In this sponsored post, Carlos Pazos, Product Marketing Manager at SparkCognition, explores the expanding requirements of machine leaerning tools today, and highlights SparkCognition’s “Darwin,” a machine learning tool designed to automate the building and deployment of machine learning models at scale.

While machine learning has enabled massive advancements across industries, it requires significant development and maintenance efforts from data science teams. The next evolution in human intelligence is automating the creation of machine learning models to not follow predefined formulas, but rather adapt and evolve according to the problem’s data. The same way a tailored suit feels and looks different from generic options, tailored models perform differently than pre-established boxed algorithms because they are custom-fitted to your data.
To answer this need, SparkCognition has developed Darwin, a machine learning product that automates the building and deployment of models at scale. Darwin uses a patented approach based on neuroevolution that custom builds model architectures to ensure the best fit for the problem at hand. Rather than simply choosing the best performer from a predefined list of algorithms, Darwin uses a blend of evolutionary and deep learning methods to iteratively find the most optimal model tailored to your data. This automated model building process effectively creates unique solutions that correctly and accurately generate predictions for your unique data problems.
How Does Darwin Work?
Darwin automates three major steps in the data science process: cleaning, feature generation, and the construction of either a supervised or unsupervised model. Each step is performed as a single generation of Darwin’s evolutionary process, which contains dozens of model architecture candidates. At the end of each generation Darwin keeps the best performers, analyzes their architectural characteristics, and spawns a new generation of models based on these features. This way, Darwin automatically generates thousands of models that evolve and improve with each generation to more accurately reflect the relationships in your data.
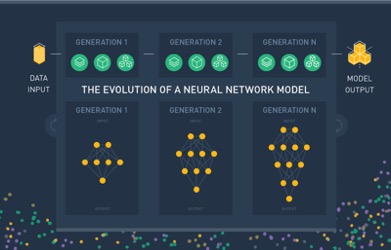
Cleaning
First, Darwin needs to convert data sets into a usable form for algorithmic development. This includes representing categorical data as numeric and extracting features that preserve temporal relationships in date/time information. Data is also scaled to normalize data sets so features can be compared to one another.
Feature Generation
Once data has been cleaned, data scientists often manipulate that data to generate more appropriate features to solve a particular problem. One of the biggest challenges in handling dynamic time series data is determining how to window the time steps for feature generation. Darwin automates this windowing process using one-dimensional convolutional neural networks (CNN). CNNs are a class of deep neural networks that use a type of multilayer perceptions designed to need only minimal preprocessing. The network instead automatically learns the filters that traditionally would need to be engineered by hand.
Darwin begins by analyzing the characteristics of the input dataset and the specified problem, and then applying past knowledge to construct an initial population of machine learning models which are likely to produce accurate predictions on the problem.
Feature Selection and Model Building
Once automated cleaning and feature generation have taken place, the data set is ready to be used to build a model. Through neuroevolution, Darwin is capable of building both supervised learning and normal behavior models. These methods differ in how they work and the problems they solve.
For supervised learning problems, the goal of Darwin is to ingest the cleaned input data and automatically produce a highly optimized machine learning model which can accurately predict a target of interest specified by the user. Darwin accomplishes this using a patented evolutionary algorithm which simultaneously optimizes and compares various machine learning methodologies, most heavily favoring deep neural networks.
Darwin begins by analyzing the characteristics of the input dataset and the specified problem, and then applying past knowledge to construct an initial population of machine learning models which are likely to produce accurate predictions on the problem. Then, traits from the best-performing models are combined to yield even better models over many generations. This ensures a final model that is highly optimized to the specified problem.
In the same way that Darwin uses an evolutionary algorithm to solve supervised problems, it is also capable of identifying relationships in data that drift over time using a technique called normal behavioral modeling. Darwin does normal behavior modeling through an autoencoder, which is a neural network-based approach that performs dimensionality reduction. Autoencoders compress data to reduce the feature set to the smallest size possible, and then decompress it with as little as loss possible.
Like any other neural network, autoencoders have numerous hidden layers, a defined latent space, and different activation functions in their encoding/decoding process. Darwin automates the creation of this network topology, and then performs backpropagation with dropout to reduce the output loss via weight optimization. When deployed in production, the model’s ability to reconstruct data over time helps to identify shifting relationships in data.
Darwin uses this approach to build models that go beyond a traditional “risk index” and can identify anomalous operations and systems failures.
How good is this process? Read Darwin’s Efficacy Reportto learn more.
Carlos Pazos is a Product Marketing Manager at SparkCognition responsible for automated model building and natural language processing solutions.



Speak Your Mind