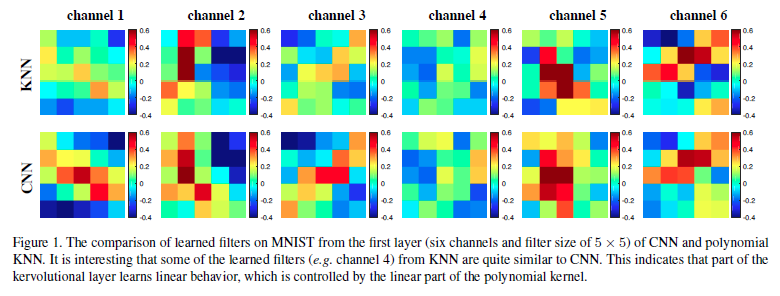
Convolutional neural networks (CNNs) have enabled the state-of-the-art performance in many computer vision tasks. However, little effort has been devoted to establishing convolution in non-linear space. Existing works mainly leverage on the activation layers, which can only provide point-wise non-linearity. To solve this problem, a new operation, kervolution (kernel convolution), is introduced to approximate complex behaviors of human perception systems leveraging on the kernel trick. It generalizes convolution, enhances the model capacity, and captures higher order interactions of features, via patch-wise kernel functions, but without introducing additional parameters.
Fashion++: Minimal Edits for Outfit Improvement
Given an outfit, what small changes would most improve its fashionability? This question presents an intriguing new vision challenge. This paper introduces Fashion++, an approach that proposes minimal adjustments to a full-body clothing outfit that will have maximal impact on its fashionability. The model consists of a deep image generation neural network that learns to synthesize clothing conditioned on learned per-garment encodings. The latent encodings are explicitly factorized according to shape and texture, thereby allowing direct edits for both fit/presentation and color/patterns/material, respectively. It is shown how to bootstrap Web photos to automatically train a fashionability model, and develop an activation maximization-style approach to transform the input image into its more fashionable self.

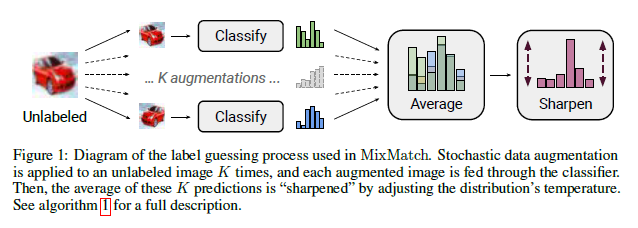
MixMatch: A Holistic Approach to Semi-Supervised Learning
Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. This paper unifies the current dominant approaches for semi-supervised learning to produce a new algorithm, MixMatch, that works by guessing low-entropy labels for data-augmented unlabeled examples and mixing labeled and unlabeled data using MixUp. It’s shown that MixMatch obtains state-of-the-art results by a large margin across many datasets and labeled data amounts. The code for this paper can be found HERE.
Real numbers, data science and chaos: How to fit any dataset with a single parameter
This paper shows how any data set of any modality (time-series, images, sound…) can be approximated by a well-behaved (continuous, differentiable…) scalar function with a single real-valued parameter. Building upon elementary concepts from chaos theory, the paper adopts a pedagogical approach demonstrating how to adjust this parameter in order to achieve arbitrary precision fit to all samples of the data. Targeting an audience of data scientists with a taste for the curious and unusual, the results presented here expand on previous similar observations regarding expressiveness power and generalization of machine learning models.

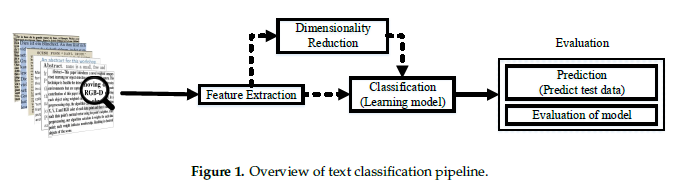
Text Classification Algorithms: A Survey
In recent years, there has been an exponential growth in the number of complex documents and texts that require a deeper understanding of machine learning methods to be able to accurately classify texts in many applications. Many machine learning approaches have achieved surpassing results in natural language processing. The success of these learning algorithms relies on their capacity to understand complex models and non-linear relationships within data. However, finding suitable structures, architectures, and techniques for text classification is a challenge for researchers. In this paper, a brief overview of text classification algorithms is discussed. This overview covers different text feature extractions, dimensionality reduction methods, existing algorithms and techniques, and evaluations methods. Finally, the limitations of each technique and their application in the real-world problem are discussed. The code for this paper can be found HERE.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind